#Mixture-of-Transformers(MoT)架构详解:把多模态大模型从“一个脑子硬扛所有模态”改成“按模态分工的 Transformer 混合体”
这篇文章讲的是 Meta 这篇论文:Mixture-of-Transformers: A Sparse and Scalable Architecture for Multi-Modal Foundation Models,arXiv:2411.04996,已发表于 TMLR 2025。
论文链接:<https://arxiv.org/abs/2411.04996>
代码/Playbook:<https://github.com/facebookresearch/Mixture-of-Transformers>
一句话概括:
MoT 想解决的是多模态基础模型预训练越来越贵的问题。它不是让一个 Dense Transformer 同时学文本、图像、语音,也不是只在 FFN 里加 MoE;而是把 Transformer 的非 embedding 参数按模态拆开:文本 token 走文本 Transformer 参数,图像 token 走图像 Transformer 参数,语音 token 走语音 Transformer 参数,但它们仍然在同一个序列里做全局 self-attention,从而既保留跨模态交互,又减少每个 token 实际激活的计算。
更人话一点:
Dense 多模态 Transformer 像让一个老师同时教语文、绘画、音乐,而且所有学生上同一套课。MoE 像在课堂里加很多助教,但还要学一个复杂路由器来决定每个 token 找谁。MoT 则更直接:文本、图像、语音各自有自己的专业老师;但学生们还坐在同一个教室里,可以互相看见、互相交流。
#1. 为什么需要 MoT:多模态不是“把所有 token 拼一起”就完了
现在多模态基础模型常见做法是把不同模态都 token 化,然后拼成一个序列:
文本 token + 图像 token + 语音 token + ...
比如 Chameleon 一类原生多模态模型,会把图像离散化为 image tokens,然后和 text tokens 一起做 autoregressive next-token prediction。Transfusion 一类模型则更进一步:文本用自回归目标,图像用 diffusion-style objective。形式上看,所有东西都变成 token 了,好像只要一个 Transformer 就能统一建模。
但问题在于:token 形式统一,不代表计算需求统一。
文本、图像、语音在至少三个层面都很不一样:
- 统计结构不同:文本是离散符号序列,图像 token 背后有强空间结构,语音 token 又有连续时间信号的影子。
- 优化动态不同:同一个 dense model 同时优化不同模态时,不同模态的 loss 下降速度、泛化表现、梯度需求可能互相冲突。
- 计算占比不同:图像通常需要大量 tokens,例如一张图可能 1024 个离散 token;多模态预训练的数据量和序列长度都比纯文本更重。
论文的一个重要观察是:即使 Dense Transformer 没有显式告诉模型“这是文本、这是图像、这是语音”,不同模态在隐空间里也会自然分开。这说明模型内部其实已经在学习不同模态的不同处理方式,只是 Dense 架构强迫它们共享同一套参数。

所以 MoT 的出发点不是“能不能多模态统一”,而是:
既然不同模态本来就有不同处理模式,为什么还要让它们强行共用同一个 Transformer 参数?
#2. MoT 的核心思想:按模态解耦 Transformer,而不是只解耦 FFN
普通 Transformer layer 可以粗略写成:
attention output = Attn(x; θ_attn)
h = x + Norm(attention output)
output = h + Norm(FFN(h; θ_ffn))
Dense 多模态 Transformer 的问题是:无论 token 来自文本、图像还是语音,都使用同一套 θ_attn、θ_ffn、LayerNorm 参数。
MoT 改成:
如果 token 是 text: 用 text-specific attention / FFN / norm 参数
如果 token 是 image: 用 image-specific attention / FFN / norm 参数
如果 token 是 speech: 用 speech-specific attention / FFN / norm 参数
论文说得更精确一点:MoT 按模态解耦所有 non-embedding parameters,包括:
- feed-forward networks;
- attention matrices;
- layer normalization;
- 其他非 embedding 的 Transformer 参数。
但关键点是:MoT 不是把不同模态完全切成互不交流的多塔模型。
它仍然保留 global self-attention over the full input sequence。也就是说,文本 token、图像 token、语音 token 仍然在同一个上下文序列里互相 attend,只是每个 token 在计算 Q/K/V、FFN、Norm 等变换时,使用自己模态对应的参数。
可以把它理解成:
共享的东西:序列上下文、全局注意力的信息流、跨模态可见性
不共享的东西:每个模态对 token 进行变换的参数
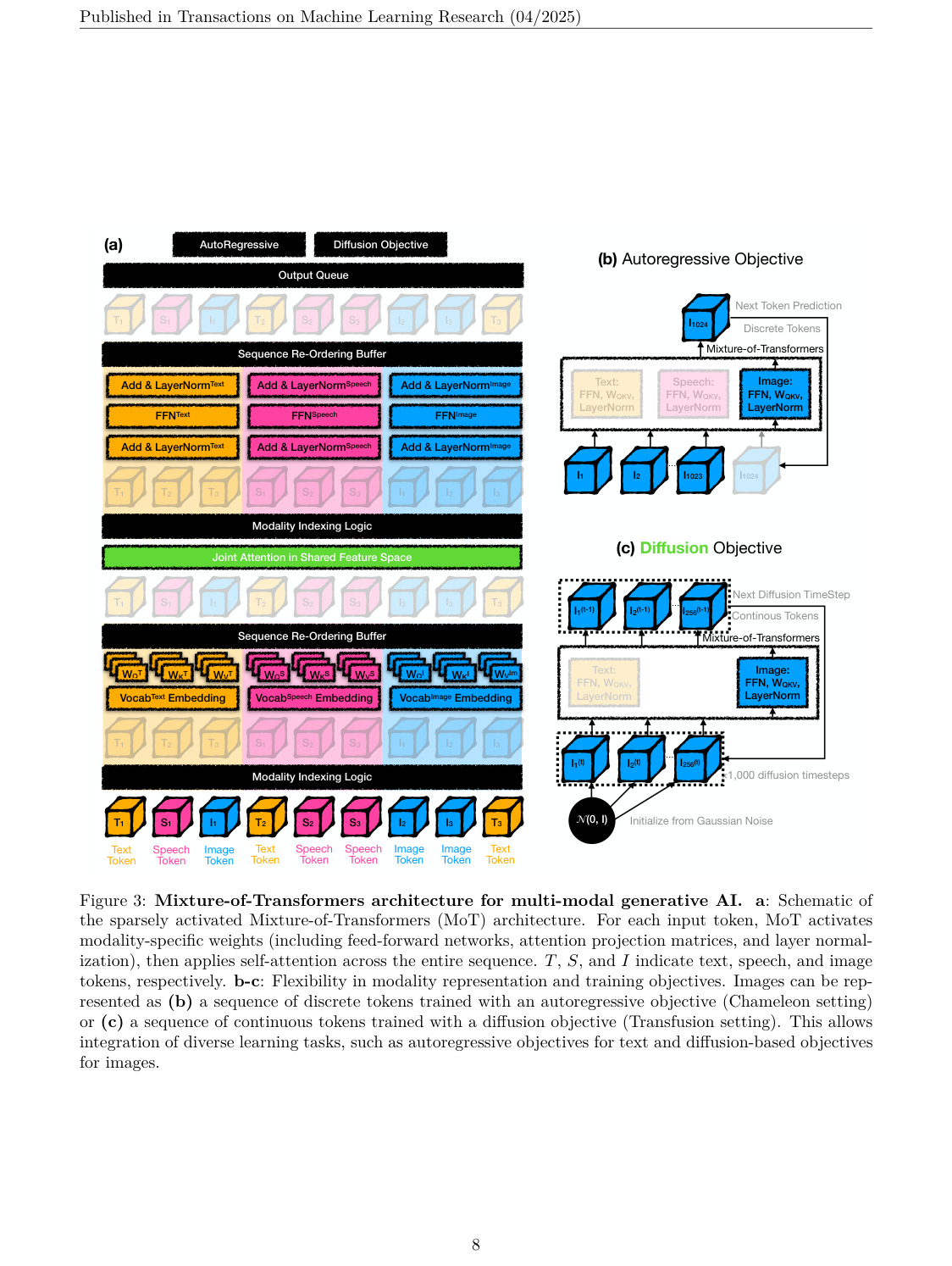
这就是 MoT 最重要的设计张力:
参数是分模态的,注意力上下文是全局的。
如果只看“分模态参数”,它像多塔;如果只看“全局序列 attention”,它像统一 Transformer。MoT 的价值正在于它夹在二者之间:既不完全共享,也不完全隔离。
#3. MoT 和 MoE 到底有什么不同?
名字上 MoT 很容易让人联想到 MoE,但二者的稀疏性来源不一样。
#3.1 MoE:token 通过 learned router 找专家
典型 MoE Transformer 主要是在 FFN 层做稀疏化:
token -> router -> top-k FFN experts -> combine
优点是可以增加总参数量,同时每个 token 只激活少数专家。问题也很明显:
- router 要学习;
- 专家负载可能不均衡;
- 训练早期 router 和 experts 都没学好,容易不稳定;
- autoregressive generation 下某些 routing 方法还会遇到因果性或推理实现问题;
- 大规模系统里通信和 load balancing 成本很复杂。
#3.2 MoT:routing rule 是模态本身
MoT 的路由不需要模型猜。token 属于哪个模态是已知的:
text token -> text transformer parameters
image token -> image transformer parameters
speech token -> speech transformer parameters
这是一种 rule-based modality routing。它没有 learned router,也没有复杂的 expert load balancing。模态本身就是路由标签。
这带来两个直接好处:
- 训练更稳:不用同时训练 router 和 experts,也不用担心 router 早期把 token 分错。
- 语义更清楚:每个 expert 不是抽象专家,而是一个明确的 modality-specific transformer tower。
#3.3 MoT 解耦得比常见 MoE 更彻底
很多多模态 MoE 工作只在 FFN 层做 modality-aware sparsity。MoT 更激进:它把 attention、FFN、LayerNorm 等非 embedding 参数都按模态拆开。
所以 MoT 不是:
共享 attention + modality-specific FFN
而更像:
modality-specific attention + modality-specific FFN + modality-specific norm
但注意,它不是每个模态单独做自己的 self-attention;它仍然在完整序列上做全局注意力,只是不同模态 token 使用不同模态的 attention 参数。
#4. MoT 和多塔 / cross-attention 多模态模型有什么不同?
很多早期多模态模型采用 late fusion 或 cross-attention:
图像 encoder 单独编码图像
文本 LLM 单独处理文本
中间用 adapter / cross-attention 连接
这种做法训练轻、复用强,但它更像“把外部视觉模块接到语言模型上”,天然更适合多模态理解,不一定适合原生多模态生成。
MoT 走的是另一条路:
- 所有模态都在同一个 token 序列里;
- 模型可以做原生 text-image-speech 生成;
- 不同模态有自己的参数路径;
- 跨模态交互不是靠单独的 cross-attention 模块,而是在全局 self-attention 中发生。
这使得 MoT 更接近“原生多模态 foundation model”的路线,而不是“LLM + vision encoder + adapter”的路线。
#5. 三个实验设定:MoT 不是只在一个 setting 上有效
论文验证了三个层次的多模态训练设定。
#5.1 Chameleon setting:文本 + 图像,统一自回归目标
第一个设定类似 Chameleon:文本和图像都被离散 token 化,用 autoregressive objective 训练。
text tokens + image tokens -> next-token prediction
在 7B 模型上,MoT 的核心结果是:
MoT 用 55.8% 的 FLOPs 就能匹配 Dense 7B baseline 的最终表现。
论文报告中,MoT 在 60k steps 左右就匹配 Dense model 120k steps 的 final loss。换句话说,在这个 setting 下,同等质量所需训练计算大约减少 44.2%。
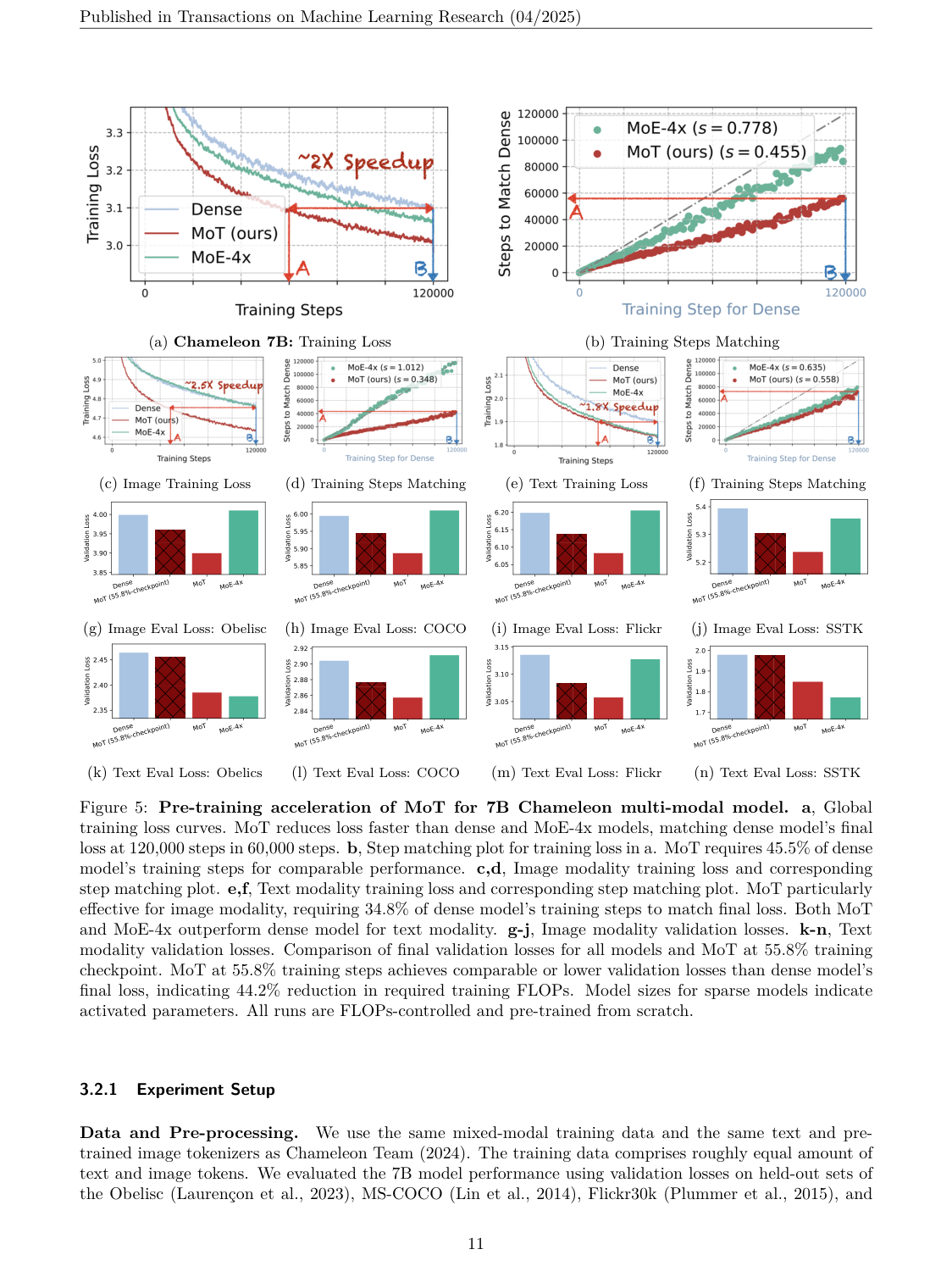
这里要注意:MoT 不是简单用更多总参数换性能。它关注的是 activated FLOPs:每个 token 只激活自己模态对应的 Transformer 参数,因此实际计算可以明显下降。
#5.2 Chameleon + Speech:加入第三模态
第二个设定把语音也离散化为 tokens,形成 text + image + speech 三模态训练。
结果更有意思:
MoT 达到 Dense baseline 的 speech performance 只需要 37.2% 的 FLOPs。
这说明随着模态数增加,MoT 的优势可能更明显。原因很直观:Dense Transformer 要让所有模态共享同一套参数,模态越多,冲突和浪费越严重;MoT 则允许每个模态有自己的处理路径,新增模态不会强迫所有 token 都经过同一套参数。
#5.3 Transfusion setting:文本自回归 + 图像 diffusion objective
第三个设定更接近现实多目标训练:文本用 autoregressive objective,图像用 diffusion-based objective。这个 setting 比“所有 token 都 next-token prediction”更复杂,因为不同模态不只是数据分布不同,训练目标也不同。
这里 MoT 的结果很强:
- 7B MoT 在图像模态上用不到三分之一 FLOPs 匹配 Dense baseline;
- 760M MoT 使用 1.4B Dense baseline 一半的训练/推理 FLOPs,却在多个图像生成指标上超过后者;
- 论文给出的指标包括 CLIP score、FID、CIDEr 和 image modality training loss。
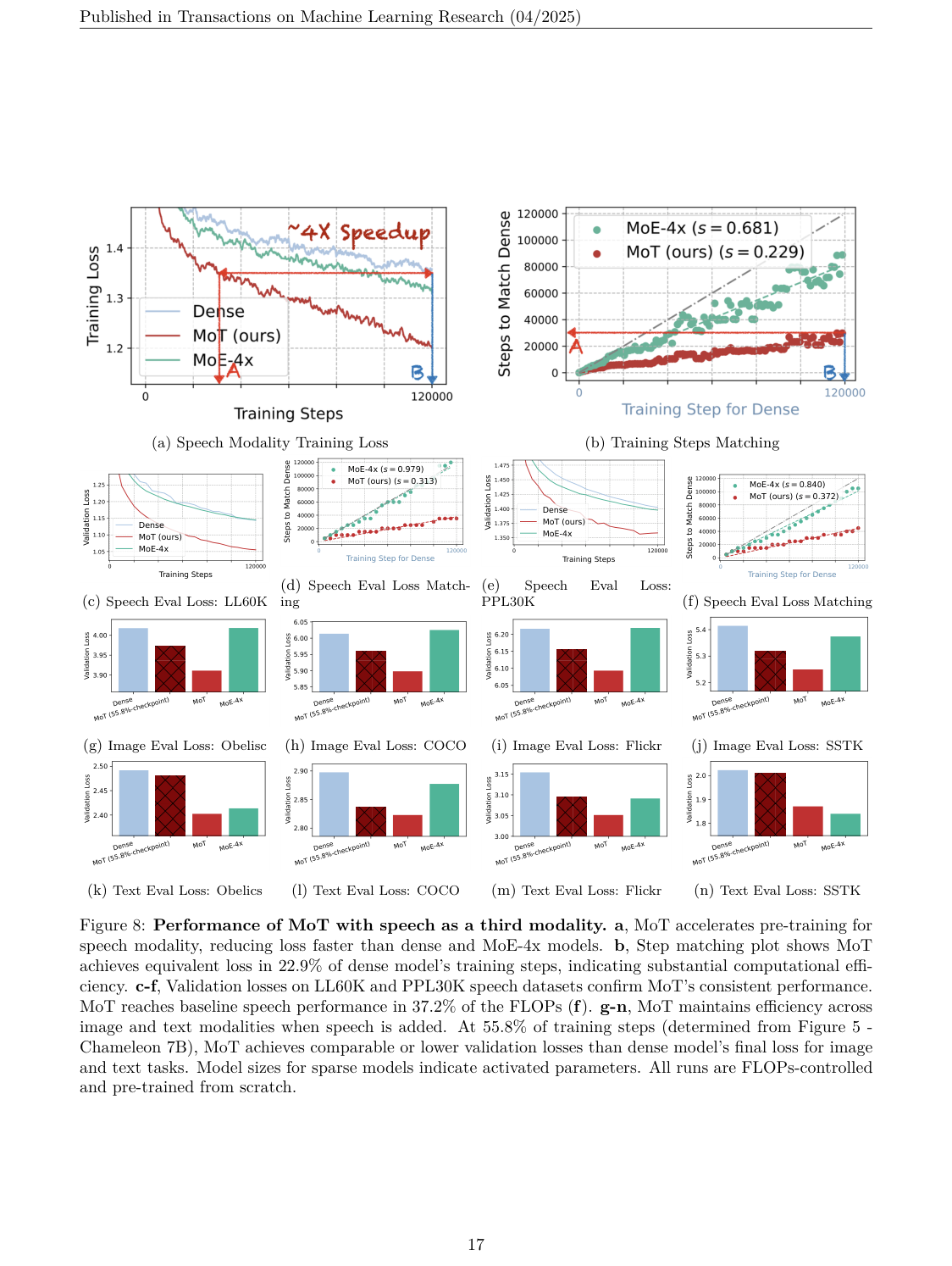
这说明 MoT 的意义不只是“更省训练步数”,而是:当不同模态使用不同 objective 时,分模态 Transformer 参数可以减少目标之间的干扰。
#6. 为什么 MoT 会有效:模态之间既要交流,也要隔离
我认为 MoT 的核心直觉可以概括成一句话:
多模态学习需要共享语义上下文,但不一定需要共享所有底层变换参数。
文本、图像、语音当然要对齐。例如图像里的猫、文本里的 “cat”、语音里的 “cat” 应该在高层语义上关联起来。但这并不意味着它们在每一层 Transformer 里都应该用同一套 attention projection、FFN 和 normalization。
Dense Transformer 的问题是过度共享:
所有模态共享所有非 embedding 参数
多塔模型的问题是过度隔离:
不同模态先各自处理,后面再融合
MoT 的折中是:
模态内部变换分开,跨模态上下文共享
这和人脑/专家系统的直觉也更像:视觉处理和语言处理有专业化通路,但高层任务需要跨通路整合。
#7. 消融:到底哪些部分需要按模态拆?
论文专门做了 modality untying 的消融,比较只拆 FFN、拆 attention、拆 LayerNorm,以及完整 MoT 的效果。
结论不是“随便拆一点就行”,而是:
只在 FFN 上做 modality-specific 不够;MoT 的优势来自更完整的 transformer-level modality untying。
尤其在三模态 setting 中,论文还做了 Modality Leave-One-Out(LOO)分析:拿掉某个模态的专属路径,看其他模态性能怎样变化。这个分析说明不同模态确实会形成功能上有差异的 processing tower,而不是纯粹参数冗余。
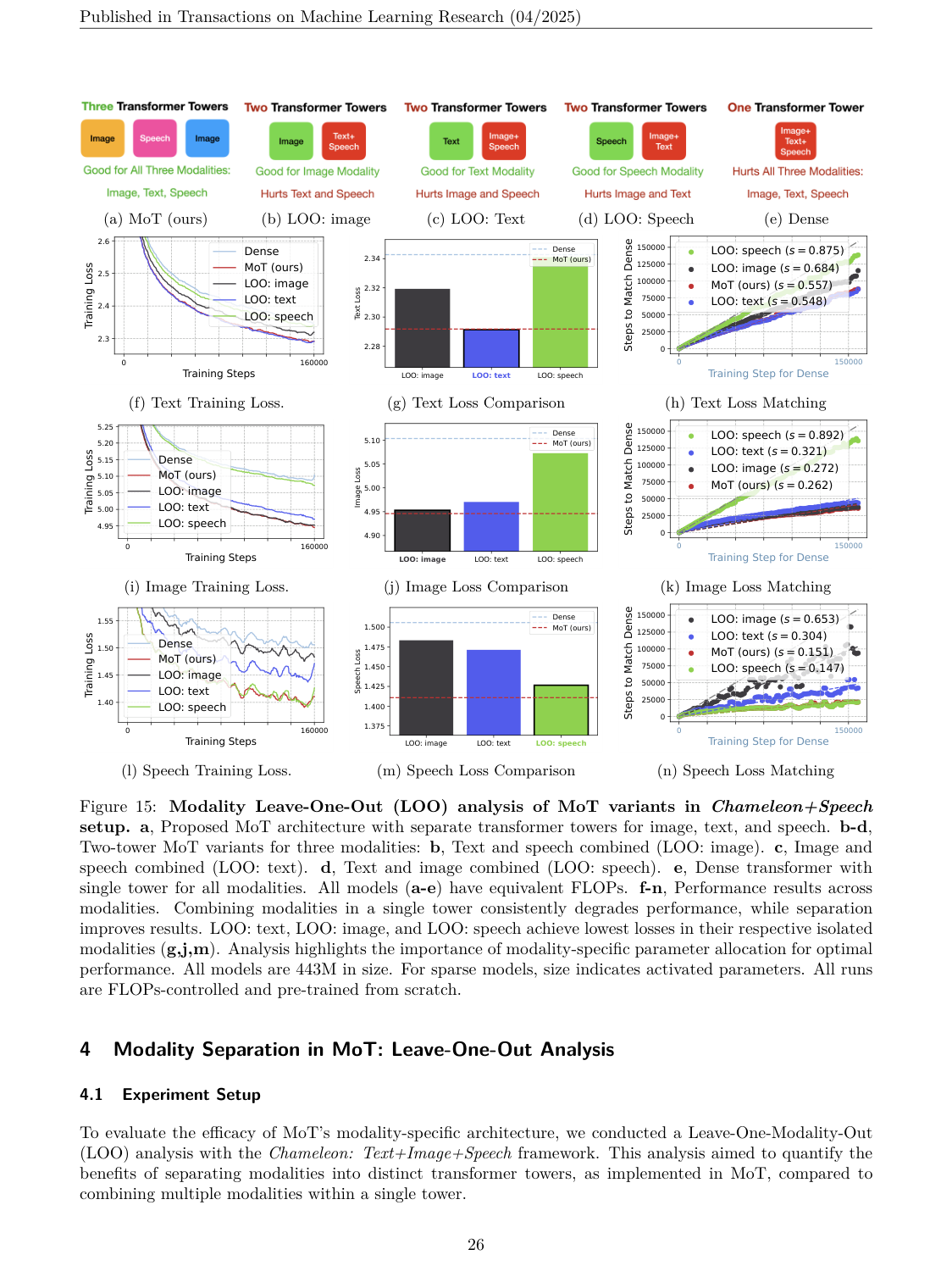
这也给一个更一般的架构启发:
当输入 token 的来源、统计结构、训练目标存在稳定可识别的类型差异时,最自然的 sparse routing 未必是 learned router,而可能是这些类型标签本身。
在多模态里,这个标签就是 modality;在 agent 或代码智能里,未来也可能是 observation/action/tool/result/reasoning 等 token role。
#8. MoT 可以和 MoE 结合:二者不是互斥关系
论文还有一个很有意思的部分:MoT 和 MoE 可以组合。
直觉上,MoT 解决的是 模态级别的异质性:文本、图像、语音需要不同 Transformer 参数。MoE 解决的是 模态内部的容量扩展:例如文本内部可能还需要多个 FFN experts 来处理不同语言现象或任务模式。
所以二者可以形成层次化稀疏:
先按模态选择 Transformer tower
再在某个 tower 内部使用 MoE FFN experts
论文里做了 “MoT + Text MoE-4x” 的实验,说明 MoT 并不是 MoE 的替代品,而更像是另一层稀疏维度。MoT 管“模态级路由”,MoE 管“专家容量扩展”。
这点对未来架构很重要:真正的大模型稀疏化可能不是单一 routing 机制,而是多层次 routing:
- modality routing;
- task routing;
- token role routing;
- expert routing;
- memory / tool routing。
MoT 可以看作这个方向里非常干净的一步:先从最确定、最稳定的 routing signal——模态——开始。
#9. 系统角度:MoT 不只是理论 FLOPs 少,wall-clock 也真的快
很多稀疏模型的问题是:纸面 FLOPs 少,但真实训练不一定快,因为 routing、通信、负载均衡、kernel 效率会吃掉收益。
MoT 的优势在于 routing 很简单,模态划分天然已知,系统实现更可控。论文的系统 profiling 显示:
- 在 AWS p4de.24xlarge / A100 GPU 上,7B MoT 达到 Dense baseline 图像质量只需要 47.2% wall-clock time;
- 达到 Dense baseline 文本质量需要 75.6% wall-clock time;
- 在 GPU 数量增加时,MoT 的 horizontal scaling 优势更明显。
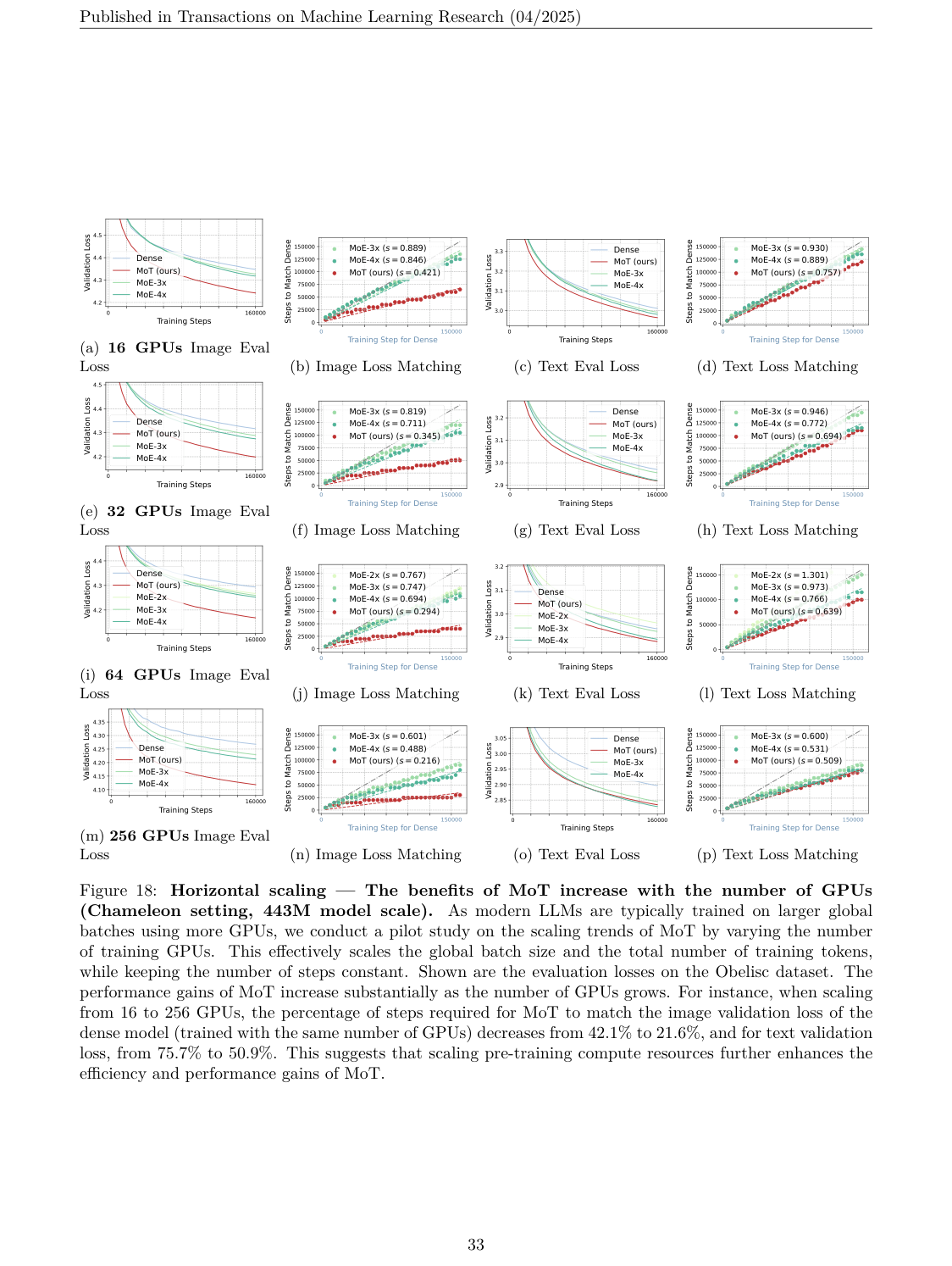
这点很关键。因为如果一个架构只能在理论 FLOPs 上省,但实际集群训练没有加速,它对 foundation model training 的意义会大打折扣。MoT 至少在论文实验里证明了它的稀疏性有实际系统收益。
#10. MoT 的局限:它依赖“模态边界清楚”这个前提
MoT 很漂亮,但它不是万能架构。它的优势来自一个强假设:token 的模态标签是清楚、稳定、有意义的。
在文本、图像、语音这种场景里,这个假设成立。但更复杂的场景可能没那么简单:
- 模态边界不总是清楚
例如视频、3D、动作、传感器数据、GUI trace、agent memory,它们到底应该怎样划分 tower?
- 模态内部仍然高度异质
图像 token 里有物体、纹理、文字、空间布局;文本 token 里有自然语言、代码、数学公式、工具调用。只按 modality 可能还不够。
- 跨模态共享程度需要调节
如果拆得太开,可能损失共享;如果共享太多,又回到 Dense 的干扰问题。MoT 当前给的是一种固定结构,而不是动态学习共享/隔离边界。
- 参数总量和部署复杂度仍要考虑
MoT 降低 activated FLOPs,但总参数会随着模态 tower 增加。训练时省计算,部署时的内存、并行切分、缓存管理仍然要仔细设计。
- 它主要解决多模态预训练效率,不直接解决推理智能问题
MoT 让模型更高效地吸收多模态数据,但它本身不是 reasoning、planning 或 agent learning 的完整答案。
#11. 对基础模型训练和 Agent 的启发
这篇论文对 wenjun 关心的基础模型训练、agent 预训练数据、长轨迹智能也有一些间接启发。
#11.1 “统一 token 空间”不等于“统一参数路径”
很多人说未来模型会把文本、图像、音频、动作、工具调用、环境状态都 token 化,然后统一用 Transformer 训练。MoT 提醒我们:
统一 token interface 是一回事,统一计算路径是另一回事。
Agent 轨迹里也有不同 token role:
- observation;
- thought;
- action;
- tool call;
- tool result;
- verifier feedback;
- memory write;
- environment transition。
它们也许都能表示成 token,但未必应该共享完全同一套参数。
#11.2 稳定可解释的 routing signal 可能比 learned router 更好
MoE 的 learned router 很强,但训练不稳定、解释困难。MoT 用 modality 作为 routing signal,简单但有效。
这启发 agent 架构可以考虑 role-based routing:
reasoning token -> reasoning path
tool-result token -> observation integration path
action token -> policy/action path
memory token -> retrieval/compression path
这不一定要立刻做成 MoT,但它提出了一个架构问题:agent 预训练里哪些 token role 应该共享参数,哪些应该专业化?
#11.3 稀疏化不只是省钱,也可能减少目标冲突
MoT 的 Transfusion 实验尤其重要,因为文本和图像用了不同训练目标。MoT 的收益不只是计算量下降,也可能来自减少不同 objective 之间的梯度干扰。
这对 agent 很相关。Agent 训练里经常混合:
- next-token prediction;
- behavior cloning;
- preference learning;
- reward modeling;
- world modeling;
- tool-use supervision;
- RL objective。
这些目标可能彼此冲突。MoT 提供了一个思路:不是所有目标都压进同一条 dense 参数路径,也许应该按数据类型/目标类型做结构化分流。
#12. 总结:MoT 的真正贡献是什么?
MoT 的贡献不只是“又一个 sparse architecture”。我觉得它真正重要的地方有三点。
第一,它把多模态模型中的模态差异变成了架构归纳偏置。Dense Transformer 假设所有 token 都应该共享一套处理参数;MoT 认为不同模态应该有不同的 Transformer 参数路径。
第二,它没有牺牲跨模态交互。MoT 不是简单多塔,因为它保留了全局 self-attention。不同模态可以在同一个序列上下文里互相 attend。
第三,它证明这种结构在真实多模态预训练中能带来实际收益:Chameleon 7B setting 下用 55.8% FLOPs 匹配 Dense baseline;加入 speech 后 speech performance 只需 37.2% FLOPs;Transfusion setting 下 760M MoT 用一半 FLOPs 超过 1.4B Dense;系统上也能在 wall-clock time 上加速。
如果用一句话收尾:
MoT 的核心不是“更多专家”,而是“更合理的共享边界”:多模态模型需要共享上下文,但不必共享所有计算参数。
这可能会成为未来原生多模态基础模型、机器人 VLA、世界模型、甚至 agent 预训练架构里的一个重要设计原则。