#LUFFY 论文详解:Learning to Reason under Off-Policy Guidance
论文:Learning to Reason under Off-Policy Guidance
作者:Jianhao Yan, Yafu Li, Zican Hu, Zhi Wang, Ganqu Cui, Xiaoye Qu, Yu Cheng, Yue Zhang
版本:v5, 2025-06-22
项目页:ElliottYan/LUFFY
#0. 一句话总结
LUFFY 这篇论文想解决一个很关键的问题:纯 on-policy RLVR 只能从模型自己采样出来的轨迹里学习,因此很容易被 base model 的初始能力上限卡住;但直接把强模型的长推理轨迹拿来 SFT,又容易变成僵硬模仿。LUFFY 的做法是在 RLVR 里混入强模型的 off-policy reasoning traces,并通过 Mixed-Policy GRPO + policy shaping,让模型“借强者的路标”,但仍然保持自己的探索。
如果把它放到最近 reasoning model 的训练脉络里,它其实站在一个很有意思的位置:
- DeepSeek-R1 / OpenReasoner / SimpleRL 这条线强调:只用可验证奖励做 RL,也能激发长 CoT 和反思行为;
- 但这些方法大多是 on-policy:模型只能从自己当前能采样出的答案里学习;
- 如果 base model 太弱,采样不到正确轨迹,就没有正反馈,RL 可能无法启动;
- 另一条路线是蒸馏或 SFT:直接学习强模型的
<think>轨迹; - 但 SFT 很容易学到表面风格,例如“嗯,让我想想”“wait”“重新检查一下”,而不一定学到真正能泛化的推理策略;
- LUFFY 则试图把这两者合起来:off-policy 轨迹负责把模型带出初始能力边界,on-policy rollout 负责让模型仍然在自己的分布上探索和优化。
这也正好回应了之前讨论过的 Think SFT off-policy 问题:这篇论文不是说 off-policy guidance 有害,而是说不能用朴素 SFT 的方式吃 off-policy trace;更合理的方式是把 off-policy trace 放进 RL 的 advantage 计算和策略更新里,让模型选择性吸收,而不是整条背下来。
#1. 这篇论文要解决什么问题?
#1.1 RLVR 的成功:用可验证奖励训练推理模型
最近大模型 reasoning 能力的一个重要范式是 RLVR,也就是 Reinforcement Learning with Verifiable Rewards。
在数学题、代码题、形式化证明等任务上,我们往往不需要训练一个复杂 reward model,只需要检查最终答案是否正确:
- 数学题:答案是否等于标准答案;
- 代码题:是否通过测试;
- 选择题:选项是否正确;
- 某些形式化任务:证明是否能被验证器接受。
论文中使用的 reward 非常简单:
这种奖励的好处是:
- 不需要训练 reward model;
- 不太容易 reward hacking;
- 可以规模化地产生强化学习信号;
- 能直接优化“解题正确率”。
DeepSeek-R1、OpenReasoner-Zero、SimpleRL 等工作都表明:这种看似简单的奖励,在合适的底座和训练设置下,可以激发长链推理、反思、自我修正等行为。
#1.2 但纯 on-policy RLVR 有一个根本瓶颈
纯 on-policy RLVR 的训练信号来自模型自己当前策略生成的 rollout。也就是说:
模型只能从“自己已经有概率生成出来的东西”里学习。
这会带来一个问题:如果模型在某类问题上几乎采样不到正确解,那么 reward 就几乎全是 0,advantage 没有区分度,训练就很难启动。
论文里把这个限制表述为:on-policy RL bounded by the base LLM itself。也就是,RL 更像是在放大 base model 里已有的行为,而不一定能凭空创造 base model 完全没有的认知能力。
这点对弱模型尤其明显。比如 LLaMA-3.1-8B 在较难数学数据上,如果自己 rollout 基本做不对,那么 on-policy RL 就可能奖励塌缩到 0。
#1.3 直接 SFT 强模型轨迹又有什么问题?
既然 on-policy RL 受限于自己,那最直接的想法就是:给它看强模型的推理轨迹。
例如用 DeepSeek-R1 生成长 CoT,然后对弱模型做 SFT。这就是很多 reasoning distillation / Think SFT 的基本思路。
但论文指出,朴素 SFT 会产生一种问题:rigid imitation,也就是僵硬模仿。
它可能学到的是:
- 生成更长的
<think>; - 复述强模型的表达风格;
- 在错误答案里也继续写很长;
- 表面上有反思,实际没有更有效的问题求解;
- 在 OOD 任务上泛化变差。
论文附录里有很直观的分析:SFT 的输出长度平均达到 4646 tokens,而 LUFFY 是 2832 tokens。SFT 和 DeepSeek-R1 轨迹的 BLEU 相似度达到 57.5,LUFFY 是 44.8,on-policy RL 是 8.8。这说明 SFT 更像是在背 teacher 的轨迹形态,而 LUFFY 则是有选择地吸收。
因此,这篇论文的核心问题不是“要不要 off-policy trace”,而是:
如何使用强模型的 off-policy reasoning trace,同时避免把模型训练成只会机械模仿 teacher 的长思维文本?
#2. LUFFY 的核心想法
LUFFY 全称是:
Learning to reason Under oFF-policY guidance
名字里已经说明了方法定位:在 off-policy 指导下学习推理。
它不是纯 SFT,也不是纯 on-policy RL,而是在 RLVR 的每个训练组里同时放入:
- 当前 policy model 自己生成的 on-policy rollouts;
- 更强模型,例如 DeepSeek-R1,生成的 off-policy reasoning trace。
然后让它们一起参与 group reward / advantage 计算。
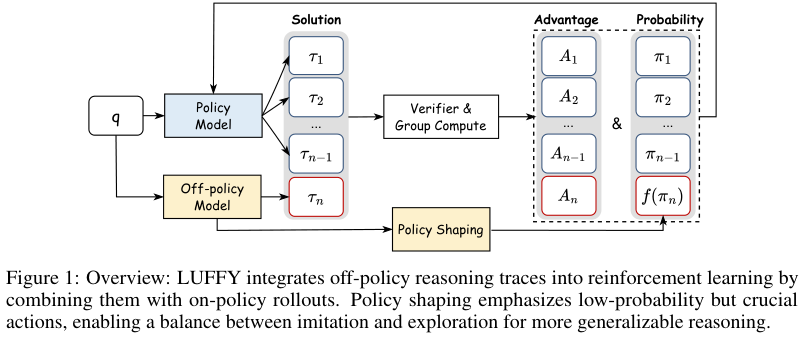
图 1 可以这样读:
- 输入问题
q同时给当前 policy model 和 off-policy model; - 当前 policy model 生成多条自己的解题轨迹;
- off-policy model 生成一条高质量 reasoning trace;
- 所有轨迹一起进入 verifier,得到是否正确的奖励;
- 这些轨迹组成一个 group,用 group 内 reward 计算 advantage;
- off-policy trace 还会经过 policy shaping,让模型更重视那些当前概率低但关键的动作。
用人话说,LUFFY 想实现的是:
当学生自己还做不出来时,强模型轨迹提供脚手架;当学生逐渐能做出来时,学生自己的探索重新变得重要。整个过程不是“照抄强模型”,而是“在强模型提示下扩展自己的策略空间”。
#3. 方法一:Mixed-Policy GRPO
#3.1 先回顾 GRPO
GRPO 是 DeepSeekMath / DeepSeek-R1 系列里非常关键的优化方法。它和 PPO 的区别之一是:不额外训练 value model,而是用同一个 prompt 下多条采样答案的相对 reward 来估计 advantage。
给定一个问题 q,模型采样 N 条解题轨迹:
每条轨迹经过 verifier 得到 reward。然后优势值大致是:
也就是:这条答案比同组其它答案好多少。
这种设计适合数学推理,因为同一道题可以采样多个解法,正确的轨迹相对错误轨迹就会获得更高 advantage。
#3.2 LUFFY 怎么改 GRPO?
普通 GRPO 的 group 只包含 on-policy rollouts:
LUFFY 加入 off-policy rollouts:
然后 advantage 不再只在 on-policy group 里算,而是在混合 group 里算:
这一步非常关键。
如果当前模型自己生成的答案都错,而 off-policy trace 是对的,那么 off-policy trace 的 advantage 会比较高。模型就会获得“向这类高质量轨迹靠近”的信号。
如果当前模型自己已经能生成正确答案,那么 on-policy 正确轨迹也会有高 advantage。模型就不必只追着 teacher 走,而可以强化自己的成功解法。
这就是论文说的动态平衡:
when its own roll-outs fail, imitate high-quality off-policy traces; when its roll-outs succeed, preserve self-driven exploration.
#3.3 Mixed-Policy GRPO 的目标函数
LUFFY 在目标函数里同时包含 off-policy objective 和 on-policy objective。
简化理解:
- on-policy 部分仍然像 GRPO/PPO 一样,用当前策略和旧策略的概率比;
- off-policy 部分则要处理当前策略和行为策略
π_φ的分布差异,因此引入 importance sampling ratio:
不过实际实现里,论文为了避免不同模型 tokenizer / probability 计算麻烦,把 π_φ 近似设为 1。这个工程选择很重要:它让 LUFFY 可以直接使用现成的强模型轨迹数据,而不需要重新算 teacher policy 的 token probability。
论文也给了一个收敛性分析:在 importance weight 有界、目标函数 Lipschitz smooth 等假设下,这个 importance-weighted policy gradient estimator 可以以 O(1/sqrt(K)) 的速率收敛到 stationary point。
这部分理论的意义不在于完全刻画 LLM 训练,而是在说:把 off-policy 轨迹混入 policy gradient 不是纯工程 hack,它至少可以被放进一个相对标准的 off-policy policy gradient 框架里理解。
#4. 方法二:Policy Shaping,防止混合训练过早塌缩
#4.1 Mixed-Policy 还有一个新问题:熵塌缩
把 off-policy trace 混进来之后,模型会更快看到正确轨迹,训练初期会更快进步。但论文发现,朴素 Mixed-Policy 会导致一个问题:entropy collapse。
也就是模型很快变得过于确定,探索能力下降。
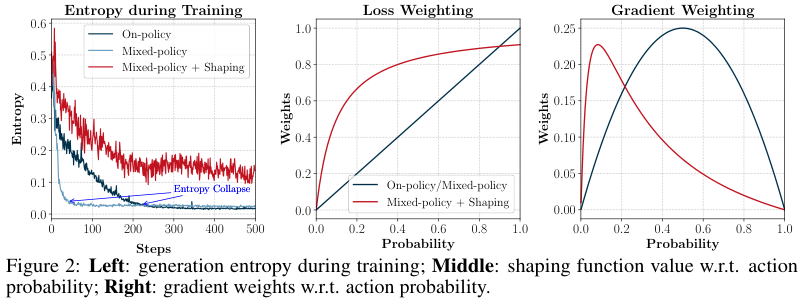
图 2 左边很直观:
- on-policy 的 entropy 会下降;
- mixed-policy 的 entropy 下降更快;
- 加入 shaping 后,entropy 能保持得更好。
为什么朴素 mixed-policy 会塌缩?论文给出的解释是:模型会优先强化那些 off-policy trace 中同时也已经是当前模型高概率的 token,而忽视那些低概率但关键的 token。
这就会导致一种“浅层模仿”:
- teacher 的常见表达学得很快;
- 真正不熟悉、但能带来推理能力跃迁的动作学不到;
- 模型很快收缩到一个看起来像 teacher、但实际能力提升有限的区域。
#4.2 Policy shaping 的直觉
LUFFY 的 policy shaping 想做一件事:
提高当前模型低概率但重要的 off-policy action/token 的学习权重。
普通 importance ratio 近似可以看作线性函数:
它的问题是,当前模型概率很低的 token,梯度也会很小。可是这些低概率 token 可能恰恰是模型还不会、但应该学会的关键推理动作。
LUFFY 使用的 shaping function 是:
其中 γ=0.1。
这个函数的效果是:在低概率区域相对放大权重,让模型不要只学自己已经熟悉的 token。
图 2 中间和右边展示了这个机制:
- 中图是 loss weighting:shaping 后低概率区域权重更高;
- 右图是 gradient weighting:低概率 action 得到更强梯度。
#4.3 这和 Think SFT 的关系
这点对 Think SFT 很有启发。
朴素 SFT 对 teacher trace 的每个 token 一视同仁地做最大似然。它不会区分:
- 哪些 token 只是 teacher 的语言风格;
- 哪些 token 是关键推理转折;
- 哪些 token 对 student 来说已经很容易;
- 哪些 token 对 student 来说概率低但非常值得学。
LUFFY 的 policy shaping 则试图把学习信号集中到“当前模型不熟悉但有用”的地方。这是比 SFT 更细的监督方式。
所以可以说:
LUFFY 不是简单反对 off-policy reasoning trace,而是反对把 off-policy trace 当普通文本做均匀模仿。真正要学的是 teacher 轨迹中能扩展 student 策略空间的关键动作。
#5. 实验设置
#5.1 训练数据
论文使用 OpenR1-Math-220k 的一个子集:
- prompts 来自 NuminaMath 1.5;
- off-policy reasoning traces 由 DeepSeek-R1 生成;
- 默认子集有 94K prompts;
- 过滤掉超过 8192 tokens 的生成;
- 过滤掉 Math-Verify 检查错误的生成;
- 最终得到 45K prompts 和 off-policy reasoning traces。
#5.2 训练设置
主要设置包括:
- 默认底座:Qwen2.5-Math-7B;
- 也扩展到 Qwen2.5-Math-1.5B、Qwen2.5-Instruct-7B、LLaMA-3.1-8B;
- 每个 prompt 采样 8 条 rollout;
- on-policy baseline 使用 8 条 on-policy rollouts;
- LUFFY 使用 7 条 on-policy + 1 条 off-policy;
- rollout temperature = 1.0;
- 测试 temperature = 0.6;
- reward 使用 Math-Verify;
- 不使用 format reward 或 length reward;
- 设置 entropy loss coefficient = 0.01;
- policy shaping 中
γ=0.1。
这个设计也很值得注意:LUFFY 不是大量塞 teacher trace,而是每组只加 1 条 off-policy trace。这说明它强调的是“指导”而不是“覆盖”。
#5.3 评测任务
数学推理 benchmark 包括:
- AIME 2024;
- AIME 2025;
- AMC;
- Minerva;
- OlympiadBench;
- MATH-500。
OOD benchmark 包括:
- ARC-c;
- GPQA-diamond;
- MMLU-Pro。
OOD 结果很关键,因为如果一个方法只是背数学轨迹风格,它可能在数学分布内有效,但在更广泛 reasoning 任务上不一定泛化。
#6. 主结果:LUFFY 比 on-policy RLVR 和朴素 off-policy 方法都更强
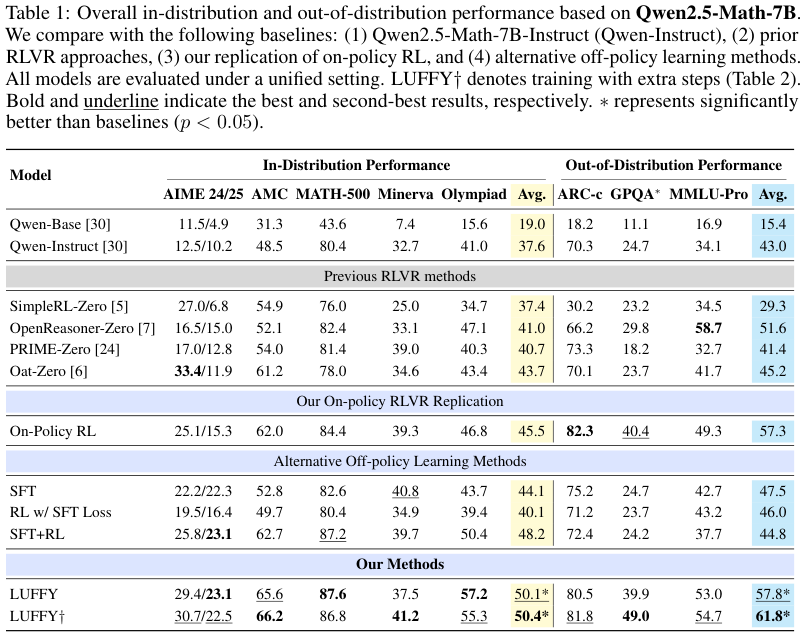
#6.1 In-distribution 数学任务
在 Qwen2.5-Math-7B 上,LUFFY 的六个数学 benchmark 平均分是 50.1,LUFFY† 是 50.4。
对比几个关键 baseline:
- Qwen-Base:19.0;
- Qwen-Instruct:37.6;
- Oat-Zero:43.7;
- On-Policy RL:45.5;
- SFT:44.1;
- SFT+RL:48.2;
- LUFFY:50.1;
- LUFFY†:50.4。
论文强调,LUFFY 相比 previous RLVR methods 有 +6.4 的平均提升。
#6.2 Out-of-distribution 任务
OOD 结果更有意思。
三项 OOD benchmark 平均分:
- Qwen-Base:15.4;
- Qwen-Instruct:43.0;
- OpenReasoner-Zero:51.6;
- On-Policy RL:57.3;
- SFT:47.5;
- SFT+RL:44.8;
- LUFFY:57.8;
- LUFFY†:61.8。
这里可以看到一个很重要的现象:SFT 和 SFT+RL 在 OOD 上并不好。
SFT 的 ID 平均分是 44.1,看起来还可以,但 OOD 只有 47.5;SFT+RL 的 ID 是 48.2,但 OOD 反而降到 44.8。说明它们可能学到了数学 teacher trace 的表面模式,但泛化到其它 reasoning 任务时不稳。
LUFFY† 的 OOD 平均分达到 61.8,说明它不是简单记忆训练分布里的解题格式,而是在某种程度上提升了更一般的推理策略。
#6.3 资源开销也不是靠堆出来的
论文还比较了资源需求:
- LUFFY:77 × 8 GPU hours;
- LUFFY†:130 × 8 GPU hours;
- SFT:24 × 8 GPU hours;
- RL w/ SFT Loss:133 × 8 GPU hours;
- SFT+RL:130 × 8 GPU hours。
普通 SFT 当然便宜,但效果和泛化差。更重要的是,RL w/ SFT Loss 和 SFT+RL 的 GPU hours 与 LUFFY† 相当甚至更高,但性能更弱。
论文解释说,这是因为朴素 SFT 会诱导过长生成,导致后续 RL rollout 计算成本增加。也就是说,SFT 不只是泛化可能差,还可能让训练变贵。
#7. LUFFY 能否适配更多底座?
论文把 LUFFY 扩展到三类模型:
- 小模型:Qwen2.5-Math-1.5B;
- 指令模型:Qwen2.5-Instruct-7B;
- 较弱模型:LLaMA-3.1-8B。
结论是:LUFFY 在三者上都优于 SFT 和 On-Policy RL。
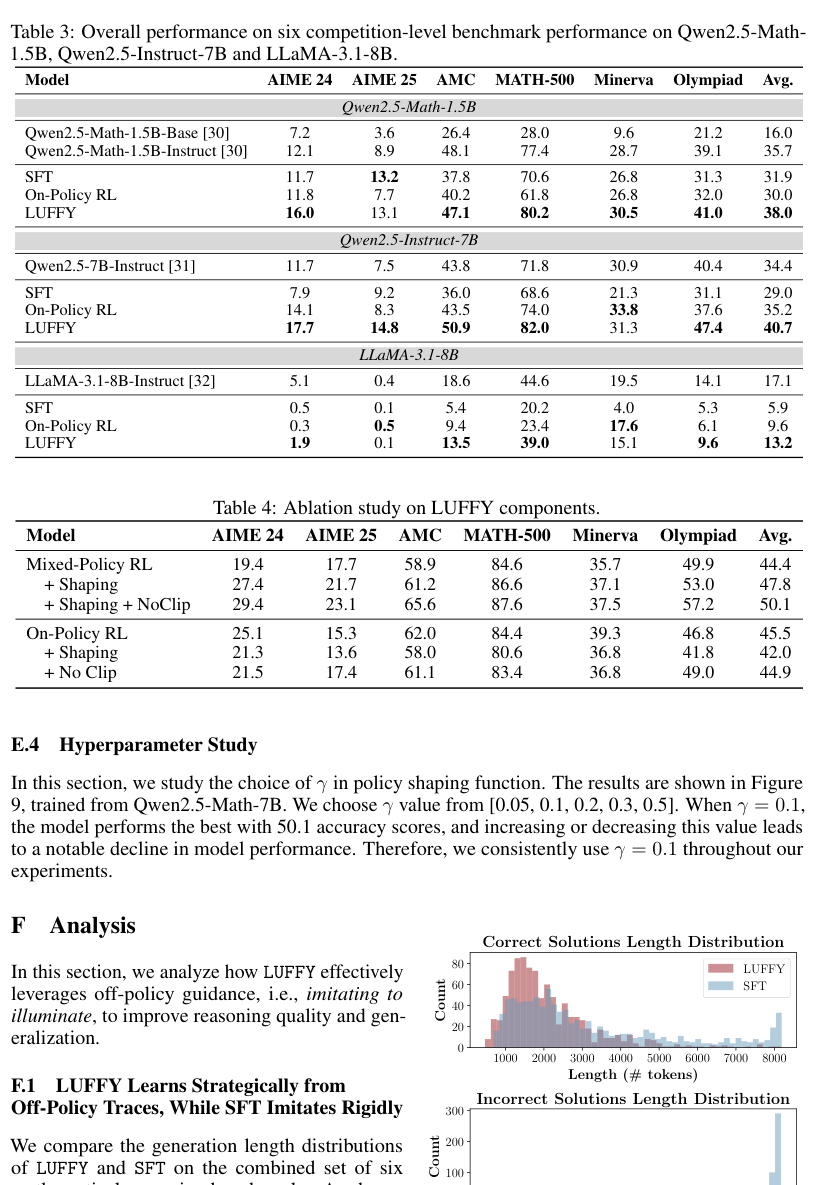
一些关键数字:
- Qwen2.5-Math-1.5B:LUFFY 平均 38.0,SFT 31.9,On-Policy RL 30.0;
- Qwen2.5-Instruct-7B:LUFFY 平均 40.7,SFT 29.0,On-Policy RL 35.2;
- LLaMA-3.1-8B:LUFFY 平均 13.2,SFT 5.9,On-Policy RL 9.6。
这里 LLaMA-3.1-8B 的绝对分数仍然不高,但 LUFFY 至少显著超过 SFT 和 On-Policy RL。这说明 off-policy guidance 对弱模型确实能提供额外训练信号。
#8. 最有意思的实验:On-policy 失败时,LUFFY 还能启动学习
论文第 5.2 节标题就是:LUFFY Succeeds Where On-Policy Fails。
它们用 LLaMA-3.1-8B 在 Easy 和 Hard 两种训练集上做实验。
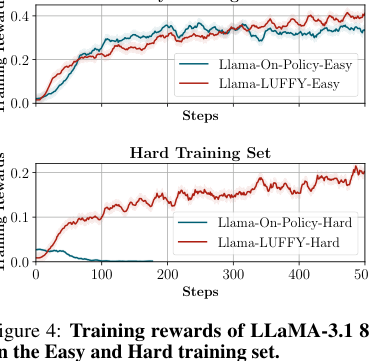
结果很清楚:
- Easy set 上,on-policy RL 和 LUFFY 都能学;
- Hard set 上,on-policy RL 的 training reward 很快塌到接近 0;
- LUFFY 在 Hard set 上仍然能稳定提升。
这就是 off-policy guidance 的真正价值:当模型自己采样不到正例时,外部强模型轨迹可以提供“从哪里开始学”的方向。
如果用人话类比:
- on-policy RL 像让学生自己刷题,做对了才知道哪里对;
- 如果题太难,学生一道都做不对,就没有学习信号;
- LUFFY 像是在学生刷题时,偶尔给一条高手解法作为脚手架;
- 学生不是完全背高手解法,而是在自己的尝试和高手解法之间比较,逐渐知道哪些方向值得探索。
#9. 训练动态:LUFFY 如何在模仿与探索之间取得平衡?
论文用三条曲线解释 LUFFY 的训练动态:training reward、response length 和 entropy。
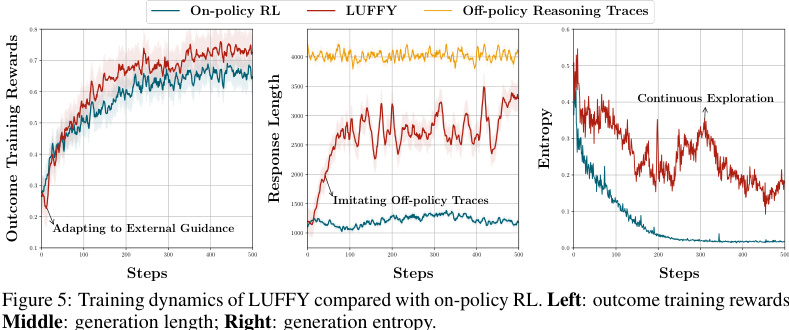
#9.1 训练奖励:先适应外部指导,再超过 on-policy
左图显示,LUFFY 在早期可能有一个适应过程,因为模型要吸收外部强模型的 reasoning pattern。这可能导致初期 reward 波动甚至下降。
但随着训练推进,LUFFY 的 reward 明显超过 on-policy RL。
这说明 off-policy trace 不是立刻带来收益,而是需要模型调整自己的策略空间。
#9.2 生成长度:LUFFY 会靠近 off-policy trace,但不是完全照抄
中图显示,LUFFY 的 response length 会逐渐增长,向 off-policy reasoning trace 靠近。
这说明它确实在吸收长推理行为。
但它没有像 SFT 那样生成过长、僵硬的 trace。附录里 LUFFY 的平均长度是 2832 tokens,而 SFT 是 4646 tokens。这说明 LUFFY 更像是选择性地学到了“什么时候需要展开推理”,而不是无脑变长。
#9.3 熵:LUFFY 保持持续探索
右图是最关键的:on-policy RL 的 entropy 很快下降到接近 0,而 LUFFY 的 entropy 保持更高,并且有波动。
这说明 LUFFY 没有过早变成一个确定性策略。它仍然保留探索低概率但可能更优的 reasoning path 的能力。
这一点也解释了为什么 LUFFY 在 OOD 上表现更好:它不是只学一个固定模板,而是保留了生成多样推理路径的能力。
#10. 消融实验:Shaping 和 NoClip 都有贡献
论文 Table 4 做了消融实验。
核心结果:
- Mixed-Policy RL:44.4;
- + Shaping:47.8;
- + Shaping + NoClip:50.1;
- On-Policy RL:45.5;
- On-Policy + Shaping:42.0;
- On-Policy + NoClip:44.9。
这说明:
- 仅仅加 shaping 到 on-policy RL 上没有帮助;
- shaping 的价值依赖于 off-policy guidance;
- Mixed-Policy 本身能提供外部信号;
- Shaping 能让模型更好吸收低概率但关键的 off-policy token;
- NoClip 进一步减少了 off-policy 学习被 clip 抑制的问题。
这里有个细节:PPO/GRPO 的 clipping 本来是为了稳定训练,限制策略更新不要太大。但 off-policy guidance 的目标恰恰可能和当前 policy 差距很大。过强 clip 会把这些“陌生但有效”的更新压掉。因此 LUFFY 在 off-policy 部分不使用 clip,并在附录里讨论了去掉 on-policy clip 的影响。
#11. 案例分析:SFT、On-Policy RL 和 LUFFY 的行为差异
论文最后给了一个几何题案例,非常适合理解三种方法的差别。

#11.1 SFT:长,但容易陷入空转
SFT 的输出很长,超过 8192 tokens,但没有真正推进解题。论文标注了几个典型问题:
- Problem Restatement Not Analysis:一直复述题目;
- Endless Definition Loop:不断定义概念;
- Wait-Pattern Paralysis:反复 “Wait, but ...”;
- Small-Case Trap:陷入小例子;
- Complete Breakdown:最后输出崩坏。
这正是 Think SFT 常见风险:模型学会了“反思的语言模式”,但没有学会“反思的控制逻辑”。
#11.2 On-Policy RL:短一些,但可能自信地错
On-Policy RL 的输出长度约 1002 tokens,最后答案错了。它的问题是:
- 有形式化分解;
- 有看似系统的结构;
- 但中间推理不够扎实;
- 最后给出未经充分支持的结论。
这像是 RL 把模型已有能力强化了一些,但没有让它跨过关键推理瓶颈。
#11.3 LUFFY:更长但有效,有清晰分解和验证
LUFFY 的输出长度约 2623 tokens,最后答案正确。论文标注了:
- Clear Problem Definition;
- Systematic Decomposition and Analysis;
- Precise Mathematical Calculation;
- Logical Verification;
- Consistency Check。
它不像 SFT 那样无限空转,也不像 on-policy 那样短而自信地错,而是在较长推理中保持了有效结构。
这组案例很好地说明了论文最核心的主张:
LUFFY 不是让模型变得更像 teacher,而是让模型更会利用 teacher trace 来改善自己的问题求解。
#12. 这篇论文和 Think SFT off-policy 问题的关系
这篇论文对 “Think SFT 的 off-policy 问题” 给了一个很直接的证据链。
#12.1 它承认 off-policy trace 有价值
首先,LUFFY 并不认为 off-policy reasoning trace 本身是错的。相反,它的整个方法就是利用 DeepSeek-R1 生成的 off-policy traces。
这说明强模型轨迹确实能提供 base model 自己采不到的 reasoning pattern。
#12.2 它反对朴素模仿
但论文的实验也表明,直接 SFT 或 RL w/ SFT Loss 并不是最优方式。SFT 容易:
- 学到过长输出;
- OOD 泛化差;
- 在错误答案里也持续生成长 reasoning;
- 对 teacher trace 相似度过高;
- 缺乏 test-time exploration。
这和我们之前说的完全一致:带 think 的 SFT 不是简单输出拟合,而是在模仿一条行为轨迹。如果轨迹来自 teacher 分布,student 很可能学到“在 teacher 状态下的动作”,而不是“在自己状态下的决策”。
#12.3 它给出的解决方向是“混合策略 + 选择性学习”
LUFFY 的方案可以抽象成:
- 不要只在 teacher 分布上做 token-level imitation;
- 让 student 自己 rollout,保留 on-policy 信号;
- 把 teacher trace 放进同一个 group 里,让 reward/advantage 决定何时学 teacher;
- 对低概率但关键的 teacher action 加权,避免只学表面常见模式;
- 保持 entropy,避免策略过早塌缩。
这比 “teacher trace SFT” 更接近一种 off-policy guided RL。
#13. 我怎么看这篇论文的贡献
#13.1 它把 reasoning RL 的一个矛盾讲清楚了
当前 reasoning RL 有一个结构性矛盾:
- 纯 RLVR 很优雅,因为奖励简单、可验证、on-policy;
- 但它受限于 base model 自己能探索到什么;
- 蒸馏强模型轨迹可以突破这个限制;
- 但蒸馏又容易表面模仿和分布错配。
LUFFY 的价值是把这个矛盾放进一个统一训练框架:既要外部指导,又要自我探索。
#13.2 它对“弱模型能不能靠 RL 变强”给了更现实的答案
一些工作会问:RL 到底能不能让模型获得 base model 之外的能力?
LUFFY 的答案比较折中:
- 如果完全靠 on-policy RL,弱模型可能确实启动不了;
- 但如果有强模型 off-policy guidance,弱模型可以被带出原来的探索边界;
- 这不是 RL 单独创造能力,而是 RL + 外部轨迹 + 验证奖励 共同塑造能力。
这对实际训练很重要。因为很多开源底座并不一定有足够强的初始 reasoning 行为,纯 zero-RL 可能很难复现 R1-like 效果。LUFFY 提供了一种更稳的路径。
#13.3 它把“长 CoT 是否有用”变成了“如何用长 CoT”
这篇论文也提醒我们,长 CoT 本身不是能力。
- SFT 可以让模型变长,但不一定变强;
- On-policy RL 可以让模型更短更确定,但可能探索不足;
- LUFFY 试图让模型在需要时变长,并且保持探索和验证。
所以关键不是“训练模型输出更长 think”,而是:
训练模型在正确的问题状态下展开必要推理,在无效路径上及时停止,在关键低概率动作上敢于探索。
#14. 局限与开放问题
论文自己也提到了一些限制。
#14.1 主要局限在可验证任务
LUFFY 依赖 RLVR,因此目前主要适合有 verifiable reward 的任务,例如数学。
但很多重要任务没有简单 verifier:
- 开放式问答;
- 长文写作;
- 多轮 agent 任务;
- 真实软件工程;
- 科研规划;
- 复杂决策。
这些任务怎么设计可靠 reward,是下一步关键。
#14.2 模型规模还不大
论文主要实验在 7B 和更小模型上。LUFFY 扩展到更大模型会怎样,还需要更多实验证据。
更大模型可能:
- 自身探索能力更强,off-policy guidance 的边际收益不同;
- 更容易吸收复杂 trace;
- 也可能更容易过拟合 teacher 风格;
- 训练稳定性和成本问题更复杂。
#14.3 每题只用一条 off-policy trace
论文目前每个问题只混入一条 off-policy trace,而且主要来自一个强 teacher。
未来可以研究:
- 多条 teacher traces;
- 多 teacher;
- 不同风格 teacher;
- 正确但短的 trace vs 正确但长的 trace;
- 包含错误恢复过程的 trace;
- 搜索树而不是单条轨迹。
#14.4 Off-policy trace 的质量和类型如何选择?
不是所有 teacher trace 都值得学。
有些 trace 可能:
- 太长;
- 太依赖 teacher 的隐含知识;
- 对 student 来说不可学习;
- 只是形式上正确但推理不透明;
- 包含 student 不该模仿的冗余反思。
LUFFY 用 verifier 过滤 correctness,但还没有充分解决“什么样的 reasoning trace 更适合 student 学”的问题。
这可能需要更细粒度的 trace selection / learnability estimation。
#15. 可能的后续研究方向
结合这篇论文和 Think SFT off-policy 问题,我觉得后续有几条很值得做。
#15.1 Learnability-Aware Off-Policy Guidance
不是所有强模型轨迹都适合弱模型。
可以设计一个 learnability score,判断某条 teacher trace 对 student 是否可学:
- student 对关键 token 的概率是否太低;
- trace 是否包含 student 不具备的概念跳跃;
- student 能否在局部前缀上复现后续推理;
- trace 的长度和复杂度是否适合当前训练阶段。
然后只选择“难但可学”的轨迹,而不是最强、最长、最复杂的轨迹。
#15.2 Productive Divergence:鼓励有价值的偏离
LUFFY 仍然使用 teacher trace 作为高质量引导。但 student 不一定应该完全跟 teacher 走。
可以研究:哪些偏离 teacher 的地方是坏的,哪些是好的?
例如:
- student 走了更短路径且答案正确;
- student 使用不同解法但可验证;
- student 发现 teacher trace 里的冗余步骤;
- student 在某一步偏离后失败,但失败可恢复。
这可以发展成一种 productive divergence objective:不是压制所有偏离,而是奖励能带来正确解和更高效率的偏离。
#15.3 Repairability-Aware Trace Training
很多 reasoning 能力不在于从不犯错,而在于犯错后能修。
可以把 off-policy guidance 从“完整正确轨迹”扩展为“错误状态下的修复轨迹”:
- 先让 student 自己生成错误前缀;
- teacher 针对这个错误前缀给出诊断和修复;
- student 学习在自己的错误状态下如何 recover。
这会比直接模仿 teacher 的完整正确 trace 更 on-policy,也更贴近真实反思能力。
#15.4 从单条轨迹到搜索树
强 reasoning model 的能力往往不只体现在单条最终 trace,而体现在搜索和分支选择上。
未来可以把 off-policy guidance 从 sequence 扩展到 tree:
- 哪些分支被尝试;
- 哪些分支被剪枝;
- 为什么回退;
- verifier 在哪里介入;
- 最终选择哪条路径。
这会更接近真正的 agentic reasoning / search-guided RL。
#15.5 Agent 任务中的 LUFFY
数学题有 verifier,但 agent 任务也有类似结构:
- 当前模型自己 rollout;
- 强模型或专家 agent 给出轨迹;
- 环境反馈提供 reward;
- 需要在模仿与探索之间平衡。
如果把 LUFFY 推到代码 agent、网页 agent、工具使用 agent,问题会更复杂:
- action 不再是 token,而是工具调用;
- state 是外部环境状态;
- reward 延迟更长;
- off-policy trajectory 可能包含不可复现的环境交互;
- student 偏离 teacher 后,后续轨迹可能完全失效。
但也正因为如此,LUFFY 的思想对 agent RL 很有启发:off-policy guidance 必须和 student 自己的真实状态分布结合,而不是简单 replay teacher trajectory。
#16. 最后总结
这篇论文最值得记住的不是某个公式,而是一个训练哲学:
推理能力既不能只靠自己瞎探索,也不能只靠背高手答案。好的训练应该让模型在自己的探索中接触高手轨迹,把高手轨迹转化为自己可执行、可泛化的策略。
LUFFY 对这个哲学给了一个具体实现:
- 用 RLVR 保持可验证、目标明确的训练信号;
- 用 off-policy reasoning trace 提供超出当前模型能力边界的指导;
- 用 Mixed-Policy GRPO 在 group advantage 中动态平衡 teacher trace 和 student rollout;
- 用 policy shaping 强化低概率但关键的 off-policy action;
- 用 entropy / exploration 避免模型过早塌缩成表面模仿。
从 Think SFT 的角度看,它给出的启示尤其明确:
不要把 <think> 当普通文本背。Reasoning trace 是行为轨迹,是 policy 的展开。训练它时,必须考虑状态分布、探索、反馈、可学习性和泛化。
这也是为什么 LUFFY 这类 off-policy guided RL 方法,很可能会成为 reasoning model 后训练的一条重要路线。