#像给小白一样讲清楚:强化学习到底在解什么数学问题
这篇是对前面那篇“强化学习数学内核”的讲解版。
原文里有几个很深的概念:Bellman 方程、不动点、压缩映射、自举、采样分布漂移、off-policy 发散、RLHF 为什么要拆成两步、GRPO 为什么可以不用 Critic。它们听起来都很数学,但其实背后可以用一个很朴素的问题串起来:
你想知道每一步怎么走才最好,但“这一步好不好”,取决于后面所有步怎么走。
强化学习难就难在这里。它不是简单地给你一堆题和标准答案,让你拟合一个函数。它是在一个会被你自己行动影响的世界里,边探索、边估计、边改变策略。
下面我们从最简单的直觉开始讲。
#1. 先忘掉五元组:强化学习最核心的问题是什么?
教科书通常会先讲 MDP 五元组:
也就是:状态、动作、转移概率、奖励、折扣因子。
但如果你是第一次理解 RL,先不用急着背这些符号。你可以把强化学习想成一个游戏:
我站在某个状态里,可以做几个动作。每个动作会让我进入下一个状态,并得到一点奖励。我想找到一套长期最赚钱的行为方式。
这里最重要的词是“长期”。
比如你玩游戏,眼前有两个动作:
- 动作 A:马上给你 10 分,但后面进入死路;
- 动作 B:现在只给你 1 分,但后面打开一条更好的路线。
如果只看眼前奖励,A 更好。如果看长期,B 可能更好。
所以强化学习不是在问:
当前这个动作能不能马上得分?
它真正问的是:
当前这个动作,会把我带向一个怎样的未来?
于是,“状态值”这个概念就出现了。
#2. 值函数:一个状态到底“值多少钱”?
值函数 可以粗略理解为:
如果我现在在状态 ,从这里继续玩下去,未来一共大概能拿多少分?
注意,它不是“当前状态立刻给我多少奖励”,而是“从这个状态出发,未来所有奖励加起来值多少”。
举个生活化例子。
你现在站在人生的一个节点上:
- 选择读博;
- 选择进大厂;
- 选择创业;
- 选择先休息一段时间。
每个选择的即时收益不一样,未来路径也不一样。一个选择“值多少钱”,不是只看下个月工资,而是看它把你带到什么长期轨道上。
RL 里的状态值也是这个意思。
如果我们知道某个策略 下的值函数,就写成:
意思是:
如果我一直按照策略 行动,那么状态 的长期价值是多少?
如果我们想找最优策略,对应的最优值函数就是:
意思是:
如果我从状态 出发,以后都尽可能聪明地行动,最多能获得多少长期回报?
问题来了:这个 怎么算?
#3. Bellman 方程:答案定义了答案自己
最优值函数满足一个经典方程:
先别被公式吓到。我们一句一句翻译。
左边:
表示“状态 的最优长期价值”。
右边分成两部分:
表示“我在状态 做动作 ,立刻能拿到的奖励”。
表示“做完动作以后,我可能会去到不同的下一个状态 ,这些后续状态也有价值,我把它们按概率加权平均一下”。
最外面的 表示:
我会选择让“当前奖励 + 未来价值”最大的那个动作。
所以 Bellman 方程其实就是一句人话:
一个状态的价值 = 从这个状态出发,选择一个最好的动作,拿到当前奖励,再加上下一个状态的未来价值。
这听起来很合理。但里面藏着一个很绕的地方。
左边有 。右边也有 。
也就是说:
要知道当前状态值多少钱,你得先知道后续状态值多少钱。要知道后续状态值多少钱,你又得知道更后面的状态值多少钱。
这就是原文说的“答案定义了自身”。
它不像普通方程:
你可以直接移项得到 。
Bellman 方程更像:
你要找一本字典里每个词的解释,但每个词的解释又引用了其他词。
如果整本字典引用关系设计得好,你可以反复查、反复修正,最后所有词的解释会稳定下来。这个稳定下来的版本,就是不动点。
#4. 什么是不动点?就是“再算一遍也不变”的答案
不动点这个词听起来抽象,其实很简单。
假设有一个函数 。如果某个点 满足:
那么 就是 的不动点。
“不动”的意思是:你把它丢进函数里,函数处理完以后,吐出来的还是它自己。
比如:
我们找不动点:
解出来:
因为:
所以 2 是这个函数的不动点。
Bellman 方程也是一样。我们可以把 Bellman 更新看成一个算子 :
这里 的意思是:
给我一个当前猜测的值函数 ,我用 Bellman 规则帮你算出一个新的值函数 。
如果某个值函数 满足:
那它就是 Bellman 算子的不动点。
也就是说:
你用 Bellman 规则再更新它一次,它已经不变了。
这就说明它已经自洽了。
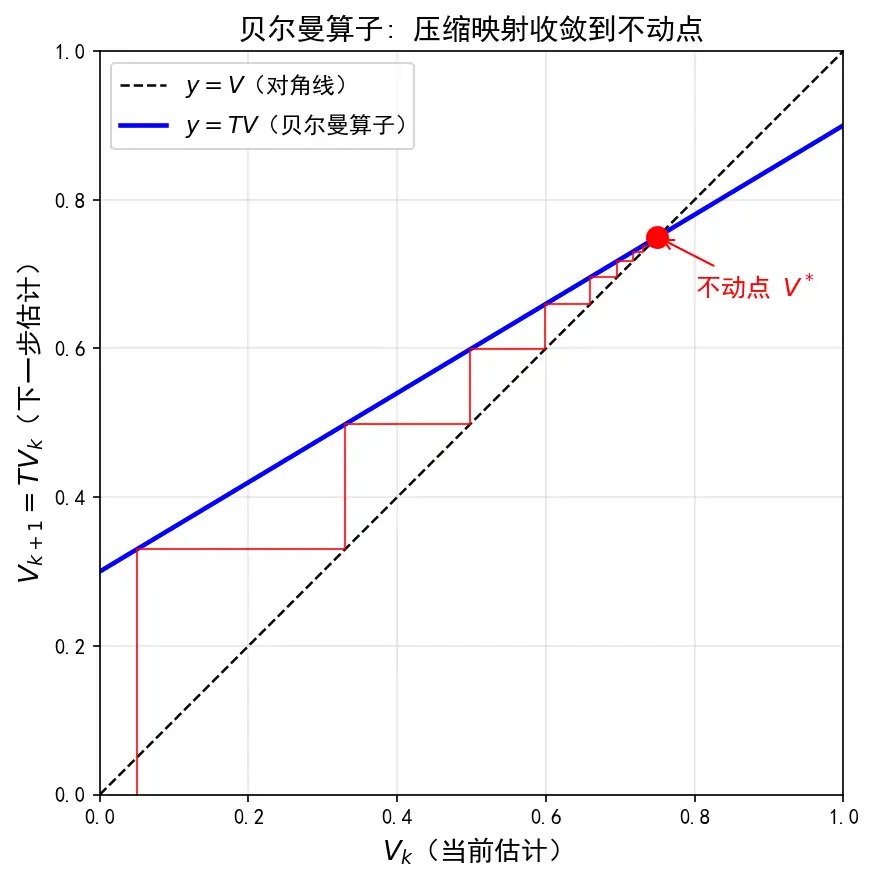
图里的蓝线可以理解成 Bellman 算子 ,黑色虚线是 ,也就是“更新后等于更新前”。
红点是两条线的交点。这个点满足:
所以它就是不动点。
红色阶梯线表示:我们一开始随便猜一个值,然后不断更新:
如果算子足够“温柔”,这些更新会一步步靠近红点。
#5. 压缩映射:为什么反复迭代会收敛?
现在有一个关键问题:
我随便猜一个 ,一直做 ,凭什么最后会收敛到 ?
答案来自巴拿赫不动点定理。
别怕名字。它的直觉很简单:
如果一个操作每做一次,都会把两个不同答案之间的距离缩短,那么反复做下去,所有答案都会被挤到同一个点上。
这就叫压缩映射。
比如你和朋友站在操场两端。每一轮,你们都向对方移动当前距离的一半。第一轮距离缩短一半,第二轮再缩短一半,第三轮继续缩短。虽然理论上你们可能永远还差一点点,但距离会越来越接近 0。
Bellman 算子在折扣因子 时,就是一个压缩映射。更具体地说:
翻译成人话:
两个值函数本来差很多,经过一次 Bellman 更新以后,它们之间的最大差距至少会被乘上 。因为 ,差距会变小。
如果 ,每更新一次,误差最多保留 90%。如果 ,每次最多保留一半。
巴拿赫不动点定理告诉我们:
- 不动点存在;
- 不动点唯一;
- 从任意初始猜测出发,反复迭代都会收敛到它。
这就是动态规划和值迭代的数学地基。
如果你知道完整环境模型 和奖励 ,事情其实很干净:
你已经知道方程的全部系数,只需要反复做 Bellman 更新,把不动点算出来。
这时问题更像动态规划或最优控制,而不是通常意义上的“从经验中学习”。
#6. 强化学习为什么需要“学习”?因为你看不见方程的系数
上面那个理想情况有一个巨大前提:你知道 。
也就是你知道:
在状态 做动作 ,接下来会以多大概率到达每个 。
但真实环境里你通常不知道。
比如自动驾驶车不知道每个动作会导致所有可能路况的精确概率。机器人不知道每个电机控制会让物体以什么概率滑动、旋转、掉落。LLM agent 也不知道自己执行某个工具调用后,外部环境会返回什么状态。
于是 Bellman 方程里的这一项算不出来:
因为你根本不知道 。
那怎么办?
只能采样。
也就是你真的去环境里试一次:
然后用这一次经验近似原来的期望。
这一步看起来很小:只是把“精确求和”换成“样本估计”。
但强化学习的大部分麻烦,就是从这里开始的。
#7. 采样估计:你不是在看完整地图,而是在摸黑踩点
如果模型已知,你就像拿着完整地图:
我知道从每个路口往左、往右、往前分别会以什么概率到哪里,所以我能算出每条路线的长期价值。
如果模型未知,你就像在摸黑走迷宫:
我不知道前面通向哪里,只能先走几步,记录发生了什么,再根据样本更新判断。
TD 学习的核心更新就是:
里面最重要的是这个差值:
它叫 TD error。
人话解释:
我原来以为状态 值 这么多。现在我真的走了一步,发现“即时奖励 + 下一个状态的估计价值”是另一回事。两者的差,就是我这次预测错了多少。
如果 TD error 是正的,说明这个状态比我想的更好,应该把 调高。
如果 TD error 是负的,说明这个状态比我想的更差,应该调低。
学习率 控制你每次改多少。
Robbins-Monro 条件说,学习率最好满足:
这两个条件听起来奇怪,但直觉很漂亮。
第一个条件:
意思是:
你不能太快停止学习。所有步子加起来要足够长,否则还没走到答案附近,你就不动了。
第二个条件:
意思是:
你的步子又必须慢慢变小。否则到了答案附近还一直大步乱跳,会震荡,停不下来。
所以这两个条件合起来就是:
一开始要敢学,后面要稳下来。
这就是随机逼近的基本精神。
#8. 自举:为什么 RL 总是在“用猜测修正猜测”?
原文里说 RL 有“自举循环”。自举,英文是 bootstrap。
它的意思是:
你没有完整答案,只能用当前的半成品答案,去更新另一个半成品答案。
TD 更新就是典型自举:
注意这里的目标值:
里面的 也是你当前估计出来的,不是真正标准答案。
所以你不是拿“标准答案”监督自己,而是拿“另一个还没完全准的估计”监督自己。
这有点像:
一个学生不会做题,于是参考另一个也没完全学会的学生的答案,然后两个人互相改。
如果条件好,他们可以一起越来越接近正确答案。
如果条件不好,他们也可能一起越改越偏。
这就是自举的力量和危险。
#9. 监督学习为什么简单一点?因为数据分布通常不跟着你变
现在我们对比监督学习。
监督学习的典型流程是:
- 给你一批固定数据 ;
- 模型预测 ;
- 计算损失 ;
- 用梯度下降更新参数 。
这里最关键的是:
你更新模型参数,不会改变训练集本身。
你今天训练一轮,明天训练一轮,数据还是那些数据。数据分布大体固定。
当然现实里也有数据漂移、主动学习、在线学习,但标准监督学习的数学设定里,训练分布是外生给定的。
RL 不一样。
在 RL 里,你当前策略 决定你会去哪些状态、采到哪些数据。
策略变了,数据分布就变了。
比如一个游戏 agent:
- 早期策略很菜,只会在新手村附近乱走;
- 学会一点后,开始进入中级地图;
- 再强一点后,进入 boss 区域。
它采到的数据不是固定的。它越强,看到的世界越不一样。
这就是原文说的“采样分布会随着你的解法而改变”。
#10. RL 的三重耦合:估计、评估、优化缠在一起
原文里最关键的一张图是这个:
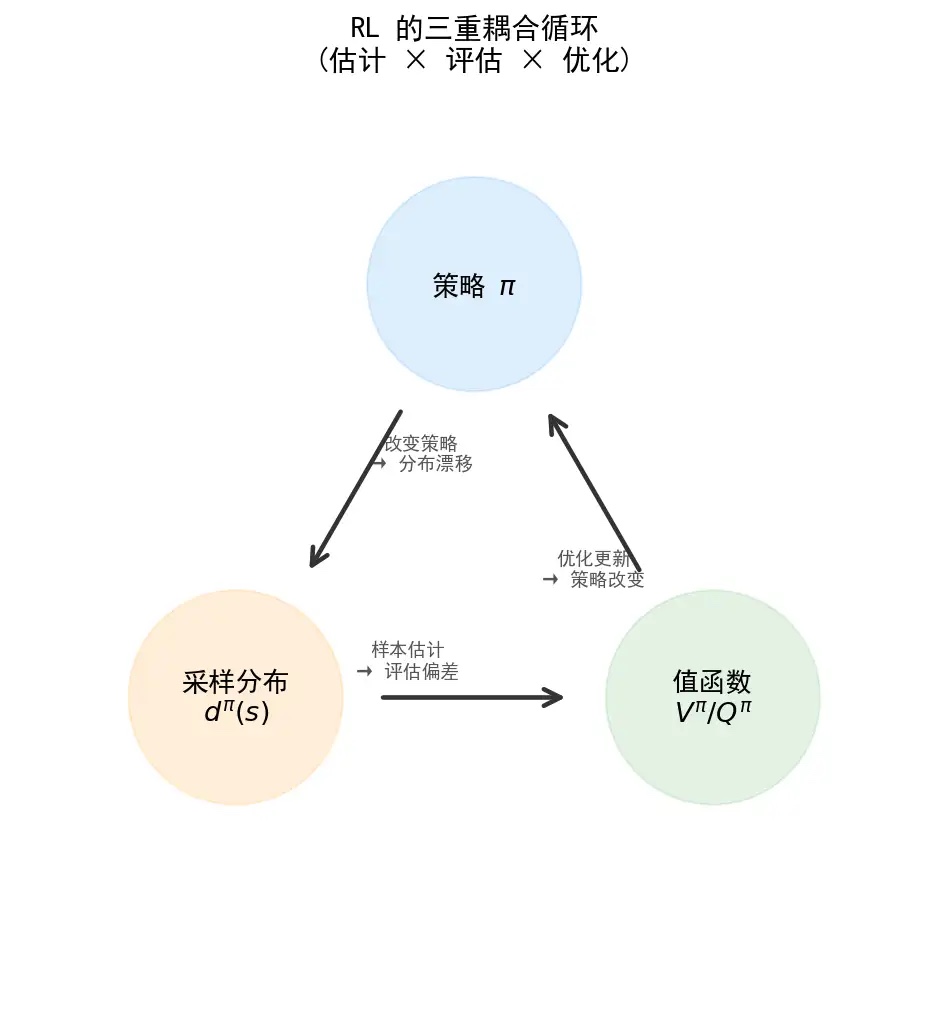
图里有三个东西:
- 策略 :你怎么行动;
- 采样分布 :你会经常遇到哪些状态;
- 值函数 :你认为每个状态或动作值多少钱。
它们形成一个环:
#第一环:策略改变,采样分布改变
你换了策略,就会去不同地方。
比如打游戏时,你从“到处乱走”变成“专门刷高收益副本”,你采到的数据当然就变了。
数学上就是:
策略决定状态访问分布。
#第二环:采样分布改变,估计结果改变
你看到的数据变了,估计出来的值函数也会变。
如果你只在新手村采样,你会以为整个游戏都很简单。如果你只在 boss 区域采样,你会以为整个游戏都很难。
样本不是中立的。样本来自你的策略。
#第三环:值函数改变,策略又改变
你估计某个动作更好,就会更倾向于选它。
策略更新以后,又回到第一环,产生新的数据分布。
所以 RL 是一个闭环:
这就是原文说的三重耦合:
- 估计:用样本估计期望;
- 评估:估计当前策略的价值;
- 优化:用价值更新策略。
在监督学习里,这三件事相对分开。
在 RL 里,它们绑在一起。
#11. “内生性”是什么意思?为什么经济学也遇到同一个问题?
原文提到经济学里的“内生性”。这个词也可以用很简单的话讲。
如果你想研究:
教育年限是否会提高收入?
你可能会发现,读书多的人平均收入更高。
但问题是:读书多可能不是随机发生的。家庭背景、个人能力、城市资源都会影响一个人读多少书,也会影响收入。
也就是说,你想研究 X 对 Y 的影响,但 X 本身不是外部随机给你的,它和很多别的因素纠缠在一起。
这就叫内生性。
RL 也类似。
你想估计某个策略下某个动作的价值,但你采到哪些状态、哪些动作,不是随机中立的,而是由当前策略决定的。
所以数据分布不是“天上掉下来的”,它是你的策略生成的。
这会带来两个问题:
- 你看到的数据有偏;
- 你一改变策略,偏差结构也变了。
经验回放、重要性采样、off-policy correction,本质上都是在处理这个问题。
#12. 为什么说监督学习是固定的山,RL 是活的山?
这张图很形象:
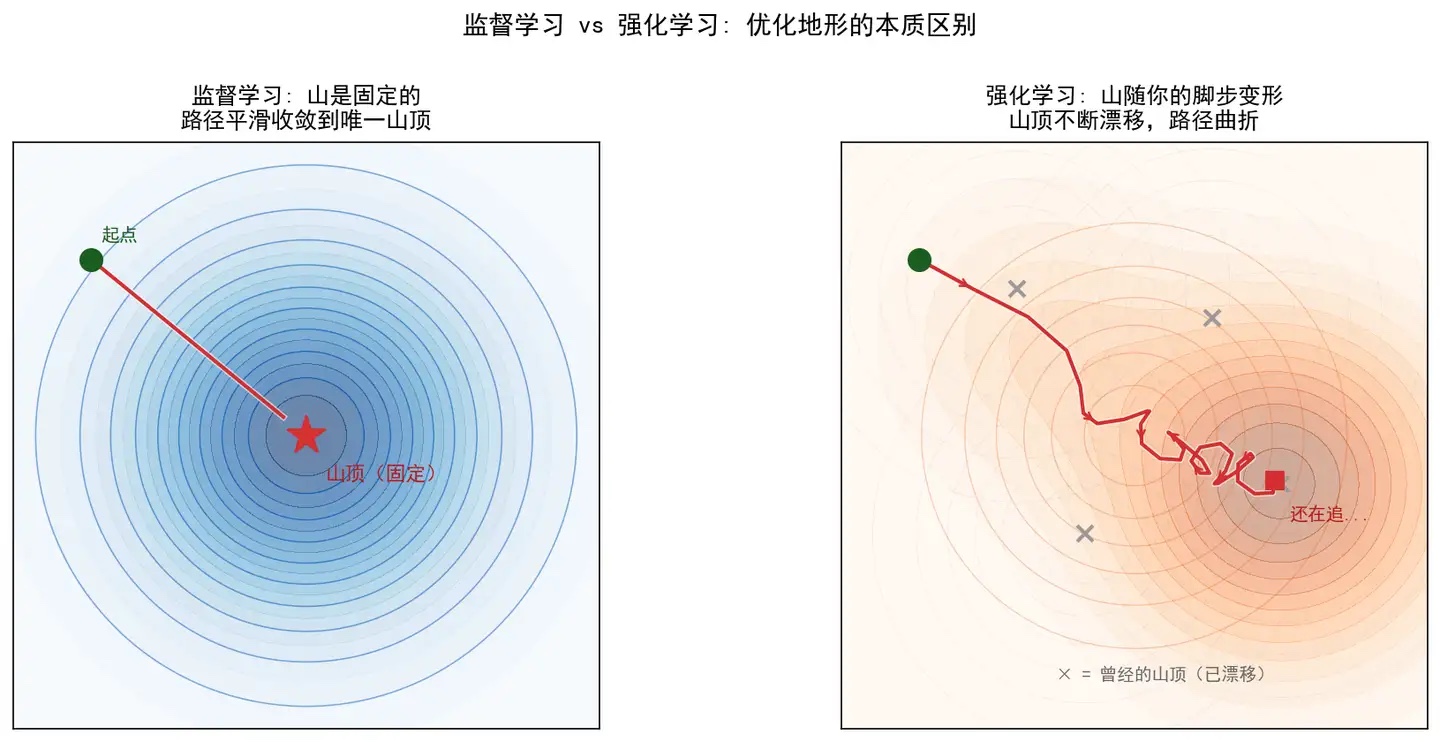
监督学习里,损失函数通常可以想成一座固定的山或谷。
你的目标是找到最低点或最高点。虽然优化也可能很难,但至少地形本身不因为你走了一步就改变。
RL 里更像这样:
你每走一步,脚下的地形会发生变化;你原来以为的山顶,可能因为策略改变和数据分布改变,看起来又移到了别处。
严格说,在固定 MDP 里,真正的最优值函数 和最优策略 并没有变。变的是你看到的数据分布、估计误差、优化方向和当前近似出来的目标。
所以更严谨的说法是:
不是最终答案真的每一步都变,而是你每一步用来逼近答案的经验分布和估计目标在变。
这个区别很重要。
比喻可以说“山在变”,但数学上要知道:
- 真实环境如果固定,最优解是固定的;
- 你在学习过程中看到的“经验版地形”会变。
这就够解释 RL 为什么难了。
#13. 四条路线:大家都在想办法打破自举循环
原文说,RL 七十年的发展史可以看成四种打破自举循环的路线。
这张图总结得很好:
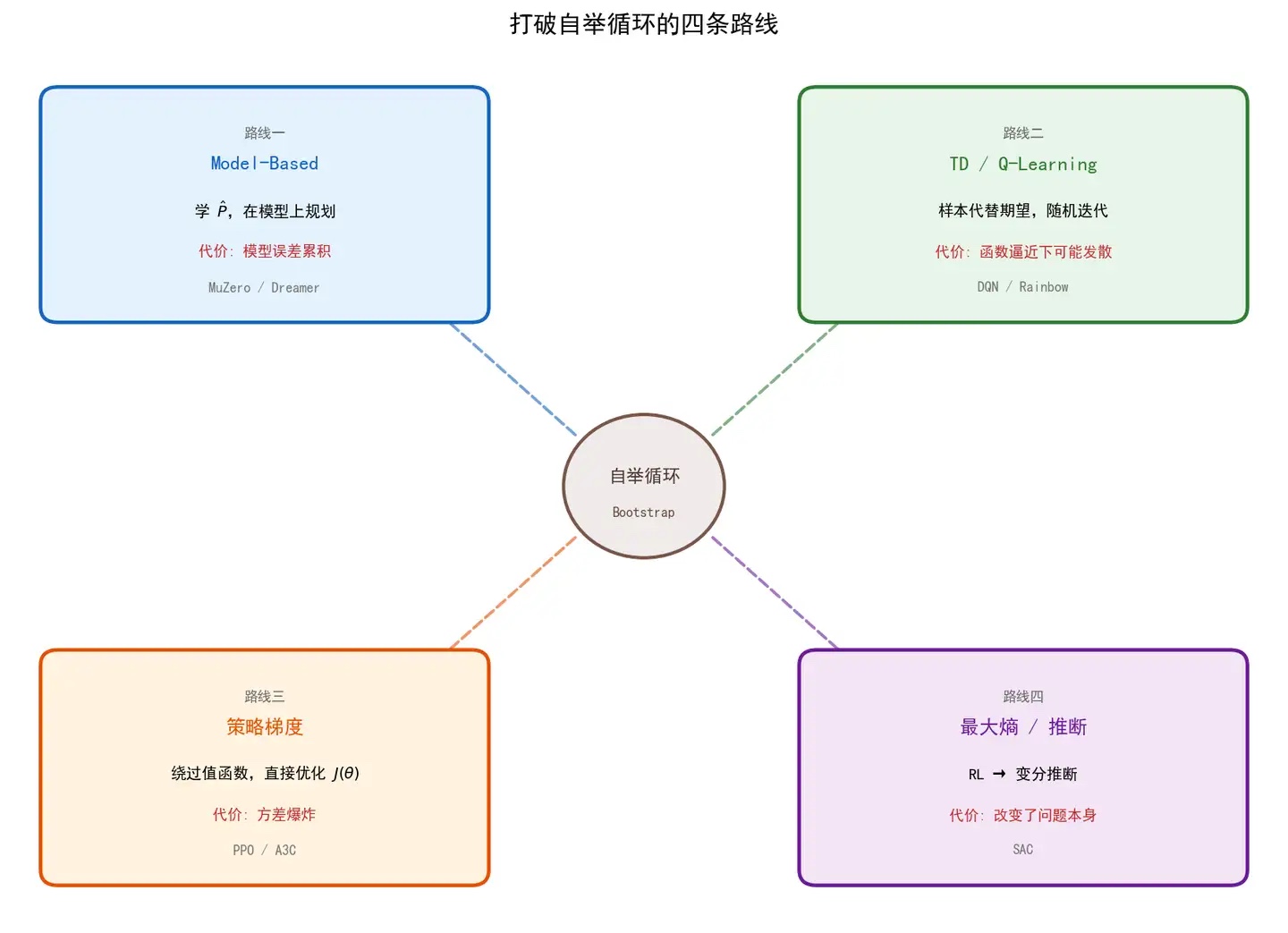
下面逐条用小白版解释。
#14. 路线一:Model-Based RL,先学一张地图
第一条路线是:
既然我不知道环境模型 ,那我先学一个近似模型 。
也就是先用数据学出一张“世界地图”。
然后在这张地图上做规划。
这就是 model-based RL。
它的流程是:
- 从环境里采样,收集很多转移:;
- 学一个模型 ,预测做某个动作会到哪里;
- 在 上跑 Bellman 更新或规划;
- 得到策略。
这听起来很自然。
就像你要去一个陌生城市,可以选择:
- 不画地图,边走边试;
- 先画一张地图,再在地图上规划路线。
MuZero、Dreamer 都有这个味道。它们不是只记住“这个动作好不好”,而是试图学一个内部世界模型,然后在里面想象未来。
但代价是模型误差。
如果你的地图画错了,你在地图上规划得越精细,可能错得越离谱。
原文里那句话很关键:
你可能在解一个“错误方程的精确解”,而你真正需要的是“正确方程的近似解”。
这句话是什么意思?
如果 和真实 有偏差,那么你在 上算出的最优策略,只是“假世界里的最优策略”。
它未必在真实世界里最优。
所以 model-based RL 的核心矛盾是:
有模型以后可以规划得更远,但规划越远,模型误差也越容易累积。
#15. 路线二:TD / Q-learning,不学地图,直接用样本更新
第二条路线是:
我不显式学习 。我直接拿真实采样来近似 Bellman 更新。
这就是 TD learning 和 Q-learning。
Q-learning 的典型更新是:
翻译一下:
我原来以为在 做 的价值是 。现在我真的做了一次,得到了奖励 ,并到了 。如果下一步从 开始选最好的动作,那么新的目标值应该是 。我把旧估计往这个新目标挪一点。
它的厉害之处是:
不需要知道完整转移概率,只需要真实采样。
在表格型、小规模、充分探索、学习率合适的情况下,它可以收敛。
但一到深度学习,事情变复杂。
因为我们不再给每个状态动作对存一张表,而是用神经网络近似 。
这就引入了“三件危险物品”:
- 函数逼近;
- 自举;
- off-policy 数据。
这三个东西单独看都能处理,但放在一起会出问题。
Baird 1995 年的反例说明,即使是线性函数逼近,在 off-policy TD 下也可能发散。
DQN 为什么要用经验回放和目标网络?
可以这么理解:
- 经验回放:让数据分布别变化得太剧烈,打散时间相关性;
- 目标网络:让 bootstrap 的目标别每一步都跟着当前网络乱动。
它们不是从根上消灭问题,而是给不稳定的自举过程加了两个减震器。
#16. 路线三:策略梯度,直接改策略
第三条路线是策略梯度。
它的想法是:
我不一定要先精确求出最优值函数。能不能直接调整策略参数,让长期回报变大?
我们把策略写成:
意思是:参数为 的策略,在状态 下选择动作 的概率。
目标是最大化:
也就是这个策略采样出来的轨迹,总回报期望尽量大。
策略梯度定理给出:
这条公式人话解释是:
如果某个动作后续回报高,就提高以后在类似状态下选这个动作的概率;如果某个动作回报低,就降低它的概率。
它绕过的是“必须先解 Bellman 最优方程再改策略”这条路。
但它没有完全绕过值函数。因为公式里还有 ,也就是动作价值。
策略梯度最大的问题是方差大。
为什么?
因为你要靠采样出来的轨迹判断某个动作好不好。但一条轨迹的结果可能受很多随机因素影响。
比如你训练一个游戏 agent,一局得分高,不一定是因为某个动作真的好,可能只是这局运气好。反过来也一样。
所以纯 Monte Carlo 策略梯度会很吵,样本效率低。
Actor-Critic 就是折中:
- Actor:负责更新策略;
- Critic:估计值函数,用来降低策略梯度的方差。
你可以理解成:
Actor 负责行动,Critic 负责打分和校准。
策略梯度原本想绕开值函数,但为了降噪,又把值函数请回来做辅助。
#17. 路线四:最大熵 RL,把控制问题改写成推断问题
第四条路线更抽象一点:最大熵 RL / control-as-inference。
普通 RL 问:
哪个策略能最大化奖励?
最大熵 RL 问:
哪个策略既能拿高奖励,又不要太早变得死板?
它在目标里加了熵:
熵 可以理解为“随机性”或“多样性”。
如果策略在某个状态下只会做一个动作,熵低。
如果策略会保留多个可能动作,熵高。
为什么要加熵?
因为在探索阶段,过早确定一个动作可能会陷入局部最优。加熵相当于鼓励策略保留探索空间。
SAC 就是最大熵 RL 的代表算法。
更深一层看,control-as-inference 把 RL 改写成概率推断问题:
哪些轨迹更像“高奖励轨迹”?我们能不能在轨迹空间里推断出这些好轨迹对应的策略?
这样一来,值函数像能量函数,策略像玻尔兹曼分布,Bellman 更新像消息传递。
这条路的好处是数学优雅,可以借用概率图模型和变分推断的工具。
代价是:
你改变了原问题。
普通 RL 追求的是奖励最大。最大熵 RL 追求的是“奖励 + 熵”最大。
这两个目标很接近,但不是完全一样。
你用一点最优性,换来了更稳定的探索和更好优化性质。
#18. RLHF 为什么要拆成两步?它是在降低耦合
现在看 RLHF。
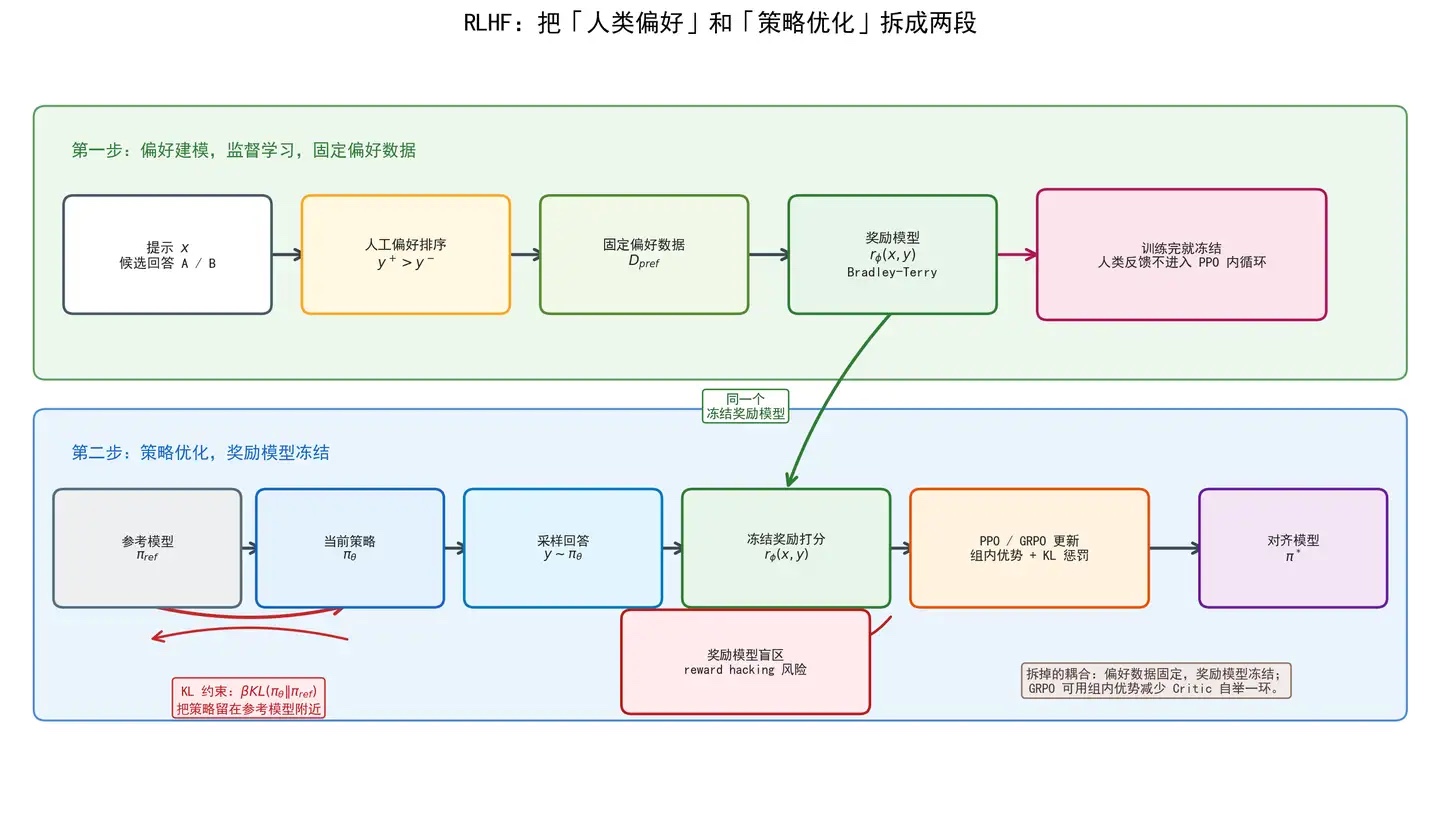
RLHF 的核心不是“把人类放进 RL 循环里实时打分”。恰恰相反,它通常会把人类偏好和策略优化拆开。
第一步:偏好建模。
给定一个 prompt ,模型生成两个回答 ,人类标注哪个更好:
然后训练一个奖励模型:
这个奖励模型学的是:
人类大概更喜欢什么样的回答?
这一步是监督学习。数据集是固定的,人类偏好标签是固定的,训练目标也相对清楚。
第二步:策略优化。
冻结奖励模型,用 PPO 或 GRPO 优化当前语言模型策略 。
也就是让模型生成回答 ,再用冻结的 打分。
然后更新 。
为什么要冻结奖励模型?
因为如果奖励模型也在 PPO 内循环里不断变化,那策略、数据分布、奖励信号会一起漂移,训练会更不稳定。
RLHF 的聪明之处在于:
先把“人类偏好”压缩成一个固定奖励模型,再在这个固定奖励模型上做 RL。
它没有消灭 RL 的耦合,但减少了一层耦合。
#19. KL 惩罚:为什么要把模型拴在参考模型附近?
RLHF 里常见一个 KL 项:
这个式子看起来复杂,其实意思很直白:
你可以为了拿高奖励改变策略,但不要离原来的参考模型太远。
为什么?
因为奖励模型只在某个数据分布上训练过。
如果策略跑得太远,生成一堆奖励模型没见过的奇怪回答,奖励模型可能会被欺骗。
这就是 reward hacking。
比如奖励模型学到“回答越长越详细越好”,策略可能就开始疯狂输出长篇废话。
它不是真的更符合人类偏好,而是在钻奖励模型的漏洞。
KL 惩罚的作用就是:
把策略限制在参考模型附近,别让它跑到奖励模型的盲区里。
这有点像你让学生自由发挥,但不能偏离题目太远。
#20. GRPO 为什么可以不用 Critic?它省掉了哪一环?
PPO 通常需要一个 Critic 来估计值函数,然后计算 advantage。
Advantage 可以理解成:
这个回答比平均水平好多少?
如果只看绝对奖励,有时候不好判断。
比如某个题本身就难,所有回答得分都低;另一个题很简单,所有回答得分都高。你需要知道“在同一组候选里,它相对好不好”。
GRPO 的思路是:
对同一个 prompt 采样一组回答,用组内平均和标准差做归一化,直接得到相对优势。
也就是不额外训练一个 Critic 网络,而是用同组样本的相对得分来估计 advantage。
粗略写成:
人话解释:
同一道题里,谁比同组其他回答更好,就提高它的概率;谁更差,就降低它的概率。
这样做的好处是:
- 少训练一个 Critic;
- 少一个值函数自举误差来源;
- 训练系统更简单。
但要注意,GRPO 没有消灭 RL 的所有耦合。
策略还是会改变采样分布。奖励模型还是可能有盲区。KL 约束仍然重要。
更准确地说:
GRPO 拿掉的是 Critic 这条自举链路,不是拿掉整个 RL 闭环。
#21. 把所有概念连起来:RL 到底在做什么?
现在我们把前面讲过的东西串起来。
强化学习的理想数学形式是 Bellman 不动点方程:
如果你知道完整 MDP,Bellman 算子是压缩映射,值迭代会收敛到唯一不动点。
但真实 RL 里,你不知道转移概率 ,所以无法精确计算 Bellman 更新。
你只能采样。
采样又不是固定分布下的采样,而是由当前策略 决定的。
于是形成闭环:
这就是 RL 的核心困难。
它不是单纯“状态空间大”。
它不是单纯“奖励稀疏”。
它也不是单纯“神经网络不好调”。
这些都很难,但更底层的结构是:
你在用当前策略生成的数据,估计当前策略或最优策略的价值,再用这个估计去改变策略。下一轮,你的数据分布又变了。
这就是自指、自举和分布漂移纠缠在一起。
#22. 用一句话区分监督学习和强化学习
监督学习像这样:
题目和标准答案都放在桌上,你训练一个模型去拟合它们。
强化学习像这样:
你在一个未知世界里行动,行动会改变你接下来能看到什么;你要从这些被自己行动影响的数据里,反推出怎样行动才最好。
监督学习的难点主要是拟合函数。
强化学习的难点是:
数据从哪里来,本身就是你要学习的策略决定的。
这也是为什么原文说:
监督学习是在固定地形上爬山;RL 是在一块会被你的脚步踩变形的地面上找最高点。
但我们现在可以把这句话说得更精确一点:
最高点未必真的在动。真正动的是你看到的样本、你估计出来的地形、以及你下一步更新策略的方向。
#23. 如果数学不强,应该抓住哪几个关键词?
如果你暂时不想陷入公式,抓住下面几个关键词就够了。
#1. 值函数
状态或动作的长期价值,不是眼前奖励。
#2. Bellman 方程
当前价值 = 当前奖励 + 未来价值。
这是一种递归定义。
#3. 不动点
更新前后不再变化的自洽解。
#4. 压缩映射
每次更新都会缩小误差,所以反复迭代能收敛。
#5. 采样估计
真实环境模型未知,只能靠一次次交互样本近似期望。
#6. 自举
用当前估计出来的值,去更新另一个估计。
#7. 分布漂移
策略变了,采到的数据也变了。
#8. 三重耦合
估计、评估、优化互相影响,不能像监督学习那样完全拆开。
#9. KL 约束
在 RLHF 中,限制策略别离参考模型太远,避免钻奖励模型漏洞。
#10. GRPO 的组内优势
不用额外 Critic,而是在同一 prompt 的多个回答之间做相对比较。
#24. 和 LLM Agent / 长轨迹 RL 有什么关系?
这套理解对 LLM Agent 很重要。
因为 LLM Agent 的轨迹通常很长:
- 读题;
- 规划;
- 调工具;
- 观察返回;
- 修改计划;
- 再调工具;
- 最后输出答案。
这里的每一步都会改变后续上下文和可见状态。
如果直接对整条长轨迹做 RL,会遇到几个问题:
- credit assignment 很难:最后成功或失败,到底是哪一步造成的?
- 采样成本很高:完整 rollout 很贵;
- 分布漂移严重:策略稍微变一点,后面的上下文分布就完全不同;
- 自举目标不稳定:如果再引入 value model,Critic 自己也可能学不稳。
所以你最近关心的 model-based RL、Dreamer for LLM Agent、latent-space reasoning,其实都可以放回这条主线理解:
能不能不要每次都在真实环境里 rollout 到底?能不能学一个世界模型、潜空间模型或压缩状态,在内部推演未来?
这就是 model-based 路线在 LLM Agent 上重新变得重要的原因。
对于长轨迹 agent,直接做 model-free RL 可能样本效率太低、方差太大、分布漂移太猛。
如果能学到一个足够好的内部模型,就可以在潜空间里做规划、评估和反事实比较。
当然,代价还是那句话:
你可能在一个错误模型里规划得很聪明。
所以关键问题变成:
- 世界模型怎么学?
- 模型误差怎么控制?
- 长轨迹中的状态怎么压缩?
- 哪些信息必须保留,哪些可以丢掉?
- 内部推演和真实环境反馈怎么结合?
这些问题其实都从 Bellman 不动点和采样分布耦合一路延伸出来。
#25. 最后用一个故事收束
想象你在一个陌生城市找最赚钱的路线。
如果你有完整地图,知道每条路通向哪里、每个地点能赚多少钱,那么你可以坐在桌前做动态规划。你不需要学习,只需要计算。
但真实 RL 不是这样。
你没有地图。你只能出门走。
你走到哪里,取决于你当前的策略。你看到什么数据,也取决于你当前的策略。你根据看到的数据更新判断,又会改变下一次怎么走。
所以你不是在固定地图上找最短路。
你是在边走边画地图,边画地图边改路线,边改路线又改变你接下来能看到的城市区域。
这就是强化学习。
它在解一个不动点方程,但看不见完整方程。它靠采样逼近期望,但采样分布由当前策略决定。它用当前估计更新策略,而策略又改变下一轮估计的数据来源。
监督学习的问题通常是:
给定数据,怎么学得更准?
强化学习的问题是:
数据由我的行为产生,而我的行为又要靠这些数据来改。我该怎么在这个闭环里稳定地变好?
理解了这句话,Bellman 方程、不动点、压缩映射、自举、经验回放、策略梯度、RLHF、GRPO,其实都不再是孤立概念。
它们都是围绕同一个核心困难展开的不同解法:
如何在一个由自己行动塑造的数据世界里,稳定地逼近长期最优行为。