#Unlocking the Working Memory of Large Language Models for Latent Reasoning:让大模型在“工作记忆”里推理
论文:Unlocking the Working Memory of Large Language Models for Latent Reasoning
作者:Lukas Aichberger, Sepp Hochreiter
时间:2026-05-28
arXiv:<https://arxiv.org/abs/2605.30343>
#0. 一句话先讲清楚
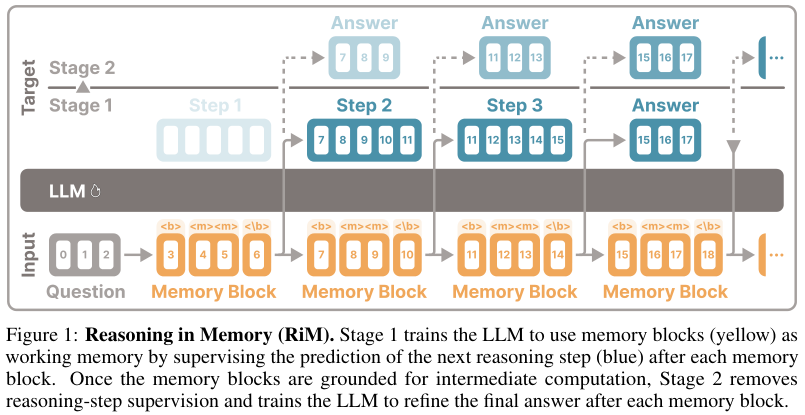
这篇论文提出 Reasoning in Memory(RiM):不要再让模型把中间推理一步一步生成出来,无论是生成自然语言 CoT,还是像 Coconut 那样自回归地产生 continuous thoughts;而是在输入后面放一串固定的特殊 token 组成 memory blocks,训练模型把这些 block 的上下文表示当作内部工作记忆,在一次 forward pass 里完成潜在推理。
换句话说,RiM 想做的事情是:
让 LLM 不必“边想边说”,而是学会在一段固定的内部工作区里“默想”。
它的核心判断很直接:
- CoT 的问题不是“语言没用”,而是把计算和交流绑定太死。模型为了推理,必须先生成一长串可读文本。
- 现有 latent reasoning 虽然把文字换成连续表示,但很多方法仍然要一步一步自回归地产生 latent state,本质上还是“连续空间里的边想边说”。
- 如果中间计算能放在固定 memory tokens 的 hidden states 里,那么这些 tokens 可以并行处理,推理延迟接近 direct answer。
- 关键难点不在架构,而在训练信号:普通 filler tokens 很容易被模型忽略,必须用合适 curriculum 把它们“激活”为工作记忆。
这篇文章和 wenjun 最近关心的 latent-space reasoning、长轨迹 agent RL、model-based RL for LLM Agent 很相关。因为它不是单纯在问“怎么多采样几个答案”,而是在问一个更基础的问题:
Transformer 能不能把一段 token position 训练成内部可读写的 latent workspace?如果可以,它能不能成为未来 agent 长程推理、规划、世界模型 roll-out 的低成本计算基底?
下面按“问题背景 → 方法 → 实验 → 机制证据 → 局限与启发”来讲。
#1. 这篇论文想解决什么问题?
#1.1 CoT 的核心矛盾:推理计算被迫以语言形式外化
当前提升 LLM 推理能力最常见的办法是增加 test-time compute:
- Chain-of-Thought:让模型写出中间推理步骤;
- self-consistency / repeated sampling:生成多条 reasoning traces;
- search / verifier / PRM:围绕中间步骤做搜索和评估;
- RL reasoning models:训练模型生成更长、更有效的思维链。
这些方法的共同点是:模型要想更多,就得说更多。
但语言本来是为了交流,不是为了内部计算。自然语言 CoT 有几个代价:
| 代价 | 直白解释 |
|---|---|
| 生成成本高 | 每个中间 token 都要自回归生成,不能并行 |
| 语法负担 | 模型要花算力生成通顺、可读、格式正确的文字 |
| 表达瓶颈 | 有些内部计算未必适合压成自然语言步骤 |
| 延迟高 | first token / full answer latency 都会显著增加 |
所以论文提出一个区分:
- external communication:把思考过程写给人看;
- internal computation:模型为了得到答案而进行的内部状态变换。
CoT 把这两者混在一起了。RiM 想把它们拆开。
#1.2 现有 latent reasoning 仍然没有完全摆脱自回归瓶颈
近两年有不少 latent reasoning 工作,典型包括 Coconut、compressed CoT、pause/filler tokens、DART 等。
论文把它们大致分成几类:
- 显式 latent reasoning:把自然语言 reasoning token 替换成连续表示。例如 Coconut 生成 continuous thoughts(CTs),再把 CT feed back 到后续解码。
- 隐式 latent reasoning / filler-token reasoning:给模型插入没有语义的 token,让它们承载内部计算。
- recurrent / vertical latent reasoning:通过循环模块或 hidden-state refinement 做多步计算。
RiM 对 Coconut 的批评尤其关键:Coconut 虽然不写自然语言思维链,但它还是要一个 CT 一个 CT 地生成。也就是说,它把“文字 token 的自回归”换成了“连续表示的自回归”。
这当然比完整 CoT 短,但中间计算仍然被迫 externalize 成一串 sequential latent states。后一个 latent state 必须等前一个产生后才能计算。
论文的观点是:
latent reasoning 真正要解耦的是“中间计算”和“自回归生成”。如果 latent state 仍要一个个生成,那么只是把语言空间换成连续空间,还没有彻底释放并行计算能力。
#2. RiM 的核心想法:固定 memory blocks 作为工作记忆
RiM 的设计非常简单:在问题后面追加若干个固定的 memory blocks。每个 memory block 是一串特殊 token:
<b> <m> <m> ... <m> </b>
其中:
<m>是真正的 memory token;<b>和</b>标记 block 边界;- 每个 block 由固定数量 M 个 memory token 组成;
- 实验默认 M = 2;
- 多个 block 串起来形成 K 个 latent computation slots。
形式上,输入从:
question -> answer
变成:
question -> memory block 1 -> memory block 2 -> ... -> memory block K -> answer readout
关键在于:这些 memory tokens 的 token identity 和位置是固定的,但它们经过 Transformer 后的 contextual representations 是输入相关的。也就是说,同样的 <m> token,在不同问题里会形成不同 hidden states。
这就是论文所谓的 working memory:
固定 token 提供位置和容器,hidden states 承载任务相关的中间计算。
#2.1 为什么固定 memory blocks 能降低延迟?
因为它们不是模型逐步生成出来的,而是预先放进输入里的 token。Transformer 可以对整段 augmented sequence 做一次 forward pass。
对比一下:
| 方法 | 中间计算形式 | 是否需要自回归地产生中间状态 | 推理延迟 |
|---|---|---|---|
| CoT | 文本 reasoning tokens | 需要 | 高 |
| Coconut | continuous thoughts | 需要 | 中高 |
| RiM | 固定 memory token 的 hidden states | 不需要 | 接近 direct answer |
这点是 RiM 的最大卖点:它不是减少中间步骤长度,而是改变中间步骤的计算拓扑。
#2.2 只插入 filler tokens 为什么不够?
这篇论文并不是第一个想到 filler/memory tokens 的。之前很多工作已经发现:简单插入 pause tokens 或 filler tokens,效果通常不稳定,甚至会变差。
原因很简单:Transformer 没有天然知道这些 token 是“草稿纸”还是“噪音”。如果训练目标没有强迫模型把信息写进去、读出来,它很可能直接忽略它们。
所以 RiM 的核心不只是 memory block 本身,而是两阶段训练:
- Stage 1:用显式 reasoning steps 监督 memory blocks,给它们赋予计算角色。
- Stage 2:去掉中间步骤监督,只监督最终答案,让 memory blocks 从“复述中间步骤”转向“服务最终答案”。
#3. Stage 1:先教 memory blocks 复原中间推理步骤
Stage 1 的目标是:让 memory blocks 不再是空 token,而是被迫存储和变换与推理相关的信息。
训练样本包含:
问题 x
显式推理轨迹 r1, r2, ..., rT
最终答案 y
RiM 为每个 reasoning step 分配一个 memory block。第 t 个 memory block 后面接一个 readout,让模型预测下一个 reasoning step:
x + m1 -> predict r2
x + m1 + m2 -> predict r3
...
x + m1 + ... + mT -> predict y
论文里的目标函数大意是:
Stage 1 loss = 对每个 memory block 后的 readout 做 next reasoning step NLL
更直白地说:
你不能直接看到前面的文字推理步骤,只能看问题和已经经过的 memory blocks;如果你要预测下一步推理,就必须把有用信息压到 memory blocks 里。
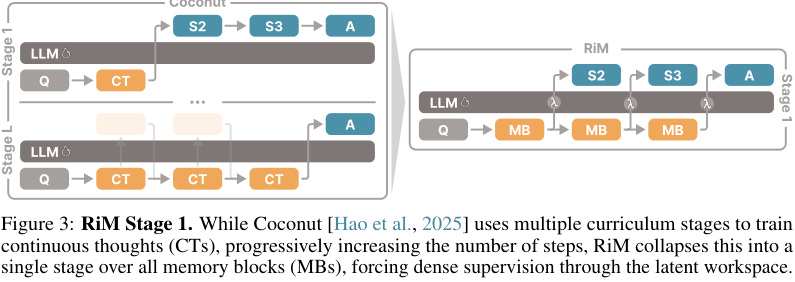
#3.1 RiM 为什么不直接照搬 Coconut 的 curriculum?
Coconut 的思路是逐步把显式 reasoning steps 替换成 continuous thoughts。RiM 认为这种做法有两个问题:
- 监督可能绕过 latent workspace。 早期阶段里,目标 reasoning step 可以 attend 到前面的 written steps,于是模型可以直接从文字步骤预测下一个步骤,不一定需要把信息写进 latent tokens。
- 监督不够密集。 Coconut-style staging 需要预设最多多少阶段,可能只有部分 reasoning steps 被 latent 替换,很多中间步骤不会直接从 memory block 读出来监督。
RiM 的解决方案是:一开始就把所有 reasoning steps 对齐到 memory blocks,并用 attention mask 防止信息泄漏。
#4. Attention mask:防止模型偷看答案,强迫信息经过 memory blocks
RiM 能做 dense supervision 的关键是自定义 attention mask。
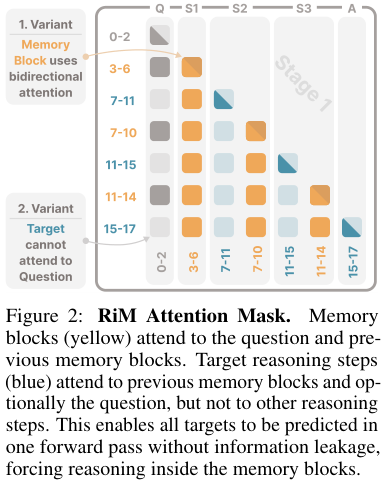
它的基本规则是:
- memory blocks 可以 attend 到问题和之前的 memory blocks;
- target reasoning step readout 可以 attend 到之前的 memory blocks,也可以选择是否 attend 到问题;
- target reasoning steps 之间不能互相 attend;
- 因此所有 target 可以在一个 forward pass 里训练,但不会互相抄答案。
这点很重要。否则 Stage 1 会退化成普通 teacher forcing:模型看到前面的推理文字,自然能预测后面的步骤,memory blocks 学不到东西。
可以把 Stage 1 想象成一种“带遮挡的中间状态预测”:
你要预测下一步推理,但我把可直接利用的文字步骤遮住,只留给你 latent memory。于是你必须在 memory 里组织信息。
这和 JEPA / predictive representation learning 的精神有点像:通过预测缺失结构,让表示学会承载任务相关信息。
#5. Stage 2:去掉中间步骤监督,训练最终答案 refinement
Stage 1 的问题是:它仍然依赖显式 reasoning steps 作为 teacher。这样训练出来的 memory blocks 可能只是“中间步骤压缩器”,不一定最适合最终答案。
所以 Stage 2 做了一个 hard switch:
- 不再使用中间 reasoning trace;
- 固定使用 K 个 memory blocks;
- 每个 memory block 后面都接 answer readout;
- 每个 readout 都直接预测最终答案 y;
- 后面的 readout 权重更大,因为它能看到更多 memory blocks。
形式上类似:
x + m1 -> answer
x + m1 + m2 -> answer
...
x + m1 + ... + mK -> answer
这一步的直觉是:
Stage 1 先教模型如何在 memory 里放中间计算;Stage 2 再教模型如何把这些 latent computations 用来逐步修正最终答案。
这和人类学习也有点像:一开始可能需要把步骤写出来,后来内化以后,不必再逐字复述过程,而是直接在脑中操作并给出答案。
#5.1 Stage 1 和 Stage 2 的分工
| 阶段 | 训练目标 | 主要作用 | 风险 |
|---|---|---|---|
| Stage 1 | 从 memory blocks 预测下一步 reasoning step | 赋予 memory blocks 中间计算角色 | 过度绑定显式步骤 |
| Stage 2 | 从不同 memory budget 预测最终答案 | 把 latent workspace 转成答案 refinement | 若无 Stage 1,memory tokens 可能没学会计算 |
论文附录里的 ablation 显示:只做 Stage 2 虽然能快速提高 final answer,但 plateau 更低;只做 Stage 1 any-block 可能不错,但 final-block 不够好。两者都需要。
#6. 实验设置:在 GSM8K-Aug 上训练,在 GSM8K/GSM-Hard 上评估
论文实验主要关注三个问题:
- memory blocks 是否真的学到了非平凡 latent computation?
- RiM 相比 SFT、CoT、Coconut 等方法,在准确率和延迟上如何?
- RiM 对不同 inference-time memory budget 是否鲁棒?
#6.1 数据与模型
训练数据:GSM8K-Aug
- 约 385,620 个小学数学问题;
- 每个样本有最多 13 个 reasoning steps;
- Stage 1 用这些显式 arithmetic reasoning steps 做监督。
评估数据:
- GSM8K:in-distribution test;
- GSM-Hard:out-of-distribution,更难的数学问题。
模型:
- GPT-2;
- Llama-3.2-1B;
- Llama-3.2-3B。
#6.2 Baselines
论文比较了:
| baseline | 说明 |
|---|---|
| SFT w/o CoT | 直接问题到答案,和 RiM 一样不生成显式推理 |
| SFT w/ CoT | 生成完整 CoT,强 explicit reasoning baseline,但延迟高 |
| Coconut | 最相关的 latent reasoning baseline,自回归生成 continuous thoughts |
| DART | 作为文献官方结果比较,非完全同协议 |
一个值得注意的评估细节:论文没有直接在 test set 上挑最好 checkpoint,而是用 GSM8K 的 held-out split 做 cross-validation checkpoint selection,再报告结果。这是为了减少 selection overfitting。
#7. 结果一:RiM 在低延迟下超过 Coconut 和 direct SFT
主结果如下:
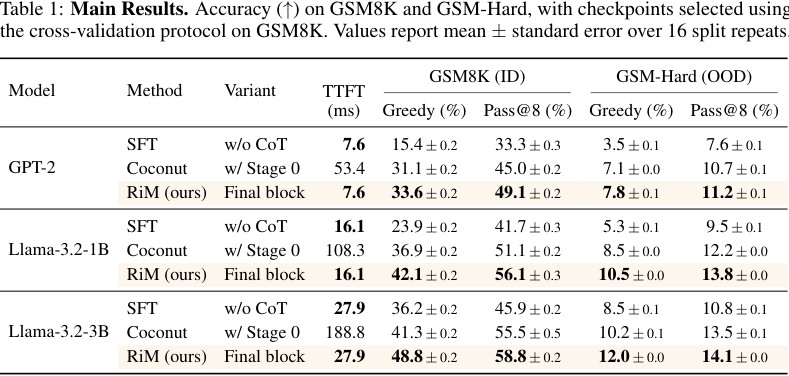
最重要的数字:
- GPT-2:RiM final block 在 GSM8K 上 33.6%,Coconut 31.1%,SFT w/o CoT 15.4%。
- Llama-3.2-1B:RiM 42.1%,Coconut 36.9%,SFT w/o CoT 23.9%。
- Llama-3.2-3B:RiM 48.8%,Coconut 41.3%,SFT w/o CoT 36.2%。
论文总结为:RiM final-block readout 相比最强 Coconut,在 GSM8K 上提升约 2.5 到 7.5 个百分点;相比 direct-answer SFT,提升更大。
注意这里的 final block 是可部署设置:只看最后一个 memory block 后的答案,不假设 oracle 能在多个 block 中挑正确答案。
#7.1 Any-block 结果:latent trajectory 里常常已经出现正确答案
论文还报告了 any-block readout:如果任意一个 memory block 后的 readout 答对,就算正确。这不是直接可部署指标,但能反映 latent trajectory 的潜力。
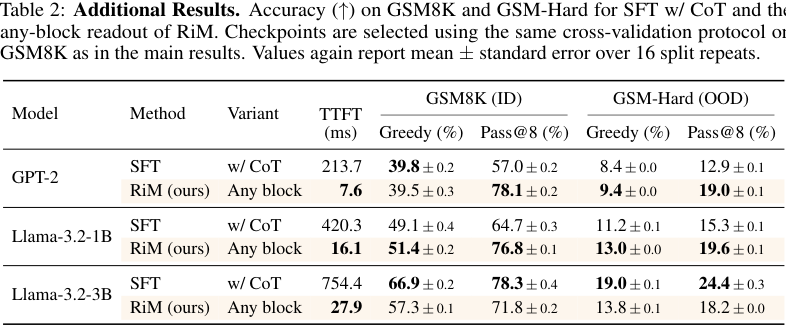
例如:
- GPT-2:RiM any-block GSM8K greedy 39.5%,接近 SFT w/ CoT 的 39.8%;GSM-Hard greedy 9.4%,超过 SFT w/ CoT 的 8.4%。
- Llama-3.2-1B:RiM any-block GSM8K 51.4%,超过 SFT w/ CoT 的 49.1%;GSM-Hard 13.0%,超过 11.2%。
- Llama-3.2-3B:SFT w/ CoT 仍明显更强,RiM any-block 不及 CoT。
这说明一个有趣现象:
memory blocks 的中间 readouts 里经常已经包含正确答案,只是最终 block 未必总能选中或保持它。
论文进一步用 linear probes 发现,memory representations 中包含可预测 correctness 的信息;在至少一个 block 答对的 recoverable subset 上,简单 probe-based selection 能 90% 选中正确答案。这对未来做 learned verifier / controller 很有启发。
#8. 结果二:RiM 的延迟几乎等于 direct answer
RiM 最大优势不是绝对准确率超过 CoT,而是 accuracy-latency tradeoff。
论文报告 TTFT:RiM 几乎和 SFT w/o CoT 一样,因为 memory blocks 是固定输入 token,一次 forward pass 处理。Coconut 因为要自回归生成 continuous thoughts,约慢 7 倍;SFT w/ CoT 因为要生成长文本 reasoning,约慢 27 倍。
附录 Table 7 报告 full answer wall-clock latency:
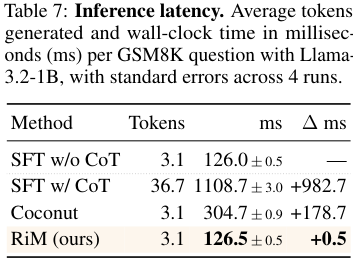
Llama-3.2-1B 上:
| 方法 | 生成 token 数 | wall-clock 时间 |
|---|---|---|
| SFT w/o CoT | 3.1 | 126.0 ms |
| SFT w/ CoT | 36.7 | 1108.7 ms |
| Coconut | 3.1 | 304.7 ms |
| RiM | 3.1 | 126.5 ms |
这个结果很关键:RiM 不是靠“多生成一些中间 token”换准确率,而是试图在 forward computation 内部重分配计算。
当然要小心:memory tokens 仍然会增加输入长度和 attention FLOPs,只是避免了自回归循环。因此当 K、M 很大、上下文很长时,成本仍会增长。但在论文设置下,它几乎不增加 measured latency。
#9. 结果三:memory blocks 真的形成了输入相关的 latent workspace 吗?
如果 RiM 只是靠特殊 token trick 提升,那意义有限。论文因此做了 representation analysis。
它们收集 Llama-3.2-1B 在 GSM8K 测试问题上的 memory block representations,然后投影到 PCA 空间,观察训练前后变化。
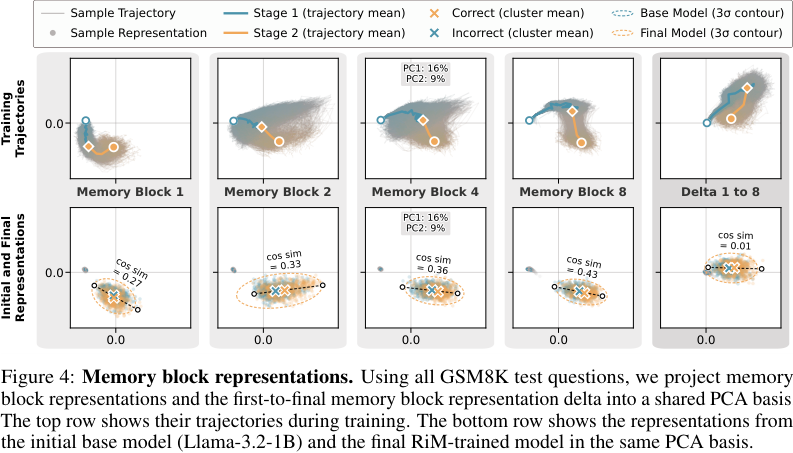
论文观察到:
- 训练轨迹是平滑的。 这说明训练不是随机扰动 hidden states,而是在系统组织表示空间。
- 不同 memory block 有不同轨迹。 说明 block 不是同质 filler token,而是形成了位置相关的计算角色。
- base model 表示更坍缩,final model 表示更分散。 说明训练后不同问题诱导出不同 latent workspace。
- first-to-final block delta 有结构。 说明沿 memory blocks 的方向确实发生了状态变化,而不是每个 block 都给同一个答案。
这部分是论文最有价值的机制证据之一:它尝试证明 memory blocks 不只是 prompt padding,而是变成了 task-dependent latent state。
#10. 训练曲线:Stage 2 是 final answer 能力跃迁的关键
Figure 5 展示 Llama-3.2-1B 在 GSM8K 上的训练曲线。
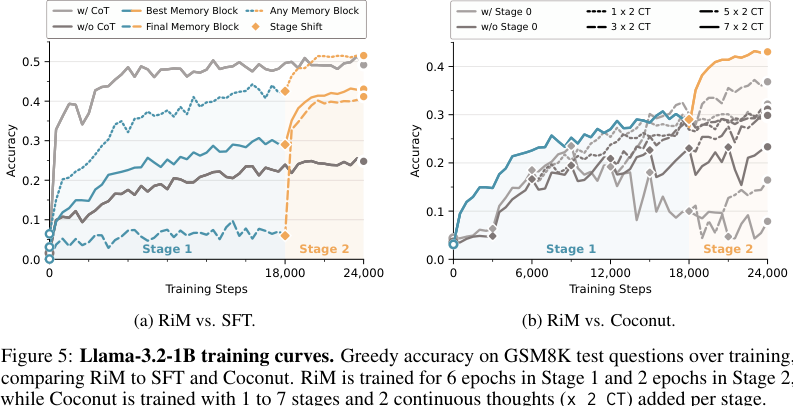
左图对比 RiM 和 SFT:
- Stage 1 主要让 latent workspace 成形;
- Stage 2 后 final memory block 准确率迅速提升;
- any-block accuracy 变得接近 SFT w/ CoT。
右图对比 RiM 和 Coconut:
- Coconut 加更多 CT stages 并没有稳定改善;
- RiM 在同训练预算下超过多个 Coconut 变体;
- 说明固定 memory blocks + dense supervision 的 curriculum,比逐步替换 reasoning steps 更有效。
这里我觉得最重要的是:RiM 的收益不是仅来自“多给几个 latent tokens”,而是来自训练方式让这些 token 承担计算角色。
#11. Memory budget 鲁棒性:给多少 memory block 都还能工作吗?
如果一种方法只能在训练时固定的 block 数量上工作,部署会很麻烦。论文因此测试不同 inference-time memory budget。
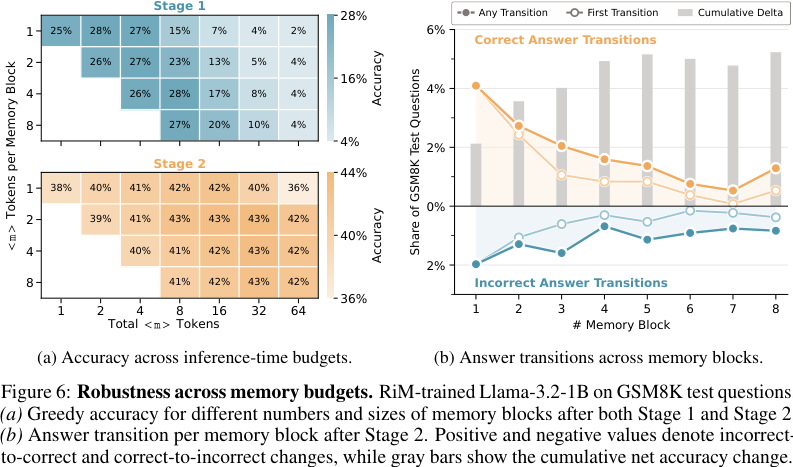
Figure 6a 显示:
- Stage 1 后,增加 block 数量反而可能使准确率下降,因为 Stage 1 的 readout 仍绑定到 reasoning-step positions;
- Stage 2 后,准确率在不同 memory budgets 下稳定在约 40% 左右,最高约 43%;
- 说明 Stage 2 把 memory blocks 从“对应第几步推理”转成了“固定 latent computation sequence”。
Figure 6b 显示:
- 随着 memory block 增加,答案仍会变化;
- incorrect-to-correct 的转变总体多于 correct-to-incorrect;
- cumulative net accuracy 是正的。
这说明 latent workspace 没有 collapse 成每个 block 都输出同一个答案,而是在逐步 refinement。
#12. 训练诊断:latent state 的统计性质在 stage switch 后变化
附录 Figure 13 给了训练过程中的诊断指标:latent similarity、latent norm、effective rank、total memory tokens、training perplexity。
这些图不是主结论,但提供了一个信号:Stage 1 到 Stage 2 的切换不是简单继续训练,而是目标函数变化导致 latent representation 的组织方式也变化。
对做 mechanistic / representation analysis 的人来说,这里还有继续挖的空间:
- 哪些层承担 memory computation?
- memory tokens 之间是否形成类似 scratchpad slots 的分工?
- final answer readout 是否在读取某些低维方向?
- correctness probe 能否变成可部署 selector?
#13. 这篇论文真正贡献在哪里?
我认为它的贡献可以分成三层。
#13.1 概念层:把 latent reasoning 从“连续 CoT”推进到“工作记忆”
很多 latent reasoning 方法只是把中间文字 token 换成 hidden states,但仍保留 sequence generation paradigm。RiM 强调:
真正的 latent reasoning 不应该只是“看不见的思维链”,而应该是一个内部 workspace。
这点很重要。因为如果 latent reasoning 仍然自回归地产生中间状态,它在计算图上仍然像 CoT;而 memory blocks 更像 Transformer 内部的一段可训练 scratchpad。
#13.2 方法层:用两阶段 curriculum 激活 filler tokens
RiM 没有引入复杂新模块,也没有多路径 self-distillation。它主要靠:
- 固定特殊 tokens;
- attention mask;
- Stage 1 reasoning-step supervision;
- Stage 2 final-answer refinement。
这说明一个可能的方向:与其设计更复杂的 latent module,不如设计更强的 training signal topology。也就是说,关键是让梯度如何穿过 latent workspace。
#13.3 实验层:在低延迟下超过 Coconut
在 controlled evaluation 下,RiM final-block 超过 Coconut;延迟又接近 SFT w/o CoT。这给了它很强的 practical appeal。
当然,它还没有证明能替代显式 CoT。在 Llama-3.2-3B 上,SFT w/ CoT 仍然明显更强。但 RiM 提供了一个有趣折中:
如果你不能接受长 CoT 的延迟,又希望比 direct answer 更会推理,那么固定 memory workspace 可能是一个方向。
#14. 局限:不要把这篇论文过度解读
这篇论文很有启发,但也有明显边界。
#14.1 任务主要是 GSM 系列数学题
实验集中在 GSM8K-Aug → GSM8K/GSM-Hard。虽然有 ID/OOD 区分,但仍然属于短程数学 word problems。
还没有证明:
- 多步代码推理;
- 长上下文规划;
- agent tool-use;
- theorem proving;
- open-ended research reasoning;
- 需要搜索和回溯的任务;
也能同样受益。
#14.2 Stage 1 依赖显式 reasoning traces
RiM 需要中间 reasoning steps 来 ground memory blocks。这在 GSM8K-Aug 上可行,但在很多真实任务中,高质量 step supervision 很贵,甚至不可得。
未来可能需要:
- synthetic traces;
- teacher model distillation;
- process supervision;
- RL final reward;
- self-improvement data;
- environment interaction traces。
论文结论里也提到,未来可研究 Stage 2 用 final-answer reward 做 RL。
#14.3 固定 memory blocks 的容量和可解释性仍不清楚
memory blocks 的 hidden states 到底编码了什么?
PCA 和 linear probe 提供了证据,但还远远不够。我们还不知道:
- 每个 block 是否对应某类推理操作;
- block 间是否有可复用算法结构;
- 是否只是学会了任务分布上的 shortcut;
- memory token 数量扩大后是否仍稳定;
- 在更大模型上是否会出现不同 scaling law。
#14.4 和 explicit CoT 的关系还不是替代,而是互补
RiM 的 final-block 低延迟很强,但显式 CoT 在较大模型上仍然有更高上限。更现实的方向可能是 hybrid:
- 简单题:RiM 直接 silent reasoning;
- 不确定题:RiM + verifier 选择 block;
- 困难题:触发显式 CoT / search / tool use;
- agent 任务:RiM 作为每一步 action 前的内部 planning workspace。
#15. 和 wenjun 关心方向的关系
#15.1 对 latent-space reasoning 的启发
RiM 说明 latent reasoning 的关键问题不是“能不能不用文字”,而是:
如何训练一个 latent state,使它真的承担中间计算,而不是被模型忽略?
这可以抽象为三个问题:
- workspace design:latent computation 放在哪里?token positions、hidden states、recurrent state、external memory?
- supervision topology:梯度如何强迫模型把信息写入 workspace?
- readout/control:如何从 workspace 中读出答案、判断正确性、决定是否继续计算?
RiM 对第 2 点给了一个漂亮范例:用 attention mask + dense step prediction 防止监督绕过 workspace。
#15.2 对 model-based RL / Dreamer for LLM Agent 的启发
如果把 LLM Agent 的长轨迹看作环境交互序列,那么一个核心瓶颈是:直接在超长 token/action 轨迹上做 RL 成本很高,信用分配也困难。
RiM 提供了一个可能的类比:
- Stage 1 像是用显式轨迹/teacher traces 学一个 latent workspace;
- Stage 2 像是把 workspace 转向 final outcome;
- 未来可用 RL reward 替代 final-answer NLL,使 workspace 为最终任务成功服务。
这和 Dreamer-style model-based RL 有相通点:
不一定要在外部 action/token 空间里展开所有推理,可以在 latent state 里做内部 roll-out / refinement,再读出 action。
当然,RiM 现在还不是 world model。它没有学习环境 transition,也没有多步 imagined rollout。但它证明了一个小尺度事实:固定 token workspace 可以被训练成任务相关内部计算空间。
这对 agent 方向的启发是:
- 可以在每个 observation 后插入 latent memory blocks,让模型先做 silent planning;
- 用 expert trajectories 或 process traces ground blocks;
- 再用 outcome reward / verifier reward 调整 final action readout;
- correctness/progress probe 可能成为是否继续思考或触发 tool use 的 controller。
#15.3 对代码 Agent 的启发
代码任务里,很多中间状态不一定适合自然语言表达,例如:
- 当前 bug hypothesis;
- symbol dependency;
- execution trace summary;
- patch plan;
- test failure localization;
- hidden constraints。
显式 CoT 会很长,而且未必忠实。RiM-style workspace 可能用于:
- 在读取代码上下文后插入 memory blocks;
- 用 repo-level traces / debugging traces 做 Stage 1;
- 让 block readouts 预测下一步诊断、patch intent、test expectation;
- Stage 2 用最终 patch correctness 或 test pass 监督。
这比“让模型写更长分析”更接近训练一个内部调试状态机。
#16. 我对这篇论文的判断
这篇论文不是那种“结果已经碾压一切”的工作,而是一个很有方向感的范式探索。它的重要性在于提出了一个清晰问题:
LLM 的推理能力是否必须通过自回归 token 序列展开?还是可以训练出一段并行可处理的内部工作记忆?
RiM 的答案是:至少在 GSM 类数学题上,可以。
我会把它放在 latent reasoning 发展脉络里的这个位置:
| 阶段 | 代表思路 | 核心限制 | RiM 推进点 |
|---|---|---|---|
| CoT | 写出自然语言步骤 | 高延迟、语言格式负担 | 把 reasoning 从外部文字移到内部状态 |
| Coconut | continuous thoughts | 仍需自回归生成 latent states | 固定 memory blocks,一次 forward pass |
| filler/pause tokens | 插入无语义 tokens | 很难训练出有用计算 | dense supervision + attention mask 激活 workspace |
| RiM | 工作记忆式 latent workspace | 仍依赖 step traces,任务范围有限 | 提供低延迟 latent reasoning 训练范式 |
最值得后续追的问题有三个:
- 能否用 RL 替代 Stage 2 的 final-answer NLL? 这直接连接 long-horizon agent / outcome reward。
- 能否把 memory blocks 变成可控 compute budget? 类似 adaptive computation:不确定就多用 blocks,确定就少用。
- 能否学一个 selector/verifier 从多个 block readouts 里选答案? any-block 和 linear probe 结果说明这里潜力很大。
如果未来有人把 RiM-style memory workspace 和 agentic RL、tool-use traces、world-model imagination 结合起来,它可能会从“数学题低延迟推理技巧”变成更通用的 latent planning substrate。
#17. 最后用人话总结
这篇论文可以用一个比喻讲完:
以前我们让模型做题,是让它把草稿纸一行一行念出来。CoT 是念中文草稿,Coconut 是念一种人看不见的连续向量草稿,但还是一行一行念。RiM 说:为什么一定要念?我们能不能直接在模型输入里放几格“脑内草稿纸”,训练模型把中间计算写到这些格子的 hidden states 里,最后只说答案?
它的训练方法是:
- 先让每格草稿纸能复原下一步推理,确保模型真的往里面写东西;
- 再取消逐步推理监督,让每格草稿纸都服务最终答案;
- 用 attention mask 防止模型偷看文字步骤;
- 最后得到一个几乎不增加推理延迟、但比 direct answer 和 Coconut 更强的 latent reasoning 方法。
对 latent reasoning 来说,这篇论文的价值不是“GSM8K 提了几个点”,而是把问题重新表述成:
如何训练 LLM 使用内部工作记忆,而不是把所有思考都外化成 token 序列?
这正是后续做长程 agent、潜空间规划、model-based RL for LLM 时绕不开的问题。