#详解 τ0-WM:把“会想象未来”的视频世界模型做成机器人策略
论文:τ0-WM: A Unified Video-Action World Model for Robotic Manipulation
作者:Pengfei Zhou, Shengcong Chen, Di Chen, Jiaxu Wang, Rongjun Jin 等
机构:Shanghai Innovation Institute, AGIBOT Finch
时间:2026-05-31
arXiv:<https://arxiv.org/abs/2606.01027>
项目页:<https://finch.agibot.com/research/tau0-wm>
代码与权重:<https://github.com/sii-research/tau-0-wm>,<https://huggingface.co/sii-research/tau-0-wm>
一句话概括:
τ0-WM 想把机器人策略、视频预测、动作评估三件事合进一个统一的 video-action world model:它不只是直接输出动作,还会“想象这个动作会导致什么未来”,再用测试时计算选择或修正动作。
这篇论文很适合放在最近机器人基础模型、VLA、world model、test-time compute 的脉络里看。它的核心不是又训练了一个更大的行为克隆模型,而是试图回答一个更基础的问题:
机器人操作中,模型到底应该只学“现在该做什么”,还是应该同时学“做了之后会发生什么”?
τ0-WM 的答案是后者。
它把模型拆成两个互补接口:
- VAM:Video Action Model
给定多视角观察、语言指令、机器人状态,预测未来视觉 latent 和可执行 action chunk。它像一个“会想象未来的策略模型”。
- ACVS:Action-Conditioned Video Simulator
给定当前观察和一个候选动作,预测这个动作会导致的未来多视角视频和任务进度 reward。它像一个“动作条件下的视频模拟器 / 评估器”。
部署时,τ0-WM 可以先用 VAM 采样多个候选动作,再用轻量一致性分数筛选;如果候选动作看起来不可靠,就调用 ACVS 模拟未来、预测任务进度,再反过来修正动作。
这就是论文标题里 Unified Video-Action World Model 的含义:不是单独做 policy,不是单独做 video prediction,也不是单独做 reward model,而是把三者塞进同一个未来预测框架。
#1. 这篇论文想解决什么问题?
机器人操作的难点在于,它不是静态分类问题。
机器人要做的是:
- 看到当前场景;
- 理解语言指令;
- 选择一段连续动作;
- 这些动作会改变物体位置、接触关系和场景状态;
- 如果动作错了,可能碰撞、滑落、没插进去、拉链没拉好、盖子没盖上;
- 机器人还要根据新状态继续闭环调整。
所以一个好的机器人策略,最好不只是会从图像映射到动作:
它还应该具备某种“未来感”:
这和人类很像。你拿一个装水的玻璃杯时,不是盲目伸手,而是会下意识模拟:
- 手抓太松会不会滑?
- 碰到杯沿会不会洒?
- 这个角度会不会撞到旁边的东西?
τ0-WM 就是想给机器人一个类似的机制:
先提出动作,再想象后果,必要时修正动作。
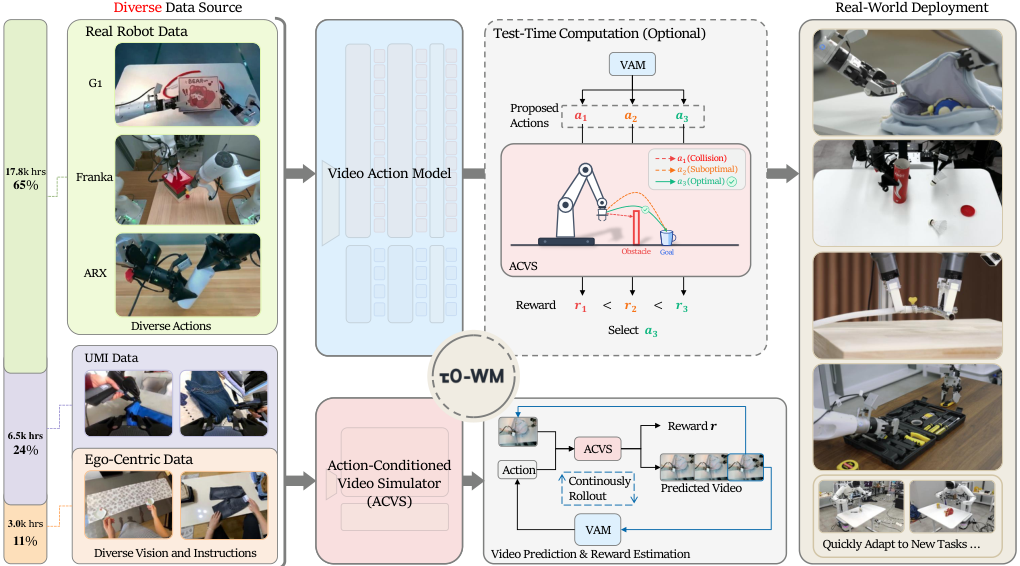
Fig. 1 里其实已经把整篇论文讲完了:左边是数据来源,中间是 VAM 和 ACVS,右边是机器人真实部署。测试时,系统会生成多个候选动作 ,用 ACVS 想象它们的未来,比如 会碰撞, 次优, 最好,于是选择或修正到更好的动作。
#2. 为什么普通行为克隆不够?
很多机器人策略可以看成行为克隆:给模型看人类或机器人示范,让它学:
其中:
- :当前视觉观察;
- :语言指令;
- :机器人自身状态;
- :要执行的动作。
行为克隆的问题是,它主要学“专家在这个状态下做了什么”。但它不一定真正知道:
- 动作执行后场景会怎么变化;
- 某个动作为什么好;
- 某个动作是否只是看起来合理但会导致失败;
- 当前候选动作是否处在模型训练分布内;
- 如果采样出的动作质量不高,应该怎么修正。
这在长程操作里尤其明显。
比如“把羽毛球筒里的球放好并盖上盖子”,它不是一个单步抓取问题,而是一串细粒度动作:对准、抓取、放入、调整位置、合盖。某一步稍微偏一点,后面就会失败。
纯 feed-forward policy 只能直接吐动作。τ0-WM 想让 policy 多一层能力:
输出动作的同时,学习未来视觉动态;评估动作时,可以显式想象动作后果。
#3. 论文的核心结构:一个 backbone,两个接口
τ0-WM 的系统可以用一句话描述:
以共享视频扩散 backbone 为核心,构建一个“会出动作”的 VAM 和一个“会评估动作后果”的 ACVS。
#3.1 VAM:策略接口
VAM 的输入是:
输出是:
也就是:
- 未来视频 latent ;
- 一段连续动作 chunk 。
它回答的问题是:
现在看到这个场景、听到这个指令,机器人应该做什么?同时,它预期未来画面会怎样?
#3.2 ACVS:评估接口
ACVS 的输入是:
输出是:
也就是:
- 在候选动作 条件下的未来视频 latent;
- 对应的 dense reward / task-progress 轨迹。
它回答的问题是:
如果执行这个候选动作,未来会怎样?任务进度会不会变好?
#3.3 两者的差别
| 模块 | 像什么 | 输入 | 输出 | 作用 |
|---|---|---|---|---|
| VAM | 策略 / action proposer | 当前观察、语言、机器人状态 | 未来视频 latent + action chunk | 提出可执行动作 |
| ACVS | 世界模型 / evaluator | 当前观察、语言、候选动作 | 未来视频 latent + reward 轨迹 | 评估动作后果 |
这两者放在一起,就形成了一个 proposal-evaluation-revision loop:
- VAM 先提出动作;
- 用一致性分数检查动作是否靠谱;
- 不靠谱时,用 ACVS 模拟候选动作未来;
- 选择最高进度的 imagined future;
- 再用这个 future condition 重新 query VAM,得到修正动作。
#4. 模型架构:视频生成 backbone + action branch + reward branch
论文的 Fig. 2 展示了 τ0-WM 的两个核心模块。
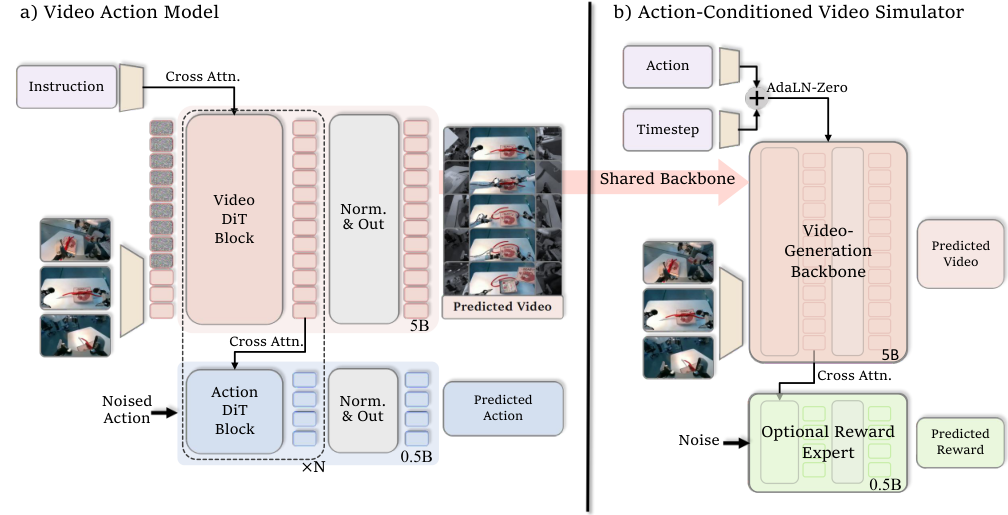
#4.1 VAM 架构
VAM 基于 Wan2.2-TI2V-5B 视频生成模型。
它包含:
- 一个 Wan VAE:把多视角图像编码到 latent;
- 一个 5B 参数的视频 DiT backbone:预测未来视频 latent;
- 一个 0.5B 参数的 Action DiT decoder:预测动作;
- 视频和动作分支之间通过 cross-attention 耦合。
论文说 VAM 总规模约 5.5B 参数。
这里最关键的是:动作分支不是孤立地从图像抽特征出动作,而是会 cross-attend 到视频分支的中间特征。
人话解释:
动作生成不是只看当前图像,而是利用视频 backbone 学到的“未来动态表示”。模型在预测动作时,能借用它对物体运动、接触、未来场景变化的理解。
#4.2 ACVS 架构
ACVS 也复用 Wan VAE 和视频 transformer backbone,但它不生成动作。
它做的是:
- 把当前和历史观察编码成 clean latent context;
- 把未来 latent slot 初始化为 noise;
- 把候选动作编码后注入到 diffusion timestep / AdaLN modulation 里;
- 生成该动作导致的未来视频;
- 可选地通过 reward expert 预测 dense reward。
所以 ACVS 更像一个动作条件视频模拟器:
这和传统 dynamics model 的区别是,它不是预测低维状态,而是在多视角视频 latent 空间里模拟未来。
#5. 数据:27.3K 小时异构交互数据
τ0-WM 的训练数据总量大约 27.3K 小时,由三类数据组成:
- 17.8K 小时真实机器人遥操作数据
来自 AGIBOT-G01、ARX、双臂 Franka 等平台。优点是动作标签最可靠,和真实部署动作空间对齐;缺点是采集贵、覆盖窄。
- 6.5K 小时 UMI-style 示范数据
使用类似 Gen-DAS Gripper 的手持设备采集。优点是更便宜、更丰富;缺点是动作信号和目标机器人动作空间弱对齐。
- 3.0K 小时 egocentric human interaction videos
第一视角人类交互视频。优点是物体、场景、接触模式丰富;缺点是没有机器人可执行动作标签。
这三种数据的角色不一样:
| 数据类型 | 提供什么 | 不提供什么 | 主要价值 |
|---|---|---|---|
| 真实机器人数据 | 可靠 robot action + 多视角视觉 | 覆盖相对窄 | grounding 到可执行动作 |
| UMI-style 数据 | 更广的交互行为 + 弱动作信号 | 和目标机器人动作不完全对齐 | 扩大行为和场景覆盖 |
| 人类第一视角视频 | 丰富视觉动态和长程任务结构 | 无机器人动作标签 | 学物体运动、接触、任务进展 |
论文的关键设计是 modality-specific supervision masks。
人话解释:
每条数据只监督它有的东西。机器人数据有动作,就监督动作和视频;人类视频没动作,就只监督视频动态;失败轨迹有进度信号,就监督 reward / progress。
这避免了硬把所有数据统一成同一种标签格式。
这种设计对机器人基础模型很重要,因为机器人数据天然异构:平台不同、相机不同、动作空间不同、任务不同、标签完整性不同。一个大模型要吃这些数据,就不能假设每条样本都有完整 supervision。
#6. 训练目标:flow matching 同时学视频和动作
VAM 使用 flow matching 同时训练未来视频 latent 和 action chunk。
论文里的损失大致是:
不用被公式吓到。拆成人话:
- :加了噪声的未来视频 latent;
- :加了噪声的动作 chunk;
- 模型要学会把噪声一步步“流”向真实视频和真实动作;
- 视频头预测视频 latent 的 vector field;
- 动作头预测动作的 vector field;
- 两个任务一起训练。
ACVS 也用类似的 flow matching 目标,只是它预测的是:
- 候选动作条件下的未来视频;
- dense reward trajectory。
这里有一个重要细节:ACVS 会显式利用失败数据和恢复轨迹。
这很合理。因为如果只看成功示范,模型可能只知道“好动作长什么样”,但不知道“坏动作会导致什么后果”。而 evaluator 最需要知道的恰恰是:哪些动作会碰撞、失败、退步。
论文把失败轨迹用于 reward / progress 学习,让 ACVS 学会区分:
- 视觉上看起来有动作,但任务没有进展;
- 动作导致错误接触;
- 动作让任务退步;
- 动作真正推动任务完成。
#7. 测试时计算:先筛选,再模拟,再修正
我觉得这篇论文最值得关注的部分是 Test-Time Computation。
很多机器人策略部署时就是一次 forward:输入当前观察,输出动作,执行。τ0-WM 不是这样。它在测试时会多花一点计算,做候选动作选择和修正。

整个流程是:
- VAM 采样 N 个候选 action chunk
- 对每个候选动作计算 RCS:Re-denoising Consistency Score
RCS 的思想是:把候选动作重新加噪,再让模型去 denoise,看它是否容易回到原候选动作。
如果一个候选动作和模型学到的 conditional action manifold 很一致,那么 re-denoising error 小,RCS 高。
论文定义:
人话:
RCS 是一种轻量的“这个动作像不像模型自己会生成的靠谱动作”的分数。
- 如果最高 RCS 超过阈值,就直接执行该动作
这保证了多数情况下不用昂贵模拟,可以保持实时性。
- 如果 RCS 低于阈值,说明候选动作整体不可靠,调用 ACVS
ACVS 对每个候选动作预测:
也就是未来视频和 reward 轨迹。
- 计算 rollout value
论文用:
也就是看这个 imagined rollout 里最高任务进度。
- 选择最有希望的未来,再进行 LAR:Low-quality Action Rectification
注意,τ0-WM 不是直接执行 ACVS 选中的原始候选动作,而是把选中的未来 latent 转成 future condition,再重新 query VAM,生成 refined action chunk。
这一步很有意思。
它不是简单地“多个动作里挑一个”,而是:
用 simulator 想象出更好的未来,再让 policy 朝这个 future condition 重新生成动作。
这更像一个闭环的“想象-修正”机制。
#8. 为什么 RCS + ACVS 这套设计合理?
这套 test-time compute 可以理解成两层过滤。
#第一层:分布内一致性
RCS 问的是:
这个动作像不像 VAM 的条件动作分布里自然会出现的动作?
它关注的是动作是否在模型学到的 action manifold 上。
好处是便宜,不需要完整视频 rollout。
坏处是:一个动作“像专家动作”不代表它在当前几何状态下一定成功。
#第二层:后果评估
ACVS 问的是:
如果真执行这个动作,未来场景会怎样?任务进度会提高吗?
它关注的是动作后果。
这更强,但也更贵。
所以 τ0-WM 的策略是 coarse-to-fine:
- 先用便宜 RCS 过滤;
- 只有不可靠时才用昂贵 ACVS;
- 用 ACVS 的高价值未来反过来修正动作。
这个设计和人类也有点像:
- 日常动作不需要每次都深思熟虑;
- 遇到难状态,才会停下来多想几步,模拟后果,再调整动作。
这也是它和普通 VLA / BC 模型的关键区别:
它把一部分智能放到了 test-time compute,而不是全部压在一次前向预测里。
#9. 实验任务:长程、精细、多阶段操作
论文在四个真实机器人操作任务上评估,任务都不在预训练语料里。

四个任务是:
- Toolbox:把桌上不同工具放到工具箱对应位置;
- School Bag:拉开书包拉链,把物体放进去,再拉上;
- Faucet:把水管接到水龙头上并固定;
- Badminton:收纳羽毛球并盖上盖子。
这些任务的共同点是:
- 多阶段;
- 需要精细几何对齐;
- 涉及接触和物体状态变化;
- 不是单步抓取;
- binary success 之外还有 stepwise task accomplishment progress。
论文使用多个机器人平台:AGIBOT-G01、ARX、双臂 Franka。
这对论文的 claim 很重要,因为它不是只在单一平台、单一任务上验证。
#10. 主结果:τ0-WM 在平均成功率和任务进度上领先
论文对比了 Fast-WAM、π0.5 和 τ0-WM。
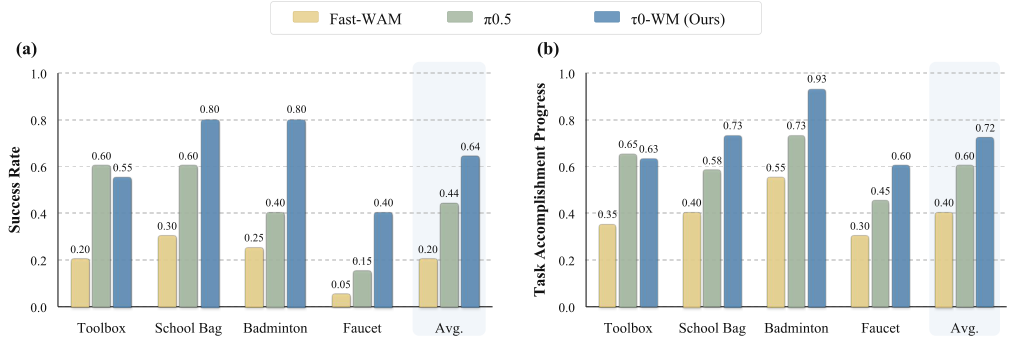
从图里可以看到:
- τ0-WM 平均 success rate 约 0.64;
- π0.5 平均约 0.44;
- Fast-WAM 平均约 0.20。
在 task accomplishment progress 上,τ0-WM 也最高,平均约 0.72。
几个有意思的观察:
- Toolbox 上 π0.5 也很强
说明不是所有任务 τ0-WM 都碾压。π0.5 在某些相对直接的任务上可以竞争。
- School Bag 和 Badminton 上 τ0-WM 提升明显
这类任务更长程、更需要多阶段状态变化,未来预测和纠错可能更有帮助。
- Faucet 对所有方法都很难
τ0-WM 最高,但绝对成功率仍不高。这说明精细插接、固定、对齐仍然是开放难题。
论文还提到一个 binary success metric 看不到的现象:在 Toolbox 任务中,baseline 有时把工具插到位就停了,但插得不深或不稳;τ0-WM 会继续做 push / press 等修正动作,让最终场景更好。
这支持了论文的核心直觉:
显式建模未来视觉结果,可能会让策略更关注最终场景质量,而不是只达到某个中间状态。
#11. 消融一:异构预训练数据真的有用吗?
论文比较了只用 robot data 和使用 Robot+UMI+Ego 的效果。
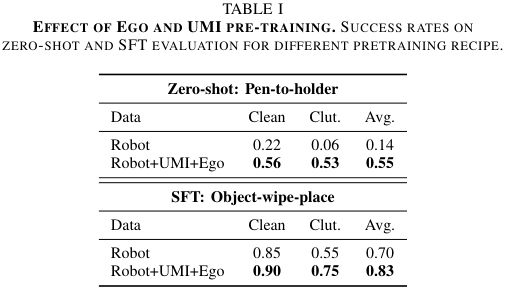
结果:
| 设置 | 只用 Robot | Robot+UMI+Ego | 提升 |
|---|---|---|---|
| Zero-shot Pen-to-holder Avg. | 0.14 | 0.55 | +0.41 |
| SFT Object-wipe-place Avg. | 0.70 | 0.83 | +0.13 |
这说明 UMI 和 egocentric video 的价值主要在于:
- 提供更丰富的视觉交互先验;
- 提升 zero-shot 泛化;
- 在 cluttered setting 下提高鲁棒性;
- 即使没有 robot-compatible action,也能通过 video prediction 帮助模型理解物体动态。
这个结果对机器人基础模型很关键。
因为真实机器人动作数据很贵,如果只能靠 robot teleoperation 扩展,规模会非常受限。τ0-WM 的路径是:
用少量高质量机器人数据 grounding action,用大量弱对齐/无动作视频数据学习视觉动态和交互先验。
这和 VLM/LLM 里的多源数据训练很像:不是每条数据都有完整标签,但每条数据可以贡献它擅长监督的部分。
#12. 消融二:测试时计算真的有用吗?
论文在 Tissue→Box 和 Pen→Box 两个任务上做 test-time computation 消融,且采用严格设置:只允许一次尝试,不允许 retry。
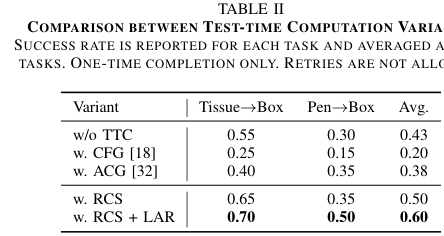
结果:
| 方法 | Tissue→Box | Pen→Box | Avg. |
|---|---|---|---|
| w/o TTC | 0.55 | 0.30 | 0.43 |
| CFG | 0.25 | 0.15 | 0.20 |
| ACG | 0.40 | 0.35 | 0.38 |
| RCS | 0.65 | 0.35 | 0.50 |
| RCS + LAR | 0.70 | 0.50 | 0.60 |
几个结论:
- 只用 RCS 就有提升
平均从 0.43 到 0.50。这说明很多失败不是模型完全不会,而是一次采样选到了次优动作。多采样 + 自一致性筛选能救回来一部分。
- RCS + LAR 提升更明显
平均到 0.60。说明在困难状态下,ACVS 的未来模拟和动作修正确实提供了额外信息。
- CFG / ACG 不如 RCS + LAR
论文认为原因是:CFG / ACG 主要改生成过程,而 τ0-WM 的方法显式评估候选动作及其未来后果。
这个消融是整篇论文最支持“world model for test-time reasoning”的证据。
如果没有这个消融,VAM + video prediction 可能只是一个辅助训练 trick。但 TTC 的结果说明:
未来预测不只是训练时辅助,它能在部署时参与决策。
#13. 部署效率:一个 5.5B 视频-动作模型能实时吗?
这是一个很实际的问题。
论文附录说,真实机器人推理部署在单张 RTX 5090 上。
标准配置下:
- action generation latency 约 220 ms/query;
- 缓存文本表示后约 180 ms/query;
- 加上 torch.compile 等优化可到 140 ms/query,但主文结果为保证一致性没有使用 torch.compile。
动作以 fixed-length action chunks 执行,长度为 30,并采用 receding-horizon closed-loop 方式。
这说明 τ0-WM 不是纯离线 demo,而是有考虑真实部署延迟。
不过也要注意:
- 标准 action-only VAM 可以较快;
- 若频繁调用 ACVS 做多个候选 action rollout,开销会增加;
- 因此论文才采用“RCS 先筛,低质量才调用 ACVS”的 coarse-to-fine 策略。
这也是系统设计上的关键 trade-off:
测试时计算越多,动作选择可能越稳,但延迟越高;所以要把昂贵模拟留给困难状态。
#14. 和 π0 / π0.5、Fast-WAM、Motus 的关系
从相关工作看,τ0-WM 位于几条线的交叉处。
#14.1 和 π0.5 这类 VLA policy 的关系
π0.5 更像一个强大的 vision-language-action policy:输入视觉和语言,输出动作。
τ0-WM 同样输出动作,但它强调:
- joint future video prediction;
- action-conditioned simulator;
- test-time candidate evaluation and rectification。
所以 τ0-WM 不是只要更强 policy,而是希望 policy 具备 world-model 接口。
#14.2 和 Fast-WAM 的关系
Fast-WAM 关注的是把未来预测在推理时移除,以降低延迟。
τ0-WM 的方向几乎相反:
未来预测不只是训练辅助,有时应该在测试时拿出来参与动作选择。
当然,τ0-WM 也支持 action-only deployment,并不是每次都解码视频。
#14.3 和 visual foresight / model-based RL 的关系
早期 visual foresight 就用 action-conditioned video prediction + MPC 来选动作。
τ0-WM 的区别在于:
- 基于大规模视频生成 backbone;
- 结合可执行 action chunk 生成;
- 使用异构机器人、UMI、人类第一视角视频数据;
- 用 reward / progress scoring 做候选评估;
- 将 proposal 和 simulator 放到统一框架中。
可以说它是 visual foresight 在大模型时代的一个新版本。
#15. 这篇论文真正重要的地方:把世界模型从“辅助表征”变成“部署接口”
很多论文会说自己用了 world model,但实际用法可能只是:
- 预测视频作为辅助 loss;
- 训练出更好的 representation;
- 推理时仍然只用 policy head 输出动作。
τ0-WM 更进一步:
world model 在测试时真的参与决策。
这点很重要。
如果视频预测只作为训练辅助,它的价值主要是 representation learning。模型到底是否真的理解未来,很难说。
但如果部署时拿它来评估候选动作,它就变成了 decision-making interface。
换句话说:
- VAM 是 “act”;
- ACVS 是 “imagine and evaluate”;
- LAR 是 “revise”。
这和 LLM Agent 里的 generate-critic-revise 很像。
#16. 从 LLM Agent 角度看 τ0-WM
这篇论文对 LLM Agent / 长轨迹 RL 也有启发。
把机器人操作类比到 Agent:
| 机器人 τ0-WM | LLM Agent |
|---|---|
| 当前多视角观察 | 当前上下文、环境状态、工具返回 |
| 语言指令 | 用户任务 |
| action chunk | 一段工具调用 / 推理步骤 / 代码修改 |
| 未来视频 | 未来环境状态 / 中间执行结果 |
| dense task progress | verifier 分数、测试通过率、子目标完成度 |
| VAM | policy / planner |
| ACVS | world model / process evaluator / verifier |
| RCS | 自一致性 / logprob / 分布内可靠性检查 |
| LAR | 根据 imagined future 重新规划或修正动作 |
τ0-WM 的结构其实很像一种 Agent loop:
- propose several actions;
- cheaply filter candidates;
- simulate or evaluate future;
- select a promising future;
- re-query policy to produce a refined action。
这对长轨迹 Agent 很有启发。
长轨迹任务最大的问题是:直接从当前状态生成完整动作很难,纯离线训练策略也很难覆盖所有状态。更合理的系统可能需要:
- policy 负责提出候选;
- world model / verifier 负责预测后果;
- test-time compute 负责搜索和修正;
- dense progress signal 负责避免只看终局成功失败。
也就是说,未来的强 Agent 可能不是单一 policy,而是:
policy + world model + evaluator + test-time optimizer。
τ0-WM 在机器人场景里给了一个比较具体的版本。
#17. 我对这篇论文的判断
#17.1 优点
第一,问题定义很清楚。
它不是简单做更大 VLA,而是明确把 action generation、future prediction、action evaluation 统一起来。
第二,数据设计合理。
真实机器人数据、UMI-style 数据、人类第一视角视频各有价值,用 modality-specific masks 统一训练,是机器人异构数据扩展的自然路径。
第三,test-time compute 是亮点。
RCS + LAR 让 world model 真正在部署时参与动作选择,而不是只作为 auxiliary loss。
第四,实验任务比简单 pick-and-place 更有挑战。
School Bag、Faucet、Badminton 这些任务包含长程、多阶段和精细接触,更能体现未来预测的价值。
#17.2 局限
第一,ACVS 的 simulator 权重和 TTC 代码目前还未完全开放。
GitHub README 写到 VAM 权重已在 HuggingFace,Simulator 权重和 test-time computation 代码将进一步发布。这意味着外部复现完整 TTC 还需要等。
第二,评估规模仍然有限。
四个主任务很有挑战,但离证明“通用机器人世界模型”还远。需要更大规模、更多场景、更多平台、更多独立复现。
第三,未来模拟的可靠性仍是核心风险。
视频模型可以生成视觉上合理的未来,但是否物理准确、是否能捕捉接触力学、是否能预测细微失败,是机器人 world model 的老问题。
第四,reward / progress label 的构造依赖任务分解。
论文通过 subtask-level progress 和 Monte Carlo propagation 得到 dense reward。这个过程对新任务如何自动化,仍然值得继续研究。
第五,test-time compute 的延迟和可靠性 trade-off 还需要更系统分析。
RCS 便宜,ACVS 昂贵。什么时候调用 ACVS、采样多少候选、如何估计不确定性,都是未来可以深入的方向。
#18. 如果只记住三个关键词
#关键词一:Video-Action Joint Modeling
不要只学动作,也不要只学视频。τ0-WM 把未来视频 latent 和 action chunk 联合建模,让动作生成借用视频动态表征。
#关键词二:Action-Conditioned Simulation
ACVS 不是 policy,而是 evaluator。它接收候选动作,想象未来,预测任务进度,用来判断动作是否值得执行。
#关键词三:Test-Time Proposal–Evaluation–Revision
τ0-WM 的部署不是一次 forward,而是:
这是它最像“world model”的地方。
#19. 一张总表
| 维度 | τ0-WM 的设计 |
|---|---|
| 核心目标 | 统一动作生成、视频预测和动作评估 |
| 主模块 | VAM + ACVS |
| VAM 输入 | 多视角观察、语言指令、机器人状态 |
| VAM 输出 | 未来视频 latent + action chunk |
| ACVS 输入 | 观察历史、语言、候选 action chunk |
| ACVS 输出 | 候选动作导致的未来视频 + dense reward |
| Backbone | Wan2.2-TI2V-5B 视频生成 backbone |
| VAM 参数量 | 约 5.5B,含 5B 视频 backbone 和 0.5B action branch |
| 数据规模 | 27.3K 小时异构交互数据 |
| 数据组成 | 17.8K robot teleoperation + 6.5K UMI-style + 3.0K ego videos |
| 训练技巧 | modality-specific supervision masks |
| 测试时计算 | RCS 筛选 + ACVS rollout + LAR 修正 |
| 主结果 | 平均 success rate 约 0.64,优于 π0.5 和 Fast-WAM |
| 关键消融 | Robot+UMI+Ego zero-shot avg. 0.55 vs Robot-only 0.14 |
| TTC 消融 | RCS+LAR avg. 0.60 vs w/o TTC 0.43 |
| 部署延迟 | RTX 5090 上约 220ms/query,优化后可到 180ms / 140ms |
| 最大启发 | world model 应在测试时参与决策,而不只是训练辅助 |
#20. 总结
τ0-WM 的核心价值不在于“又一个机器人大模型”,而在于它提出了一个更完整的机器人操作接口:
机器人策略应该能提出动作,也应该能想象动作后果,还应该能在执行前评估并修正动作。
这和当前很多 VLA 模型相比,多了一个明显的 world-modeling 维度。
如果把传统行为克隆看成:
那么 τ0-WM 更像:
这条路线对机器人很自然,对 LLM Agent 也很自然。
因为复杂智能体的问题往往不是“下一步 token / action 是什么”这么简单,而是:
- 我有哪些候选行动?
- 它们会导致什么后果?
- 哪个后果更接近目标?
- 如果当前动作不好,怎么修正?
τ0-WM 在机器人操作里给了一个具体答案:用视频世界模型承担未来想象和动作评估,用 test-time compute 把未来预测变成实际决策收益。
当然,它还不是终点。未来还需要更可靠的物理预测、更强的不确定性估计、更自动化的 progress labeling、更大规模的真实评估,以及更开放的完整复现。
但方向是清楚的:
机器人基础模型不能只会“反射式地出动作”,它必须逐渐具备“想象—评估—修正”的闭环能力。
这也是 τ0-WM 这篇论文最值得关注的地方。