#Post-training is (Massive) Supervised Learning:后训练正在把 LLM 带回“大规模监督学习”吗?
论文:Post-training is (Massive) Supervised Learning
作者:Michael Hassid, Yossi Adi, Roy Schwartz
机构:FAIR / Meta AI, The Hebrew University of Jerusalem
arXiv:2606.07527
链接:https://arxiv.org/abs/2606.07527
这篇文章不是一个常规的“又提出了一个新训练算法”的论文,而是一篇 position paper:它试图重新解释 2024 年以来 LLM 能力提升的主因。作者的核心判断非常尖锐:
今天所谓的 post-training,尤其是大规模 SFT + RL,正在把 LLM 训练范式重新带回 BERT/GPT-1 时代的“pre-train then fine-tune”。不同的是,当年的 fine-tune 很小;今天的 post-training 变成了百亿、千亿 token 级别的“大规模监督学习/分布拟合”。
换句话说,作者怀疑:很多我们在数学、代码、推理榜单上看到的提升,并不一定意味着模型学到了更一般的“推理智能”;它可能只是模型被非常强力地推向了某些 benchmark 和目标行为的分布。
这件事和 wenjun 最近关心的 LLM Agent 长轨迹 RL、model-based RL、潜空间推理、持续学习、训练范式 很相关。因为它直接戳中了一个问题:如果今天的后训练主要是在“把已知任务分布拟合得更好”,那我们离能在新环境中自我学习、自我演化的 agent 还有多远?
#1. 一句话讲懂这篇论文
这篇论文想证明/论证的是:
当前 LLM 的 post-training 很大程度上不是在“释放预训练里已经有的通用能力”,而是在用大规模 SFT/RL 把模型显式拟合到我们关心的任务分布上;因此,一个没有传统预训练、从随机初始化开始的模型,只要吃足够多高质量的数学/代码 SFT 数据,也能在对应 benchmark 上取得相当不低的成绩。
这里最关键的对照是:
- 如果 post-training 只是“解锁预训练学到的能力”,那没有预训练的模型应该几乎完全不行;
- 如果 post-training 本身就是强分布拟合,那么即使模型没有预训练,只要目标 SFT 数据足够大、足够贴近评测分布,也应该能学出不低的分数。
作者做的实验支持第二种解释。
#2. 图 1:作者如何看 LLM 训练范式的历史轮回
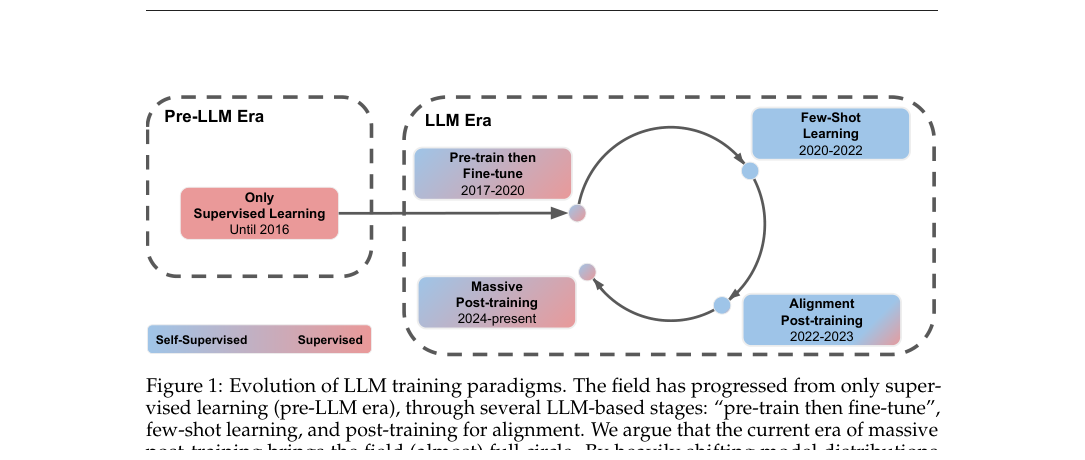
图 1 是整篇文章的思想框架。作者把 LLM 训练范式分成几个阶段:
- Pre-LLM Era:只有监督学习
早期机器学习主要是“有什么任务就标什么数据,然后在这个任务上训练”。模型能力强烈依赖人工标注数据和目标任务分布。
- 2017-2020:Pre-train then Fine-tune
BERT、GPT-1 这一代开始用大规模自监督预训练学语言表示,然后在下游任务上 fine-tune。预训练带来通用表示,但最终任务能力仍然高度依赖 fine-tuning。
- 2020-2022:Few-shot Learning
GPT-3 让大家看到一种更激进的方向:模型在预训练阶段吸收足够多知识和模式后,可以只靠 prompt / in-context examples 去适配新任务。这一阶段最吸引人的地方是:模型似乎不需要每个任务都重新训练。
- 2022-2023:Alignment Post-training
ChatGPT 之后,SFT、RLHF、偏好优化等 post-training 变成标配。最初它主要服务于对齐:让模型更会遵循指令、更安全、更像助手。
- 2024-present:Massive Post-training
到了 o1/o3、Gemini、Claude、DeepSeek-R1、Qwen 等推理模型时代,post-training 不再只是“对齐尾巴”,而变成一个巨大的能力注入阶段。数学、代码、工具使用、长链推理、agent 行为,都可能通过海量 SFT/RL 数据被显式训练进去。
作者的判断是:这个过程让领域“几乎绕回来了”。表面上我们仍然在做 foundation model + post-training,但实际上 benchmark 分布和目标行为已经越来越被显式纳入训练,现代 LLM 正在回到一种更大规模、更复杂的监督学习范式。
#3. 这篇论文真正想反驳什么?
这篇论文并不是说“预训练没用”。相反,作者明确承认预训练仍然关键:预训练模型在所有实验中都更强,RL 阶段也通常需要模型先有一定生成正确解的能力。
它真正反驳的是一个更微妙的叙事:
推理模型的能力主要来自预训练阶段形成的通用能力,post-training 只是把这些能力对齐、释放、格式化出来。
作者认为这个说法低估了 post-training 本身的作用。现代 SFT/RL 数据集已经足够大、足够贴近 benchmark、足够包含 reasoning trace。它不只是让模型“更会说”,而是在直接教模型解数学题、写代码、遵循特定推理格式、输出可评测答案。
所以,很多榜单上的提升可能更应该被理解为:
模型分布被训练过程系统性地推向了评测分布。
这和传统监督学习非常像:训练集和测试集越同分布,模型表现越好;换一个分布,表现就掉。
#4. 实验设计:把“预训练”和“SFT 分布拟合”拆开看
为了验证这个观点,作者设计了一个很直接的实验。
#4.1 三类模型对照
他们比较了三种训练起点:
- 100%-Pre:正常预训练过的 Qwen-2.5 Base 系列模型
这些模型有完整预训练,规模包括 1.5B、3B、7B、14B。
- 0.1%-Pre:只做极少量预训练的模型
先在 DCLM 上预训练约 10B tokens。作者强调这少于标准预训练 token 量的千分之一。然后再做同样的 SFT。
- 0%-Pre:完全没有传统预训练、从随机初始化开始的模型
这些模型没有语言、数学、代码的预训练基础,直接进入目标 SFT 阶段。
#4.2 两类 SFT 数据
作者分别训练数学模型和代码模型:
- 数学:Open Math Reasoning,约 3.2M 问答对;
- 代码:Open Code Reasoning II,约 1.4M Python + 1.2M C++ 问答对。
训练细节也很关键:
- 每个模型训练 50k steps;
- sequence length 为 32k;
- batch size 约 2M tokens;
- 总 SFT token 量约 100B。
这已经不是“小微调”了,而是一个非常重的监督训练阶段。
#4.3 评测
数学评测包括:
- MATH-500;
- AIME 2024;
- AIME 2025;
- HMMT February 2025;
- HMMT November 2025。
代码评测包括:
- LiveCodeBench V5;
- LiveCodeBench V6。
作者报告 pass@1 和 pass@5。
#5. 主结果:从随机初始化开始,SFT 也能训出不低的数学/代码成绩
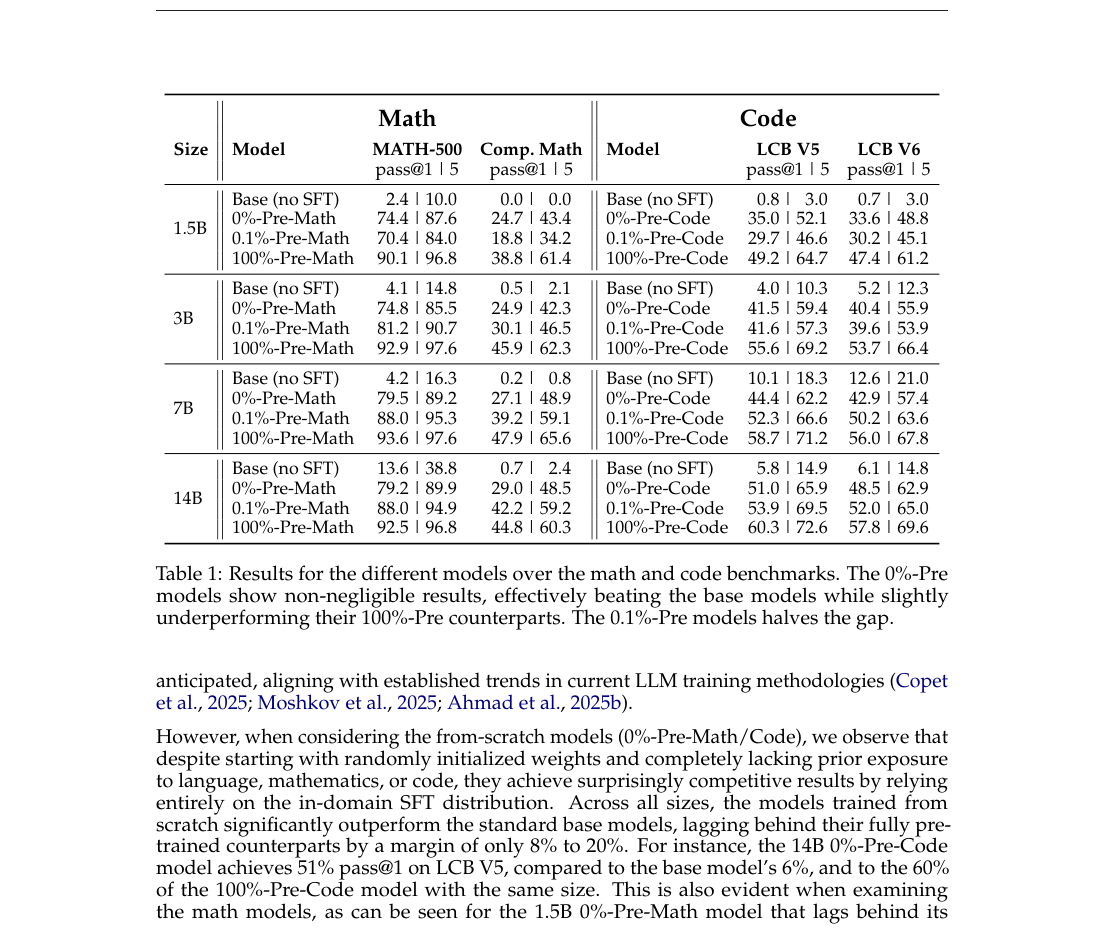
Table 1 是论文最核心的证据。它比较了不同规模、不同预训练程度的模型,在数学和代码 benchmark 上的结果。
最重要的结论有三个。
#5.1 Base 模型不做 SFT,很多 benchmark 上很弱
预训练 base model 本身在这些推理 benchmark 上并不一定强。尤其是没有经过对应 SFT 的 base model,在数学竞赛、LiveCodeBench 等任务上表现很低。
这说明:预训练确实提供了语言、知识、代码、表示、泛化基础,但如果没有专门 post-training,它未必自动表现成我们想要的“推理模型”。
#5.2 0%-Pre 模型显著超过 base model
最惊人的地方是:完全没有传统预训练、从随机初始化开始的 0%-Pre 模型,只靠目标领域 SFT 数据,也能在对应 benchmark 上取得不低成绩。
论文里举了一个非常直观的例子:
- 14B 的 0%-Pre-Code 在 LCB V5 上达到 51% pass@1;
- 同规模 base model 只有 6% 左右;
- 完整预训练 + SFT 的 100%-Pre-Code 是 60% 左右。
也就是说,0%-Pre-Code 明显弱于完整预训练模型,但它已经远远不是“不会语言/不会代码所以完全失败”。它通过大规模 in-domain SFT 学到了能在这个分布上工作的行为模式。
数学上也类似。例如 1.5B 的 0%-Pre-Math,在 MATH-500 和竞赛数学平均上也能取得相当不低的结果,虽然落后完整预训练模型约 10-20 个点。
#5.3 0.1%-Pre 能补上相当一部分差距
只做 10B tokens 的极少量预训练后,模型表现会明显提升。作者说,在多数情况下,0.1%-Pre 可以弥合 0%-Pre 和 100%-Pre 之间约 20%-50% 的差距。
这给了一个很有意思的解释:
预训练的重要作用,可能不只是提供具体数学/代码知识,而是提供更好的初始化、更基本的语言能力、更适合被 SFT 改造的结构性起点。
对基础模型训练来说,这个点很重要。它暗示:如果目标是某些窄分布 benchmark,后训练数据可能贡献了巨大份额;但如果目标是更广的开放泛化,预训练仍然是不可替代的基础。
#6. 训练曲线:SFT 前 20k steps 发生了什么?
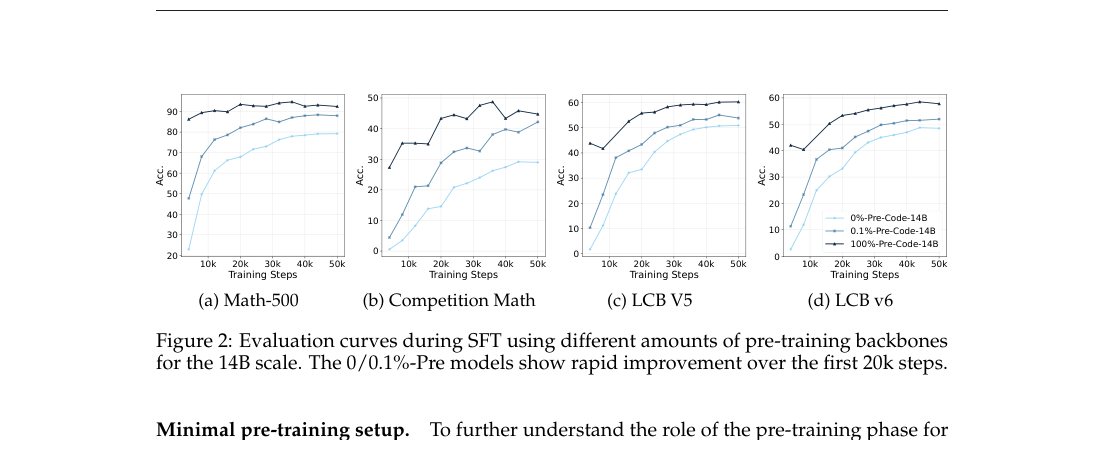
Figure 2 展示了 14B 模型在 SFT 过程中的曲线。
这张图有一个非常直观的现象:
- 100%-Pre 模型一开始就很高,因为它有完整预训练基础;
- 0%-Pre 和 0.1%-Pre 一开始很低;
- 但在前 20k steps,它们上升得非常快;
- 到后期,0%-Pre / 0.1%-Pre 和 100%-Pre 之间仍有差距,但差距已经被明显缩小。
人话说就是:
只要目标 SFT 数据足够大、足够集中,模型可以非常快地被“雕刻”成一个在目标分布上表现不错的系统。
这正是作者所谓 distribution-fitting mechanism 的含义。SFT 不只是格式调整,而是在把模型行为分布强行推向目标数据分布。
#7. 但它真的学会“通用推理”了吗?跨域实验给了冷水
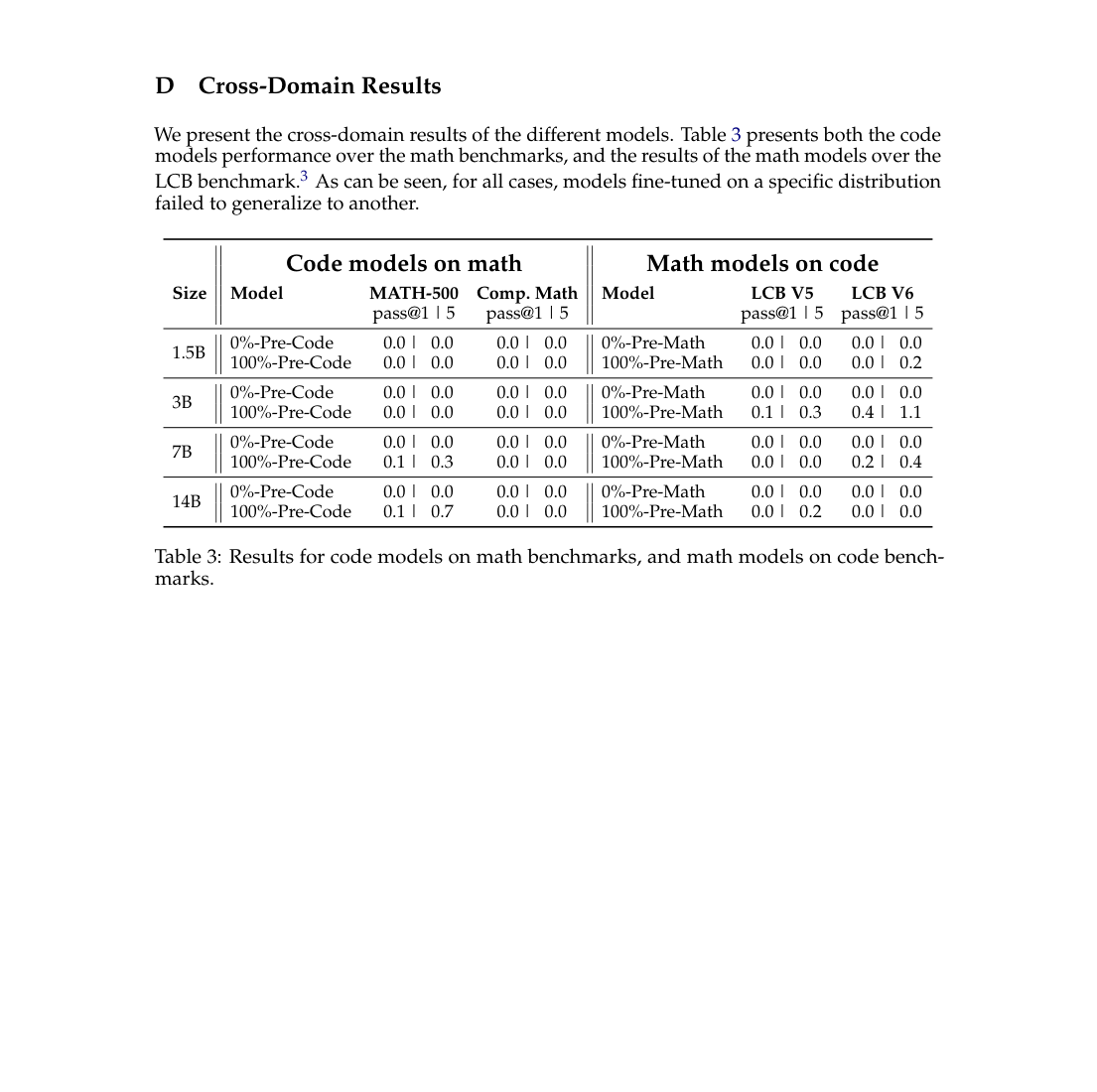
如果 0%-Pre 模型通过数学 SFT 学到了某种通用推理能力,那它是否能迁移到代码?如果通过代码 SFT 学到了程序化推理,那是否能迁移到数学?
作者做了交叉评测:
- code models 去测 math benchmarks;
- math models 去测 code benchmarks。
结果非常差,基本没有跨域泛化。
更有意思的是:不仅 0%-Pre 模型跨域很差,100%-Pre 模型在只针对一个领域 post-training 后,跨到另一个领域时也很差。
这说明什么?
在一个特定分布上做很强的 post-training,并不自动产生跨分布的通用推理能力。它更像是把模型压到了一个特定行为/任务流形上。
这点对 agent 特别重要。因为真实 agent 环境往往不是一个固定 benchmark 分布,而是持续变化的任务、工具、状态、约束、用户意图和环境反馈。如果 post-training 只是在拟合已知分布,那它离“遇到新任务能自己学习策略”还有明显距离。
#8. 例子:没有预训练的模型也能生成看起来像样的 reasoning trace

论文附录展示了 0%-Pre 模型的输出例子。Figure 4 是一个数学题示例:模型会把进制数转成十进制表达式,推导整除条件,列出 56 的因子,最后得到答案。
这件事的冲击在于:这个模型没有传统语言预训练,却能生成结构化、可读、看起来很像推理链的文本。
这不意味着它拥有真正通用的数学理解,但它说明:
reasoning trace 这种形式本身也可以被监督数据强力学习出来。

Figure 5 是代码题示例。模型能够读题、解释思路,然后写出 Python 解法。
这对我们理解“chain-of-thought / reasoning trace”很有启发:
- 一方面,reasoning trace 确实可以帮助模型学会分步骤解决问题;
- 另一方面,trace 的可读性不等于模型具有开放泛化能力;
- 它可能是某个分布内高度可复制的行为模板。
所以之后看推理模型时,不能只看它是否输出长 CoT,而要问:
它在分布外任务、跨领域任务、交互式任务、长时程任务里,是否仍然能形成有效策略?
#9. 这篇论文的“后训练 = 大规模监督学习”到底是什么意思?
我觉得可以把作者的观点拆成三层。
#9.1 第一层:现代 post-training 数据已经太大了
过去 fine-tuning 可能只是几千、几万、几十万条样本;今天的 reasoning SFT 数据可以是百万级样本、百亿 token 级别,还带有长 reasoning trace。
这已经不是一个小的“对齐补丁”。它本身就是一个巨大训练阶段。
#9.2 第二层:评测分布正在变成训练分布
如果大家都在优化数学、代码、agent benchmark,那么这些 benchmark 的任务形式、解题风格、prompt 格式、输出结构,就会逐渐进入训练数据或训练环境。
于是 evaluation 不再是完全独立的“能力测量”,而越来越像 training objective 的延伸。
这也是为什么作者说:当前范式会把 evaluation distributions 变成 explicit training distributions。
#9.3 第三层:能力提升不等于开放泛化
一个模型在 MATH-500、AIME、LCB 上很强,说明它在这些分布上很强;但这不自动说明它具备能迁移到任意新任务的通用推理能力。
如果换一个领域就掉,说明它更像是“分布内专家”,而不是“学会学习的系统”。
#10. 作者最后提出的方向:Learning how to Learn
论文最后从批判转向建设性建议:领域需要从大规模 post-training 走向 learning how to learn。
作者认为当前范式是 reactive 的:
- 发现模型不会某种能力;
- 收集/合成对应 SFT 数据;
- 设计 RL 环境或 reward;
- 重新 post-train;
- 发布新版本。
这就是为什么会不断出现 GPT-5.x、Claude-4.x、Gemini 新版本:底座可能相近,但每次通过新的后训练配方补能力短板。
问题是,这种方式要求我们提前知道目标能力,并为它准备数据和环境。但真正的智能系统应该能在遇到新任务、新约束、新环境时,更高效地自我适应。
这和几个方向有关:
- meta-learning;
- test-time learning / inference-time adaptation;
- self-improving agents;
- continual learning;
- model-based RL;
- 能从环境反馈中构造训练信号的 agent;
- 能在潜空间或工作记忆中形成可迁移策略的模型。
作者的落点其实很接近:不要只把模型训练成“已知 benchmark 的高分机器”,而要训练它获得一种更底层的学习能力。
#11. 和 LLM Agent / 长轨迹 RL 的关系
这篇论文对 agent 研究有几个直接启发。
#11.1 Agent benchmark 高分也可能是后训练分布拟合
如果一个 agent 在某个固定 web benchmark、coding benchmark、tool-use benchmark 上很强,我们要警惕:它是不是只是被大规模训练到了这个 benchmark 的交互模板上?
例如:
- 固定类型的网页任务;
- 固定工具调用格式;
- 固定错误恢复模式;
- 固定评测器偏好;
- 固定 coding issue 格式。
这些都可能被 SFT/RL 拟合。
#11.2 长轨迹 RL 的核心问题不是“再多训一点”
wenjun 一直怀疑超长 agent 轨迹上直接 RL 的可持续性。这篇论文提供了一个侧面支持:如果 post-training 本质上是在拟合已知目标分布,那么它面对长尾、新任务、环境变化时会很脆弱。
长轨迹 agent 需要的不只是更多 SFT/RL,而是:
- 能建模环境状态转移;
- 能压缩历史经验;
- 能从失败中形成可复用策略;
- 能区分表面动作模板和深层任务结构;
- 能在新任务上快速学习,而不是等待下一轮离线 post-training。
这就把问题推向 model-based RL、world model、memory、latent planning、self-evolving agent。
#11.3 “数据塑造能力”比“能力自然涌现”更值得研究
这篇论文提醒我们:今天很多能力可能并不是神秘涌现,而是训练数据和训练目标系统性塑造的结果。
因此,研究 agent 预训练/后训练时,一个关键问题是:
什么样的数据分布、环境分布、反馈机制,会塑造出可迁移的 agentic 能力,而不只是塑造出 benchmark-specific policy?
这正是“agent 预训练数据如何塑造能力”这个问题的核心。
#12. 我对这篇论文的评价
我觉得这篇论文最有价值的地方,不在于它完全证明了“后训练就是监督学习”。严格说,它的实验证据还有明显边界:
- 只研究了数学和代码;
- 主要研究 SFT,没有真正覆盖现代 post-training 里的 RL;
- 0%-Pre 模型虽然表现不低,但仍然弱于完整预训练模型;
- benchmark 本身是否被训练数据污染、是否高度 tracked,也会影响结论;
- 训练从 scratch 的 token 量仍然很大,并不代表这种路线经济。
但它提出了一个非常好的“反向检验”:
如果没有预训练,只靠目标 SFT 数据也能拿到很高分,那我们就必须重新估计 benchmark 分数中有多少来自分布拟合,有多少来自通用能力。
这对解释当前推理模型、代码模型、agent 模型都很重要。
我会把它看作一篇“范式警告”论文:它不是否定 post-training,而是提醒我们不要把 post-training 训练出的分布内表现误读为开放式智能。
#13. 如果只记住三个 takeaway
- 现代 post-training 已经不是小修小补,而是大规模能力塑造阶段。
SFT/RL 数据足够大、足够贴近 benchmark 时,可以直接训练出很强的目标行为。
- 从随机初始化开始,只靠数学/代码 SFT,也能在对应 benchmark 上取得不低成绩。
这说明很多 reasoning benchmark 表现可能包含很大比例的分布拟合成分。
- 真正值得追求的是 learning how to learn,而不是 endlessly fitting known benchmarks。
对 LLM Agent 来说,关键不是把每个已知环境都 post-train 一遍,而是让模型能在新环境中自适应、积累经验、形成可迁移策略。
#14. 给 wenjun 的研究问题延伸
这篇论文可以自然引出几个适合继续深挖的问题:
- 如何区分 benchmark-specific distribution fitting 和 genuinely transferable reasoning?
需要设计更强的跨域、跨形式、交互式、动态生成 benchmark。
- 后训练数据中哪些因素塑造了可迁移能力?
是任务多样性、反馈密度、解题轨迹质量、失败样本、环境复杂度,还是 curriculum?
- LLM Agent 是否需要一个“预训练级别”的环境交互阶段?
不是在固定 benchmark 上做 RL,而是在多样环境中学习状态、动作、反馈和长期目标。
- model-based RL / world model 能否缓解 post-training 的 reactive 问题?
如果 agent 有内部环境模型,它就不必等每个新任务都通过离线 SFT/RL 注入。
- 潜空间推理是否可以被看作 learning how to learn 的机制之一?
如果模型能在 latent/work memory 中形成可压缩、可更新、可迁移的任务表示,它可能比显式长 CoT 更接近开放泛化。
这也是我觉得这篇文章值得读的原因:它不是告诉我们“后训练没用”,而是逼我们追问:后训练到底在塑造什么能力?哪些能力只是分布内拟合?哪些能力才是通向自演化 agent 的基础?