#Visual Language Hypothesis:视觉为什么需要“语言”?一篇拓扑视角论文的小白讲解
论文:Visual Language Hypothesis
作者:Xiu Li
这篇论文不是一篇实验论文,也不是提出一个新模型然后刷榜。它更像一篇理论解释文章:作者试图用拓扑学和几何语言解释,为什么视觉模型要真正获得“语义理解”,不能只靠重构像素、局部对比学习或平滑地压缩图像,而需要某种外部语义锚点,例如类别标签、跨实例监督、图文对齐,以及能够进行选择性路由和离散化的模型结构。
如果用一句非常直白的话概括:
视觉世界本来是连续、复杂、充满变化的;而语义世界往往是离散、稳定、可命名的。真正的视觉理解,就是把大量外观变化“折叠”成少数稳定概念。这个折叠不是普通的平滑变形,而是一种拓扑意义上的“商空间化”。
听起来很抽象。下面我会尽量不从公式开始,而是先用例子把直觉讲清楚,再把论文里的数学概念翻译成人话。
#1. 论文到底想回答什么问题?
现代视觉表征学习已经很强:
- CLIP 这种图文对齐模型能把图片和文字放到同一个语义空间;
- MAE、DINO、SimCLR 等自监督方法能学到很强的视觉特征;
- ViT、Transformer、多模态大模型展示出越来越强的泛化能力。
但论文问的是一个更底层的问题:
一个视觉表征要支持“语义抽象”,它在结构上必须具备什么性质?
注意,这里的“语义抽象”不是简单地说“分类准确率高”。更准确地说,是:
- 一只狗在白天、晚上、侧面、正面、遮挡、不同背景下,看起来都不一样;
- 但人类会把这些视觉输入都归为“狗”;
- 模型如果真的理解视觉,也应该把这些外观变化背后的稳定身份提取出来。
论文的核心假设叫 Visual Language Hypothesis,可以翻译成“视觉语言假设”。它说:
视觉理解预设了某种语义语言。也就是说,大量具体视觉观察,必须能对应到少量离散、可命名的语义状态。
这里的“语言”不一定只是自然语言句子,也可以理解为一套离散语义符号系统,例如“狗”“猫”“车”“红色”“遮挡”“正在奔跑”等。语言的关键不是发音或文字,而是:它给连续世界中的稳定模式提供了名字。
#2. 第一个关键直觉:一张图像不是一个孤立点,而是一束变化里的一个样本
比如你看到一张狗的照片。它不是一个孤立对象,而是很多因素共同生成的:
- 狗这个语义身份;
- 拍摄角度;
- 光照;
- 背景;
- 遮挡;
- 毛色、姿态、相机参数;
- 图片压缩和噪声。
其中,“狗”是我们想保留的语义;视角、光照、背景、噪声等很多因素是“干扰变化”,论文叫 nuisance variation。所谓 nuisance,不是说它们完全没用,而是说对于“这是不是狗”这个语义问题来说,它们不应该改变答案。
论文用一个拓扑图景表达这件事:视觉观察空间可以看作一种纤维丛式结构。
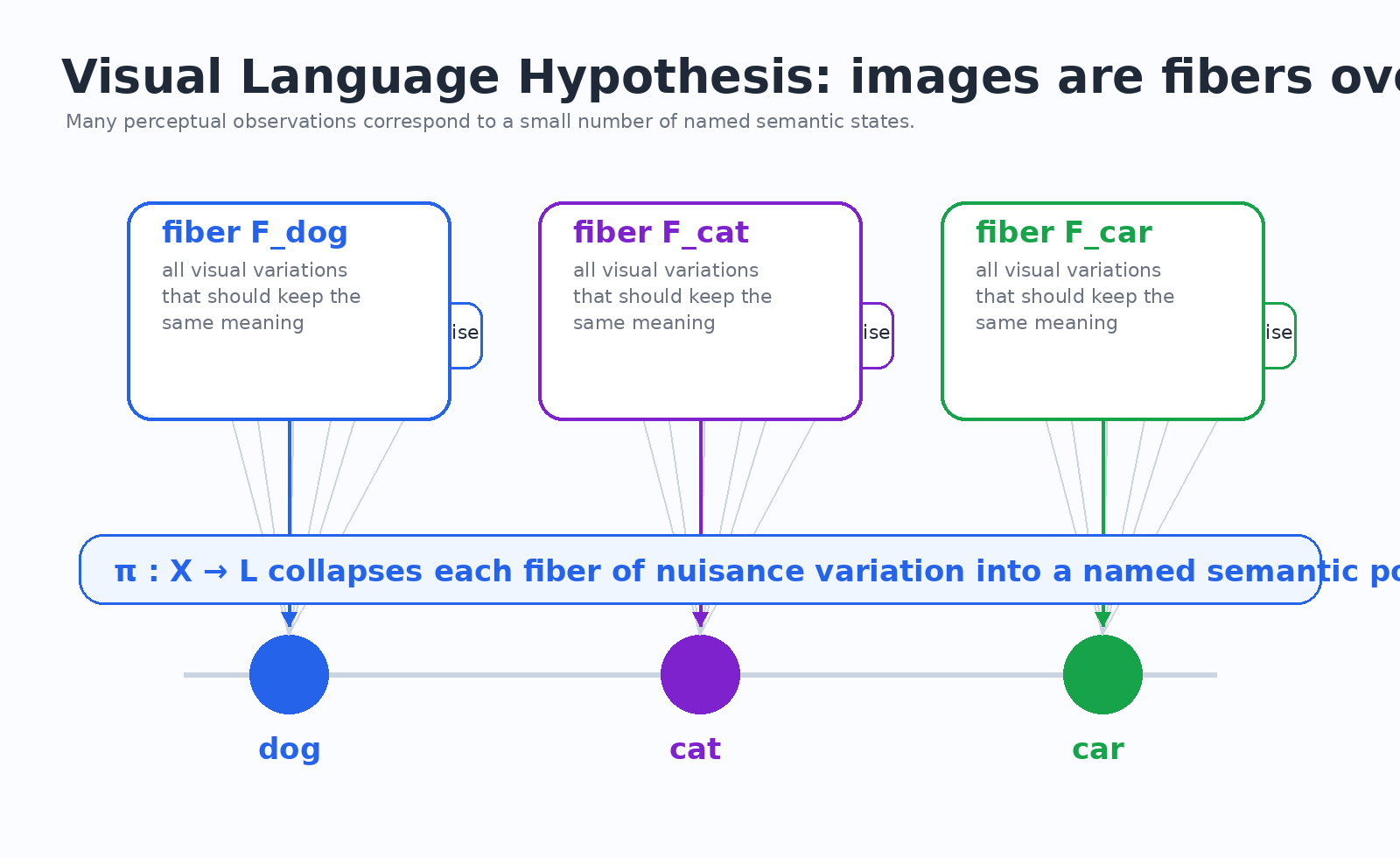
这张图里:
- 底部的
dog / cat / car是语义空间里的离散概念; - 每个概念上方有一束视觉变体,也就是同一语义在不同姿态、光照、背景下的样子;
- 从视觉输入到语义概念的映射,记作
π : X → L。
这就是论文的第一层结构:
X:所有可能的视觉观察,也就是图片空间;L:语义空间,也就是少量可命名的概念;G:不改变语义的变换集合,例如旋转、光照变化、背景变化;π:把图片映射到语义的抽象函数。
人话版:
X是所有照片的宇宙;G是“拍照条件怎么变”;L是“这到底是什么东西”;π是“看穿表象、认出本质”的能力。
#3. 论文里的数学概念逐个翻译成人话
这一节专门解释论文里最容易吓人的数学词。
#3.1 Equivalence Group:等价群是什么?
论文说存在一个等价群 G,作用在视觉信号上。
“小白版”理解:
G就是一组“虽然让图片看起来变了,但不改变语义”的操作。
例如:
- 把狗从正面拍成侧面;
- 光线从左边打变成右边打;
- 背景从草地变成沙发;
- 图片有一点遮挡;
- 物体轻微形变。
这些操作会改变像素,但不应该改变“狗”这个语义。
为什么叫“群”?在数学上,群是一组操作,满足组合、单位元、逆操作等性质。比如旋转 30 度再旋转 20 度,相当于旋转 50 度;旋转 0 度是不变;旋转 30 度可以用旋转 -30 度撤回。论文用 SO(3) 表示三维旋转群,用 S² 粗略表示光照方向的空间。
不用纠结这些符号。直觉就是:视觉世界里的变化不是随机乱动,而有一些物理结构。
#3.2 Orbit:轨道是什么?
给定一张狗的图片 x,对它施加所有不改变语义的变化 g ∈ G,会得到很多图片:
x, g1·x, g2·x, g3·x, ...
这些图片组成 x 的 orbit,也就是轨道。
人话版:
一个 orbit 就是“同一个东西在各种拍法、光照、姿态下形成的一整族图片”。
对于语义理解来说,同一个 orbit 里的图片应该被当成同一个语义。
#3.3 Fiber:纤维是什么?
论文写:
F_l := π^{-1}(l)
看起来像数学,其实意思很简单:
对于某个语义
l,所有会被π映射成这个语义的图片,组成一根 fiber。
比如 l = dog,那么所有被认为是狗的视觉变体,构成 F_dog。
为什么叫纤维?可以想象语义空间是地面上的几个点,每个点上方竖着一束线。每根线里是同一个语义的各种视觉变化。
#3.4 Fiber Bundle:纤维丛是什么?
纤维丛可以想象成:
底下是语义空间,上面每个语义点都挂着一整束视觉变化。
整套结构包括:
(X, L, π, G)
X:所有视觉观察构成的总空间;L:语义空间;π:从观察到语义的投影;G:在每个语义内部制造变化的变换集合。
论文的意思是:如果视觉理解真的依赖稳定语义,那么视觉空间自然就会呈现出这种“语义底座 + 视觉纤维”的结构。
#3.5 Quotient Space:商空间是什么?
这是全文最重要的数学概念之一。
商空间 X/G 的意思是:
把
X里所有只差 nuisance variation 的点都粘在一起,形成一个新的空间。
举个例子:
- 狗的正面照;
- 狗的侧面照;
- 狗在晚上;
- 狗在草地;
- 狗被遮住一半。
在原始图片空间里,它们是很多不同点,距离可能很远。但在语义空间里,它们应该被合并成一个概念:“狗”。
这个“把一整族点合并成一个语义点”的过程,就是 quotient,也就是取商。
人话版:
商空间就是“不要把每张照片都当成新东西,而是按语义把它们打包归类”。
#3.6 Homeomorphism:同胚是什么?为什么论文一直说 non-homeomorphic?
同胚可以理解为“橡皮泥式等价”。
如果一个形状可以通过连续拉伸、弯曲、压扁变成另一个形状,但不撕开、不粘合、不打洞、不补洞,那么它们就是同胚的。
经典例子:
- 咖啡杯和甜甜圈在拓扑上是同胚的,因为都有一个洞;
- 球和甜甜圈不是同胚的,因为球没有洞,甜甜圈有洞。
论文说语义目标是 non-homeomorphic target,意思是:
语义空间不是原始视觉空间经过平滑拉伸就能得到的。它需要把很多原本不同的点粘到一起,这会改变拓扑结构。
这就是为什么作者强调:重构、平滑变形、局部对比学习都不够。它们可以把空间“揉一揉”,但不能真正把一整束视觉变化“咔哒”合成一个语义符号。
#3.7 Homotopy:同伦是什么?
同伦比同胚稍弱一点,可以理解为:
一个函数或形状能不能连续地变形成另一个,而不发生撕裂和粘合。
论文里说重构损失倾向于保持 homotopy type,也就是保持一些全局拓扑特征,比如:
- 有几个连通块;
- 有没有洞;
- 环路结构是否还在。
人话版:
重构模型为了把图像还原回来,会尽量保留原始空间的细节和结构;它更像“整理图像空间”,而不是“按语义重新粘合图像空间”。
#3.8 Manifold:流形是什么?
流形可以粗略理解为:
在局部看起来像平面或普通空间,但整体可能弯曲、扭曲的空间。
地球表面就是一个二维流形:局部看像平面,整体是球面。
图像流形的意思是:自然图像虽然像素维度极高,但真实图片不可能随便取任意像素组合,而是落在一个相对有结构的低维区域上。模型学习视觉表征,就是在这个复杂流形上做变形、压缩和组织。
#4. 论文的核心论证:语义抽象不是平滑变形,而是拓扑坍缩
论文把学习目标大致分成两类来讨论。
第一类是生成式或重构式目标:
图像 x → 编码 f(x) → 解码 g(f(x)) ≈ 原图 x
第二类是判别式或对齐式目标:
图像 x → 表征 z → 类别标签 / 文本语义 / 决策区域
论文认为两者对空间结构的影响非常不同。
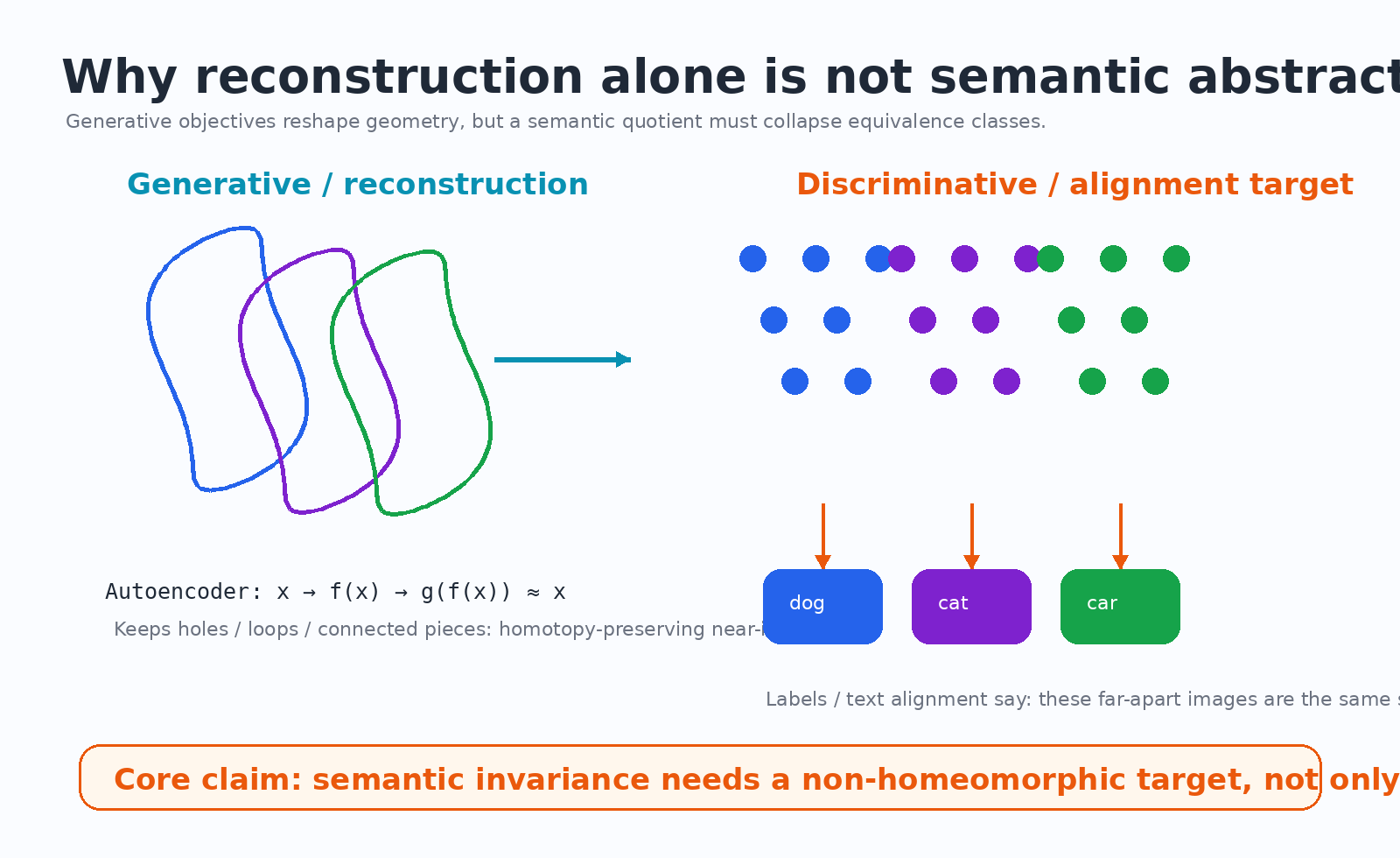
#4.1 重构式学习:擅长保留细节,但不负责“语义归并”
论文第 4 节把生成建模称为 manifold shaping,即流形塑形。
如果一个 autoencoder 训练得很好,那么:
g(f(x)) ≈ x
也就是说,编码再解码之后还要尽量还原原图。
这有什么后果?
它迫使模型保留很多图像细节。因为如果你把光照、姿态、背景、纹理都丢了,解码器就很难重构原图。
所以重构式目标会学到:
- 图片长什么样;
- 局部结构怎么组织;
- 哪些像素模式经常一起出现;
- 数据流形怎样弯曲和分布。
但它未必会学到:
- 哪些不同图片其实是同一个语义;
- 哪些变化应该被彻底忽略;
- 如何把一整个 orbit 合并成一个语义符号。
论文的拓扑说法是:重构目标如果误差很小,它学到的是接近恒等映射的连续变形,因此会保持原始空间的 homotopy type。它能弯曲、平滑、重新参数化数据流形,但不能完成 X/G 这种商空间坍缩。
小白版:
重构模型像一个认真临摹照片的人:它很在乎画面细节,所以不容易主动说“这些细节都不重要,统一叫狗”。
#4.2 对比学习:能拉近增强样本,但仍可能停留在局部不变性
论文也讨论 contrastive learning。对比学习会把同一张图的增强版本拉近,把不同实例推远。
例如:
x 和 crop(x) 应该近;
x 和 另一张图片 y 应该远。
这比纯重构更接近不变性,因为它会忽略一些数据增强造成的变化。
但论文指出:如果正样本只是同一实例的增强,那么它通常只学习到局部 invariance,而没有显式告诉模型:
这两张完全不同的狗的照片,虽然不是同一个实例,但属于同一个语义类。
所以,对比学习可能把每个实例周围的一小段变化处理得很好,却不一定形成全局一致的语义商空间。
人话版:
对比学习能告诉模型“这张图裁剪一下还是它自己”,但不一定告诉模型“这只狗和另一只狗在语义上也是同类”。
#4.3 判别式监督和多模态对齐:提供“把远处点粘起来”的外部信号
分类标签、图文对齐、跨实例识别等目标,会引入一种额外约束:
如果 xi 和 xj 是同一语义,它们应该落到同一个决策区域。
比如两张狗图像,像素上可能差很远,但标签都是 dog;一张图片和文本 “a dog running on grass” 也可能在视觉和语言上被对齐。
这类信号的作用是:
- 它不只是让模型保留原图;
- 它明确告诉模型哪些不同样本应该被认为等价;
- 它迫使模型把某些远距离区域合并到同一个语义区域。
论文把这叫 topological collapse,即拓扑坍缩。
注意,“坍缩”在这里不是坏词。它不是说模型坏掉了,而是说模型把大量连续变化压成一个稳定概念。
#5. “展开—咔哒归类”:论文最有传播力的图景
论文第 7 节提出一个很形象的过程:expand-and-snap。
可以翻译成:
先展开,再咔哒归类。
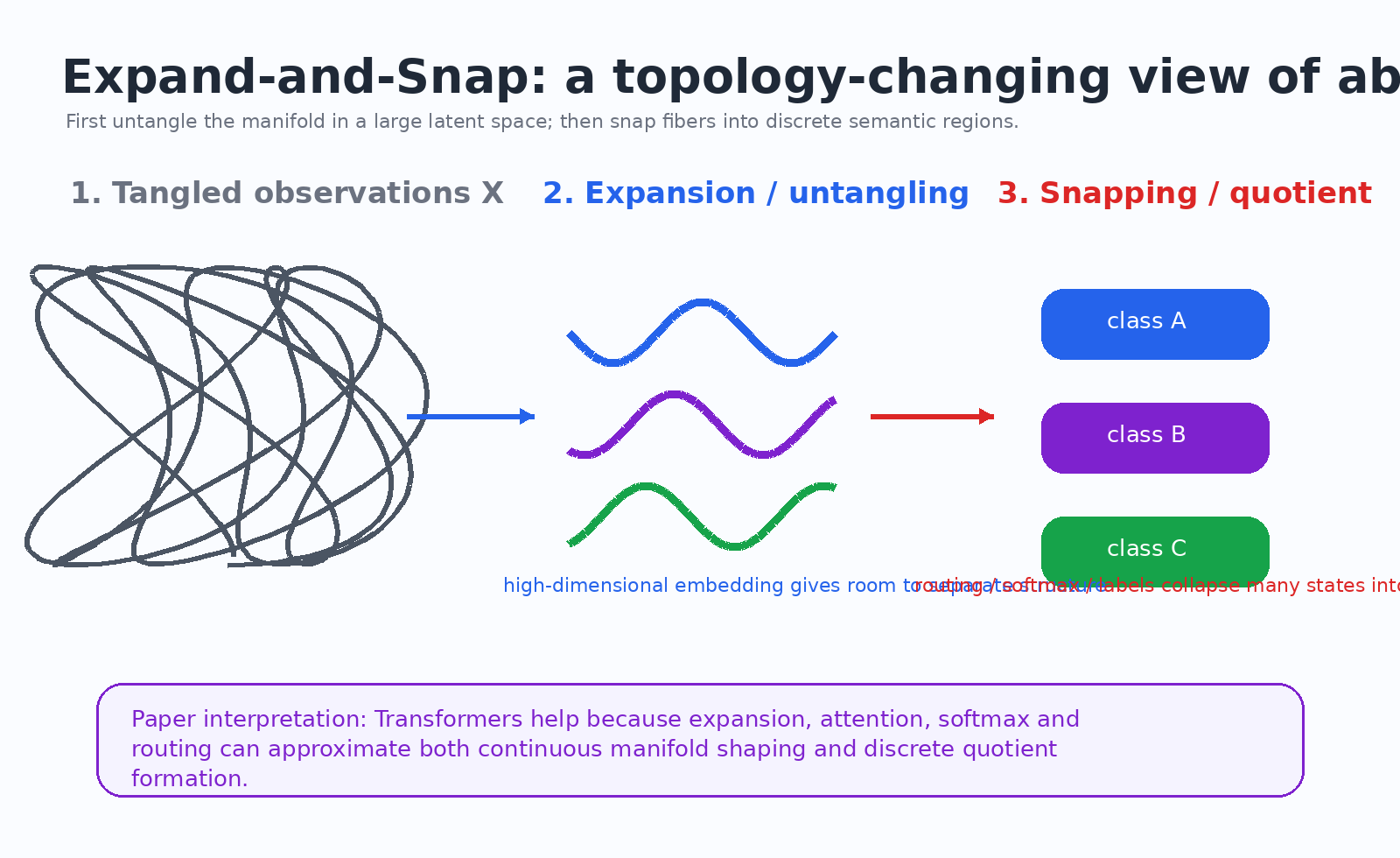
#5.1 Expansion:展开 / 解缠
视觉输入一开始是高度纠缠的:
- 狗和背景纠缠;
- 形状和光照纠缠;
- 物体身份和拍摄角度纠缠;
- 语义和像素纹理纠缠。
模型需要先把这些因素在高维表示空间里展开,让原来缠在一起的结构变得更容易分开。
这对应经典学习理论里的一个直觉:高维空间更容易线性可分。论文把它和 Cover's theorem 联系起来:升到更高维,相当于给模型更多几何自由度去 untangle。
小白版:
先把一团乱麻摊开,才能看清哪些线应该归到一起。
#5.2 Snapping:咔哒归类 / 坍缩
展开之后,还需要第二步:把属于同一语义的变化合并成离散区域。
这一步就是 snapping。
可以想象模型内部有很多连续状态,但最后 softmax 要在离散 token、类别或文本语义上做选择。它会把一大片连续状态压到某些离散结果上。
论文认为:
- 标签提供离散目标;
- softmax 产生概率质量集中;
- attention 产生选择性路由;
- MoE 和 gating 把输入送到不同专家;
- Transformer 的高维扩展和路由机制共同支持这种 expand-and-snap。
人话版:
展开负责“分得开”,snap 负责“归成类”。没有展开,语义缠在一起;没有 snap,只是散开的连续云团,还没有稳定符号。
#6. 为什么论文特别强调 Transformer、attention 和 softmax?
论文有一个比较有意思的解释:Transformer 不只是工程上更好扩展,它的结构也更适合语义抽象。
原因包括:
#6.1 高维中间层提供 expansion
Transformer 的 MLP、attention head、多层堆叠会把输入映射到很高维的表示空间。高维空间让原来纠缠的模式更容易分开。
#6.2 Attention 提供选择性路由
attention 的形式大致是:
α_i = softmax(<q, k_i>)
y = Σ_i α_i v_i
意思是:当前 query 会根据和各个 key 的匹配程度,给不同 value 分配权重。
当 softmax 很尖锐时,某些 token 会获得绝大部分权重,其他 token 几乎被忽略。这就像模型内部做了一个选择:走这条路径,而不是那条路径。
论文把这种现象称为 piecewise routing,分片路由。不同输入区域可能触发不同 attention pattern,于是模型不再只是平滑地揉捏整个空间,而是在不同区域使用不同计算分支。
#6.3 Softmax / 分类目标提供 snapping
softmax 最终会把连续 logit 变成对离散类别的概率分布。语言模型虽然常被叫生成模型,但 next-token prediction 本质上每一步都在从离散词表里选一个 token。
论文因此说:LLM 的学习信号在某种意义上是 discriminative 的,因为它每一步都要在有限词表中选择正确 token。这种低基数、离散目标会给模型施加语义坍缩压力。
这和 wenjun 关心的基础模型训练有一个很自然的连接:
大模型的“生成能力”并不只是来自连续密度建模,而可能来自持续面对离散符号预测任务时,模型被迫把复杂上下文压缩成可选择的语义状态。
#7. 论文里的 toy example:为什么 (A+B) mod n 能说明问题?
论文第 6 节构造了一个玩具例子:
C = (A + B) mod n
然后把 A+B 这样的表达式渲染成图片。图片里可能有字体、布局、噪声等变化,但语义由 C 决定。
这个例子想说明:
- 视觉输入里有很多生成因素,例如 A、B、字体、位置、噪声;
- 最终语义 C 是一个离散类别;
- 很多不同的
(A, B)会得到同一个 C; - 因此,从图片到语义不是简单恢复所有生成因素,而是把许多配置合并成同一个 quotient value。
举例:如果 n = 10:
1 + 2 = 3
4 + 9 = 13 mod 10 = 3
7 + 6 = 13 mod 10 = 3
不同输入都对应同一个语义类别 3。
这个 toy example 的意义是:
语义抽象不是把所有底层原因都反演出来,而是识别哪些不同输入在任务语义上应该合并。
这点对真实视觉也成立。比如你不需要恢复狗的每根毛、每个光照参数、完整三维模型,才能知道它是狗。理解经常不是“还原全部世界”,而是“抽出对当前语义稳定的东西”。
#8. 这篇论文和 CLIP / VLM 有什么关系?
从这篇论文视角看,CLIP 或视觉语言模型重要的不是“多了文字”这么简单,而是:文字提供了外部语义结构。
纯视觉自监督可能主要在视觉空间内部学习:
图片和图片之间怎么像?
增强前后怎么保持一致?
像素结构怎么重构?
图文对齐则引入了一个非同构的外部空间:
图片 ↔ 文本描述
文本天然是离散、符号化、可组合、可迁移的。它会告诉模型:
- 这些不同图片都可以叫 dog;
- dog 可以和 running、grass、small、brown 等词组合;
- 一张图里的局部视觉模式可以和语言概念对齐。
这就是论文所谓 external semantic equivalence:外部语义等价关系。
人话版:
文本像一把标签枪,把视觉空间里原本相距很远的点打上相同或相关的语义标记,让模型知道哪些东西应该在语义上被拉到一起。
#9. 这篇论文最重要的启发是什么?
我觉得可以总结成四条。
#9.1 表征学习不是只关心维度压缩,而是关心“等价关系”
很多时候我们说 representation learning,会自然想到降维、压缩、聚类、线性可分。但这篇论文提醒我们:更关键的问题是:
哪些不同输入应该被认为是同一个语义?
这就是等价关系。没有正确的等价关系,模型学到的只是好看的几何结构,不一定是语义结构。
#9.2 语义不是原始视觉空间中的一个普通子流形
论文强调 X/G 不是 X 的 submanifold。意思是:语义空间不是原始图像空间里某个干净的小区域。
它是通过把原始空间里的很多轨道合并出来的。
小白版:
“狗”不是所有狗照片在像素空间里自然形成的一小团;它更像是把很多分散的视觉情况按语义强行归并后的结果。
#9.3 生成式目标和判别式目标各有角色,不是谁完全替代谁
这篇论文不是简单说生成模型没用。它说生成式目标擅长 manifold shaping:保留和整理视觉结构。
但如果目标是语义 abstraction,还需要能改变拓扑的信号。
所以更合理的理解是:
- 生成式 / 重构式目标:帮助模型学世界细节、局部结构、数据流形;
- 判别式 / 对齐式目标:帮助模型建立语义等价、离散概念和跨实例归并;
- 强模型可能需要二者结合:先有丰富结构,再有语义坍缩。
#9.4 对 LLM Agent 和基础模型训练的启发:任务和环境要提供“正确的商空间”
wenjun 关心 LLM Agent、长轨迹 RL、model-based RL、agentic pretraining。这个框架可以迁移过去看:
- Agent 的原始轨迹空间极其复杂:状态、动作、工具调用、环境反馈、失败路径、恢复策略;
- 真正有用的不是记住每条轨迹,而是抽象出“哪些轨迹在意图上等价”“哪些行动模式服务于同一子目标”;
- 如果训练目标只让模型模仿表面 token 或重构轨迹,可能主要学到 fiber 内结构;
- 如果环境、奖励、反思、语言反馈能提供跨轨迹的语义等价关系,模型才可能形成更好的 task quotient。
换句话说:
对 Agent 训练来说,关键可能不是收集更多轨迹本身,而是设计什么信号能告诉模型:哪些不同轨迹其实是在解决同一个抽象问题,哪些失败和成功之间共享同一个可复用策略。
这和长轨迹 RL 的难点高度相关:轨迹太长、表面变化太多,如果没有好的 quotient 信号,模型可能一直在复杂 fiber 里打转,而没有形成稳定的任务语义。
#10. 需要谨慎看待的地方
这篇论文很有启发性,但也要注意它的定位。
#10.1 它更多是解释性框架,不是严格证明现代模型为什么成功
论文自己也说这是 interpretive rather than prescriptive。也就是说,它提供一个拓扑视角来解释经验现象,而不是给出一个可直接验证的完整定理体系。
比如:
- attention 是否真的在严格拓扑意义上实现了 quotient collapse?
- softmax routing 和拓扑 surgery 的关系有多强?
- 不同自监督目标在什么条件下真的不能形成语义 quotient?
这些都还需要更严谨的实验和理论支撑。
#10.2 “生成式目标保持拓扑”依赖一些理想化假设
论文关于重构损失保持 homotopy type 的命题依赖连续性、小误差、嵌入、管状邻域等假设。真实神经网络训练可能有奇异点、离散采样、优化跳跃和有限数据效应。
所以不能过度解读成:
所有生成模型都不可能学语义。
更准确的说法是:
如果目标主要要求忠实重构,那么它天然倾向于保留许多视觉细节;若没有额外语义锚点,它不一定被迫形成全局语义商空间。
#10.3 对比学习不一定只有局部作用
现实中的对比学习如果正样本构造、数据增强、跨实例关系、聚类目标设计得足够好,也可能引入更强语义结构。论文的批评主要针对缺少外部语义锚点、只在实例级或增强级操作的情况。
#11. 如果只记住五句话
- 视觉理解不是记住像素,而是把很多外观变化归并成稳定语义。
- 同一个语义下面有很多视觉变体,这些变体可以看作 fiber;语义空间是把 fiber 压缩后的 quotient。
- 重构式学习擅长保留和整理图像流形,但不一定会主动把远距离样本合并成同一语义。
- 标签、图文对齐、跨实例监督提供了非同胚的外部语义目标,能迫使模型做拓扑意义上的归并。
- Transformer、attention、softmax、gating 的价值,可以被理解为支持“先展开,再咔哒归类”的表征机制。
#12. 最后一层人话总结
这篇论文的核心其实是在说一件很朴素的事:
世界给我们的输入是连续而混乱的,但智能需要的是稳定而可复用的概念。
视觉模型如果只是学习“图片长什么样”,它会在视觉变化的海洋里游泳;如果它要真正理解,就必须知道哪些变化只是表象,哪些差异才是语义。
语言、标签、多模态对齐之所以重要,不只是因为它们提供更多数据,而是因为它们告诉模型:
这些看起来不同的东西,在意义上是同一个;这些看起来相似的东西,在意义上可能不同。
这就是所谓视觉语言假设的精髓:
视觉需要语言,不是因为图像自己不重要,而是因为语言提供了把连续感知世界压缩成离散语义世界的锚点。
如果把它类比到基础模型和 Agent 训练上,也许可以得到一个更一般的原则:
真正关键的训练信号,不只是让模型拟合更多观察,而是帮助模型发现“观察之间的正确等价关系”。
这也许是从大规模数据走向更强语义抽象、更强迁移、更强自演化 Agent 的一个核心问题。