#Qwen-AgentWorld:把“世界模型”搬进语言 Agent
论文:Qwen-AgentWorld: Language World Models for General Agents
团队:Qwen Team
一句话:这篇论文不是又做了一个更会 tool-use 的 Agent,而是把“环境会怎样回应我的动作”这件事单独训练成一个 foundation model,然后用它反过来扩展 Agent 训练。
如果用最直白的话说:
传统 Agent 训练主要问:给定当前状态,我下一步该做什么?
Qwen-AgentWorld 反过来补上另一个问题:如果我这么做,环境下一步会发生什么?
这就是 world model 在 Agent 里的意义。
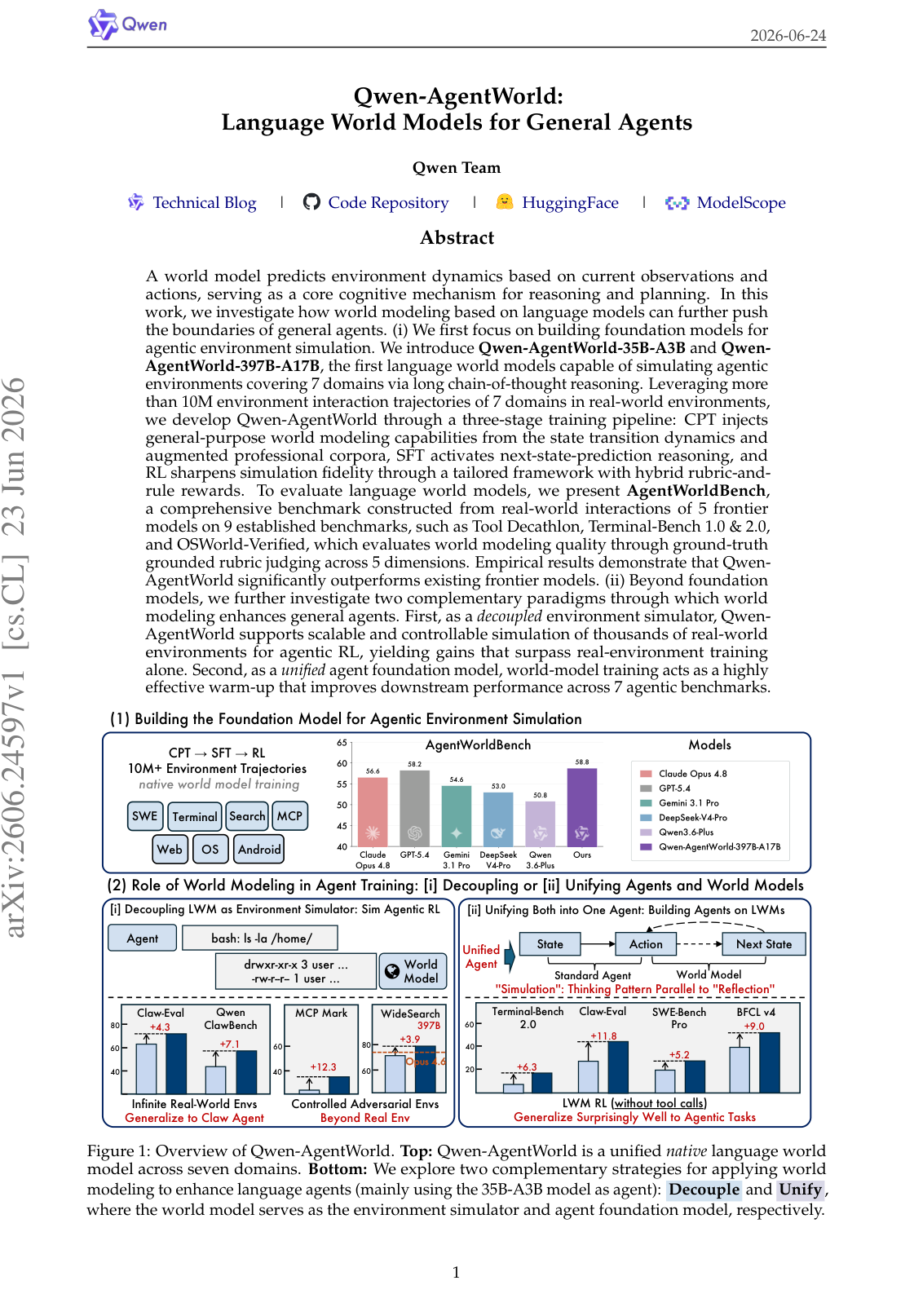
上图其实就是整篇文章的核心:Qwen-AgentWorld 先把大量真实 agent-environment interaction 轨迹整理成“动作 → 观测”的预测任务,训练出一个 language world model;然后它有两种用法:
- Decouple:世界模型和 Agent 分开。世界模型作为模拟环境,给 Agent 提供可扩展、可控的训练环境,也就是 Sim RL。
- Unify:世界模型和 Agent 合一。先把模型训练成会预测环境反馈的 LWM,再把它作为 Agent foundation model 继续做 agentic RL / downstream training。
这篇论文对我来说最值得关注的地方,不是某个 benchmark 数字,而是它把 LLM Agent 的扩展路径从“更多真实环境 rollout”推进到了“可训练、可控、可泛化的语言环境模拟器”。这和 model-based RL、长轨迹 Agent RL、agent 预训练数据如何塑造能力这些问题高度相关。
#1. 这篇论文想解决什么问题?
现在 LLM Agent 的训练大多围绕 policy 展开:
- 当前 observation 是什么?
- 我应该调用哪个工具?
- 输入什么参数?
- 下一步怎么规划?
形式上,这是在学一个 policy:
state / observation → action
但一个真正能泛化的 agent,理论上还需要另一种能力:它得知道行动之后世界会怎样变化。
比如:
- 在 terminal 里执行
rm -rf /tmp/foo后,文件系统状态会发生什么变化? - 在搜索任务里,如果我只查一个关键词,会不会得到太粗的 snippet?
- 在 MCP / Notion API 里创建 parent-child block 后,后续 ID 引用应该如何保持一致?
- 在 GUI 里点击某个按钮,下一屏会出现什么?
- 在软件工程任务里,一个 patch 会触发什么 traceback?
这就是 world model:
state + action → next state / next observation
Qwen-AgentWorld 的判断是:LLM Agent 现在缺的不是又一个局部 tool-use trick,而是一个通用的语言世界模型,它能覆盖 Terminal、Search、MCP、SWE、Android、Web、OS 等不同交互环境,并以文本形式预测下一步 observation。
#2. 什么是 Language World Model?
传统 world model 常见于游戏、机器人、自动驾驶:模型根据当前视觉状态和动作预测下一帧、下一状态或未来轨迹。
Qwen-AgentWorld 把这个概念搬到语言 Agent 场景里。这里的“世界”不是像素世界,而是各种数字环境的文本化状态:
- terminal 输出;
- API 返回;
- search engine snippet;
- browser DOM / accessibility tree;
- Android UI hierarchy;
- OS 桌面状态;
- SWE 任务里的代码、测试输出、traceback。
因此 Language World Model 的目标是:
输入:system prompt + 历史 observation + 当前 action
输出:下一步环境 observation
论文把它写成:给定系统提示 c、历史观察 o≤t 和当前动作 at,模型预测 ô_{t+1}。训练目标是让预测 observation 接近真实环境执行得到的 o_{t+1}。
这件事看似只是“模仿环境输出”,但对 Agent 很关键。因为 Agent 做长轨迹任务时,很多失败不是“不知道下一步动作名字”,而是没有正确预判动作的后果:
- 以为某个 shell 命令会成功,实际缺依赖;
- 以为一个 API 返回完整信息,实际只返回部分字段;
- 以为网页 snippet 已经足够,实际需要打开页面;
- 以为一个配置会生效,实际系统在更早的验证阶段拒绝了请求。
如果模型能在行动前更准确地模拟这些反馈,它的 planning 和 debugging 都会变强。
#3. 它覆盖哪些环境?
Qwen-AgentWorld 覆盖七类 agentic environment:
- MCP / tool-use:例如 Notion、文件系统、数据库、Playwright 等工具调用。
- Search:搜索引擎、网页摘要、网页抽取。
- Terminal:Linux / Unix shell 状态、命令执行、副作用、错误输出。
- SWE:软件工程任务,包括代码修改、测试、traceback、仓库状态。
- Android:移动端 GUI 环境。
- Web:浏览器环境、网页结构、点击/输入后的变化。
- OS:桌面操作系统环境。

这张图的重要性在于:论文不是只做一个 terminal simulator,也不是只做 web simulator,而是试图把不同环境统一成一种 schema:
system_prompt := task_description + action_space + initial_state + demonstrations + simulation_instruction
turn_t := (action_t, observation_t)
trajectory := system_prompt + [turn_1, ..., turn_T]
换句话说,不同环境的差别被压到 system prompt、action space 和 state representation 里,而训练目标都统一成 next-observation prediction。
这个统一很关键。因为如果每个环境都要单独训练一个模拟器,那它更像工程组件;而如果一个模型能在七类环境上共享 world-modeling 能力,就更接近“agent foundation model”。
#4. 训练数据:10M+ 环境交互轨迹从哪里来?
论文说 Qwen-AgentWorld 使用超过 10M environment interaction trajectories,来源主要有三类:
#4.1 专门搭建的 Agent 基础设施
他们部署了大量 agent-environment backend:
- containerized execution sandbox;
- MCP server;
- persistent terminal session;
- Android / browser / desktop OS 环境;
- SWE 代码执行与测试环境。
然后自动生成任务,让 agent 在这些环境里执行,收集真实 action-observation 轨迹。
这类数据的优点是可控、可复现、结构一致。
#4.2 开放交互日志
比如 terminal session、开源 agent tool-call log、代码仓库中的执行 trace 等。
这类数据更脏,但有长尾价值:真实世界里很多奇怪 shell workflow、罕见 API error、非常规工具链错误,不一定能靠合成任务覆盖。
论文用 multi-agent cleaning pipeline 做抓取、去噪、切分、语义对齐和质量打分。
#4.3 内部基础模型开发中的 agentic trajectories
这些轨迹覆盖七个领域,并被转换成 environment trajectory。注意这里会去掉 agent 的内部 reasoning,只保留环境交互:
agent action → environment observation
论文中特别区分了两种轨迹:
- agentic trajectory:包含模型思考、规划、动作、环境反馈的完整 agent 运行过程;
- environment trajectory:只保留 action-observation pair,用来训练世界模型。
这个区分很重要。Qwen-AgentWorld 不是直接学“优秀 agent 怎么想”,而是先学“环境怎么回应动作”。这使它更接近 model-based RL 里的 dynamics model。
#5. 三阶段训练:CPT injects, SFT activates, RL sharpens
论文把训练 recipe 总结成一句话:
CPT injects, SFT activates, RL sharpens.
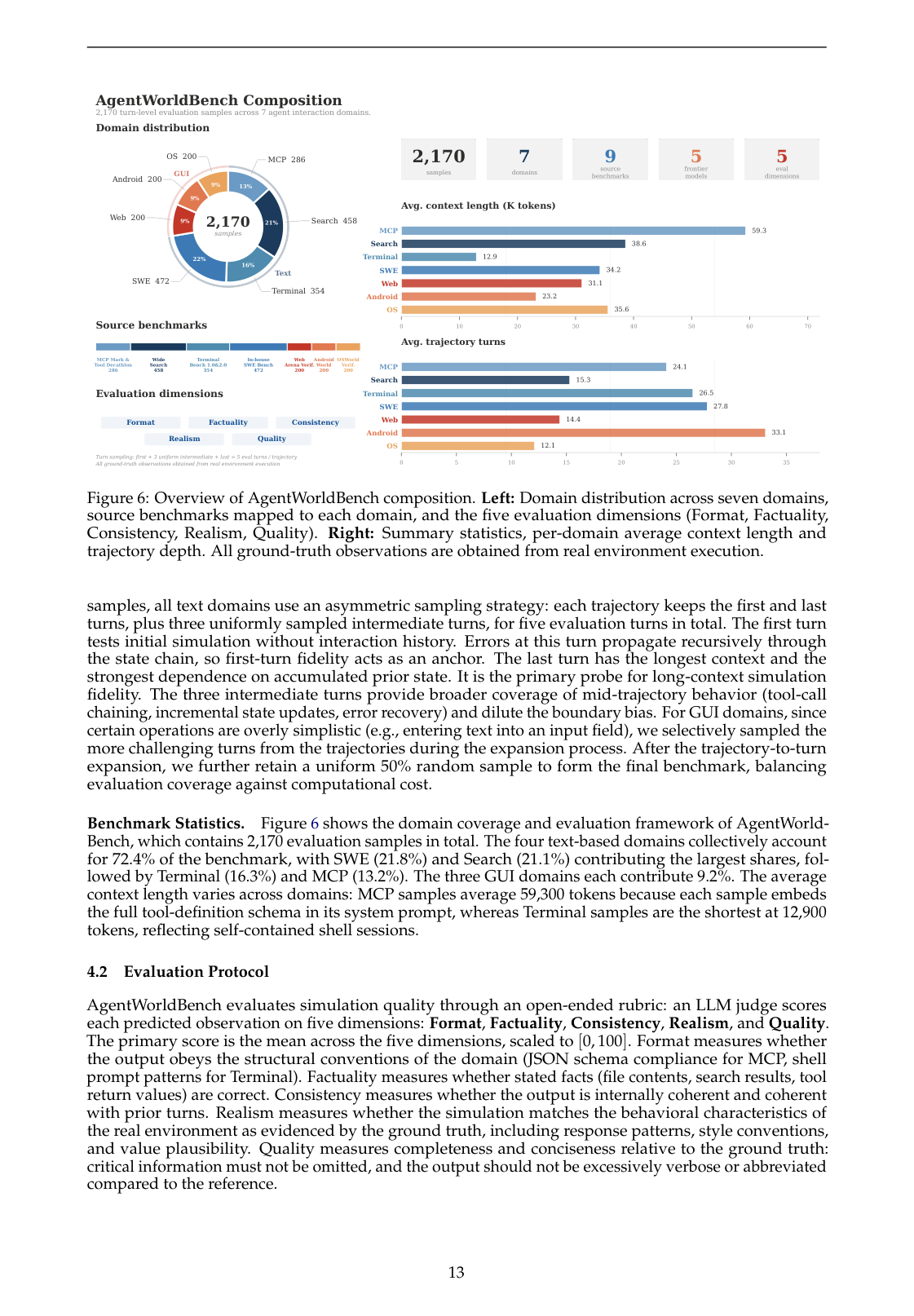
严格说,上图页面同时包含 AgentWorldBench 构成;但它也帮助理解论文中“训练—评测”是如何连起来的。
#5.1 Stage 1:Continual Pre-Training,注入世界知识
第一阶段是 CPT。它用 non-thinking trajectory 和专业语料,让模型获得基础的环境动态知识。
这里的关键不是让模型输出漂亮 reasoning,而是让模型在参数里吸收大量“数字世界常识”:
- shell 命令的副作用;
- API schema 和常见错误;
- 搜索结果的结构;
- GUI 状态变化;
- 软件工程中的测试/traceback 模式。
这有点像给模型做“环境继续预训练”。
#5.2 Stage 2:SFT,激活 next-state-prediction thinking
第二阶段是 SFT,让模型显式学会预测下一步 observation 的思考模式。
这一步开始从“被动吸收交互数据”转向“按任务格式输出环境反馈”。模型不仅要知道某个命令大概会怎样,还要在给定上下文、当前 state、当前 action 的情况下,生成具体下一步 observation。
#5.3 Stage 3:RL,用 reward sharpen 仿真质量
第三阶段是 RL。世界模型本身也做 RL,不是只做 SFT。
论文设计了 hybrid rubric-and-rule rewards:
- rubric judge 评估 Format、Factuality、Consistency、Realism、Quality 等维度;
- rule-based verification 检查更硬的结构与格式约束;
- 对不同 domain 设定不同 reward 细节。
为什么 world model 也需要 RL?因为 next-observation prediction 很多时候不是简单 token-level matching:真实环境输出可能有多种等价表达,但关键是要保持状态一致、因果正确、格式可用、不要泄漏不该泄漏的信息。RL 可以把模型从“像训练数据”推向“更像可用模拟器”。
#6. AgentWorldBench:怎么评估语言世界模型?
训练一个 world model 之后,最大的问题是:怎么知道它真的会模拟环境,而不是写得像?
论文提出 AgentWorldBench:它来自 5 个 frontier model 在 9 个已有 benchmark 上的真实交互轨迹,并覆盖七个 domain。每个样本都有真实环境执行得到的 ground-truth observation。
评估维度包括:
- Format:输出格式是否符合环境要求;
- Factuality:事实是否正确;
- Consistency:是否和历史状态一致;
- Realism:是否像真实环境会返回的东西;
- Quality:整体可用性。
这里我觉得最关键的是 Consistency 和 Realism。
因为 Agent 环境模拟最怕两种错误:
- 局部看起来合理,但状态不一致:比如前面创建的 ID 后面变了,文件系统状态前后矛盾;
- 语言上像真的,但环境机制错了:比如 terminal 错误码、API 返回字段、搜索 snippet 的信息粒度不符合真实环境。
这类错误会直接污染后续 Agent RL。因为 policy 会从错误世界里学到错误行动策略。
#7. 主结果:Qwen-AgentWorld 作为世界模型是否更强?
主实验在 AgentWorldBench 上比较了 Qwen-AgentWorld 和一系列 frontier / open-weight baselines。

论文结论是:
- Qwen-AgentWorld-397B-A17B 取得最高 overall average;
- 在 Terminal、SWE、MCP、Search 等文本型环境上优势更明显;
- GUI 环境如 Android / Web / OS 上也有竞争力,但文本化 GUI representation 仍然限制了上限;
- Search 是最难的 domain,因为真实网页内容变化快,长链检索中的 factual consistency 很难保持。
这组结果说明一件事:一般 frontier LLM 即使很强,也不自动等于好的 world model。会回答问题、会写代码、会 tool-use,和能稳定模拟环境动态,是相关但不同的能力。
这对 Agent 训练很重要。因为我们不能默认“拿一个最强 LLM 当 simulator”就够了;如果 simulator 没有经过专门 world-modeling 训练,它会在状态一致性、细粒度副作用、信息边界上出错。
#8. 用法一:把 Qwen-AgentWorld 当模拟环境做 Sim RL
第一种用法是 decoupled:Agent 和 world model 分开。Agent 是 policy,Qwen-AgentWorld 是 environment simulator。
这听起来像 model-based RL:不用每次都进入真实环境,而是在模型模拟出来的环境中进行训练。
但论文强调:这不是单纯为了省钱,而是因为 language world model 有两个真实环境没有的优势。
#8.1 Scalability:可以扩展出大量环境
真实环境 rollout 很贵、慢,而且很多环境状态难以批量构造。世界模型可以从少量真实 trace 出发,生成大量 OpenClaw-style environment,用来训练 Agent。
论文在 OpenClaw 上做了 out-of-distribution 测试:OpenClaw 不在训练环境中,但 Qwen-AgentWorld 可以模拟 4k OpenClaw environments,训练后带来 Claw-Eval 和 QwenClawBench 的提升。
#8.2 Controllability:可以构造现实中少见但训练价值高的环境
这是我认为最重要的点。
真实环境不一定经常暴露 Agent 的弱点。比如搜索任务中,真实搜索引擎可能直接把答案放在 snippet 里,Agent 就学会偷懒:看 snippet,不打开页面,不交叉验证。
世界模型可以故意控制环境:
- snippet 只透露部分信息;
- 搜索结果混入不同相关度页面;
- 构造虚构但自洽的数据库世界;
- 强迫 Agent 多步查询、打开网页、聚合证据。
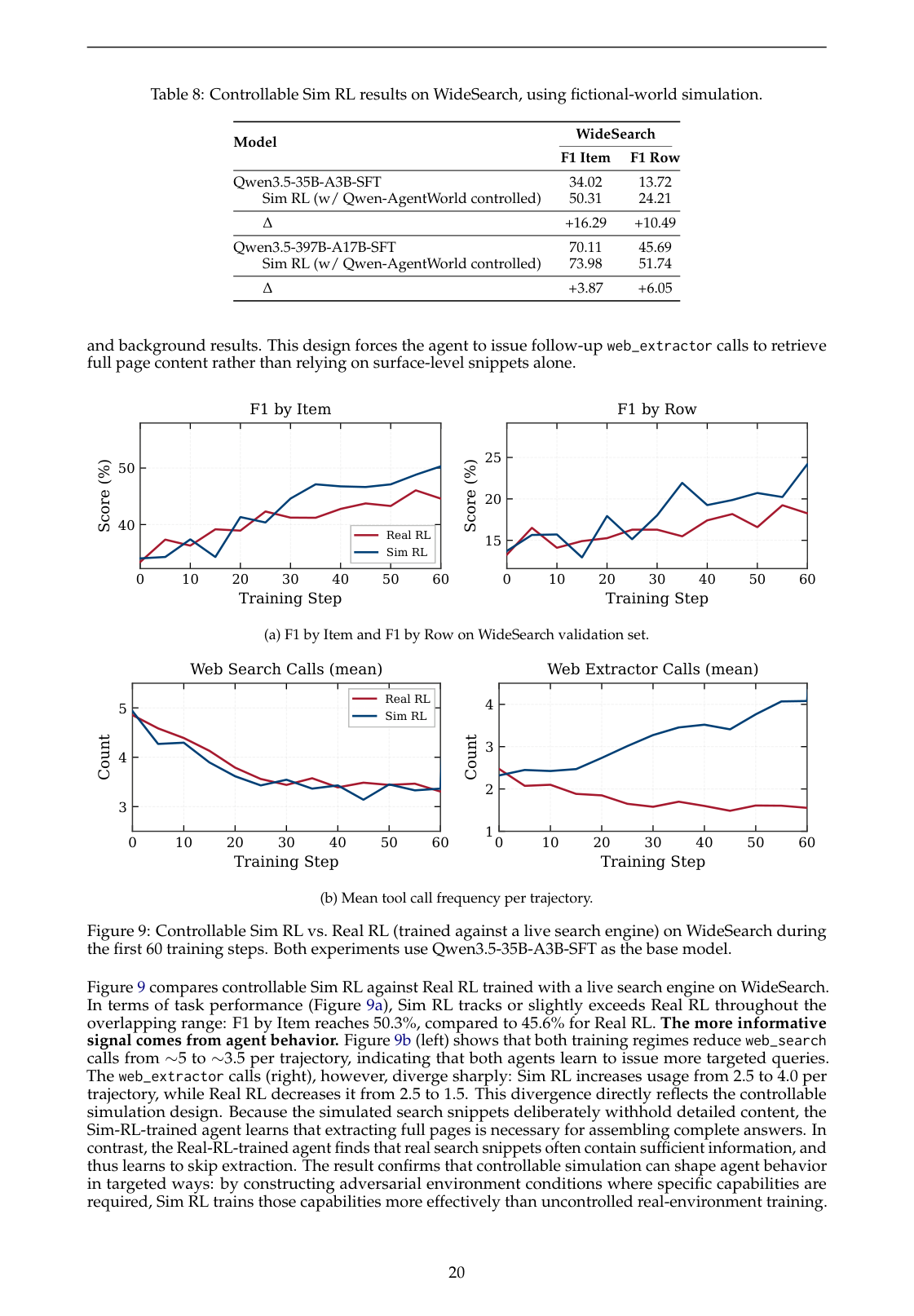
上图对应 WideSearch 实验。论文报告:
- 在 35B agent 上,controlled Sim RL 将 WideSearch F1 Item 从 34.02 提升到 50.31,F1 Row 从 13.72 提升到 24.21;
- 在 397B agent 上,也从 70.11 提升到 73.98,F1 Row 从 45.69 到 51.74;
- 和 Real RL 对比,Sim RL 在前 60 training steps 中 F1 by Item 达到 50.3%,高于 Real RL 的 45.6%。
更有意思的是行为变化:Sim RL 训练出的 agent 更倾向于增加 web_extractor 调用,而不是只依赖 search snippet。这说明可控模拟不是简单提高 reward,而是在塑造更好的信息获取策略。
这对长轨迹 Agent RL 很关键:我们真正想要的不是“在已有环境里刷分”,而是能系统性制造训练 curriculum,让 agent 被迫学习真实任务中需要的策略。
#9. 用法二:把 world model training 当 Agent warm-up
第二种用法是 unify:不把 world model 只当外部 simulator,而是把 LWM 训练过的模型继续作为 Agent 使用。
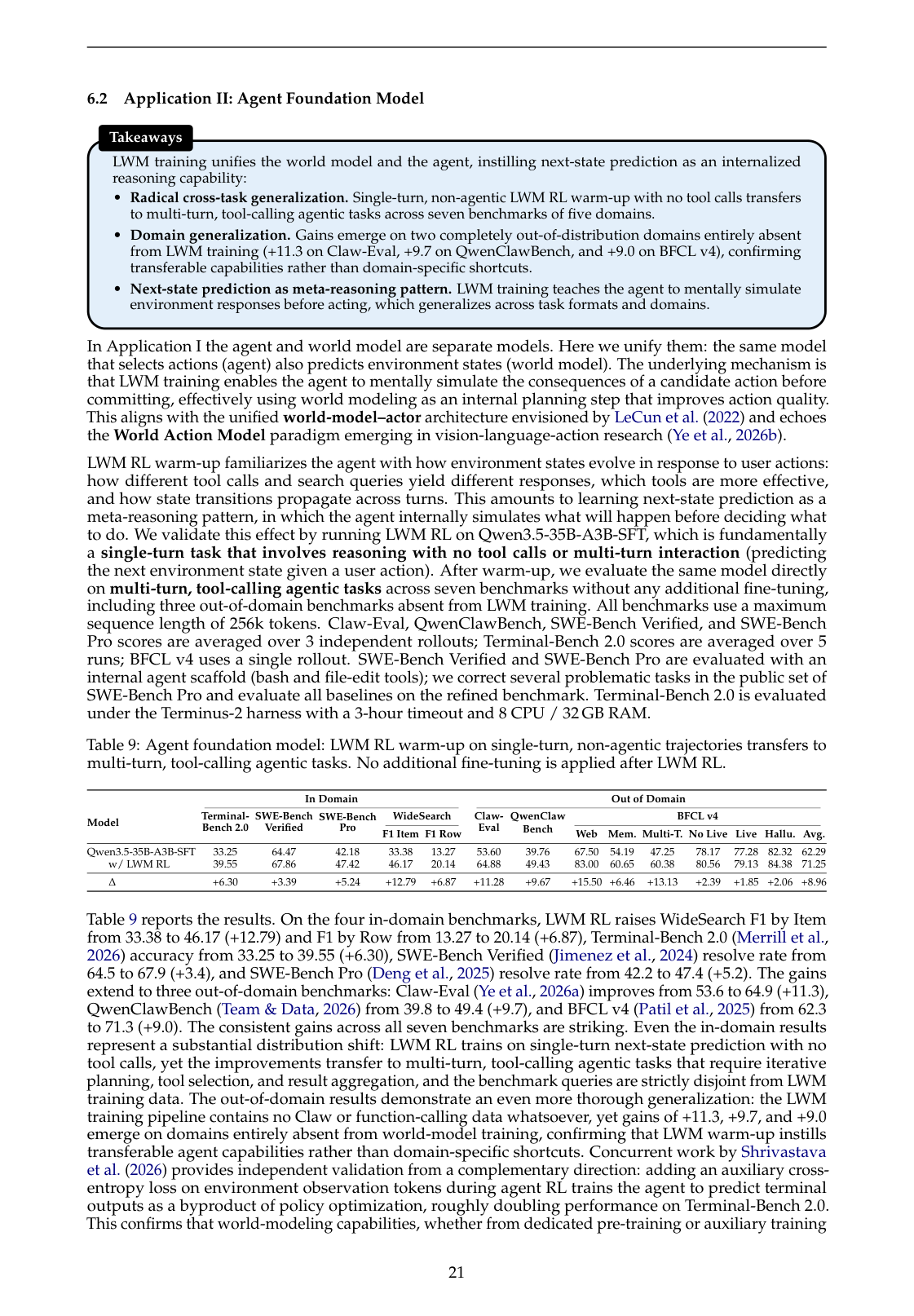
这里的逻辑是:如果一个模型已经学会预测环境反馈,它再去做 Agent 时,应该更会在行动前做 mental simulation。
论文发现,LWM RL 虽然训练的是单步 next-state prediction,没有真实 tool call,但它迁移到下游多步 agentic benchmarks 后仍然带来提升。也就是说,世界模型训练不是只让模型“会扮演环境”,而是给模型注入了一种可迁移的 agent 能力。
论文报告它在 7 个 agentic benchmark 上有一致收益,包括:
- Terminal-Bench 2.0;
- BFCL v4;
- SWE-Bench Pro;
- WideSearch;
- Claw-Eval;
- QwenClawBench 等。
这点对“Agent 预训练数据如何塑造能力”非常有启发:也许 Agent foundation model 不应该只预训练在 instruction / tool-use demonstration 上,还应该大量预训练在 environment dynamics 上。
换句话说,模型不只是学“专家怎么做”,还要学“世界怎么变”。
#10. 为什么 warm-up 有效?预测驱动的行动修正
论文的机制解释叫 Prediction-Driven Action Refinement。
直白说:LWM 训练让模型在行动前更会脑内模拟环境反馈,然后据此修正动作。
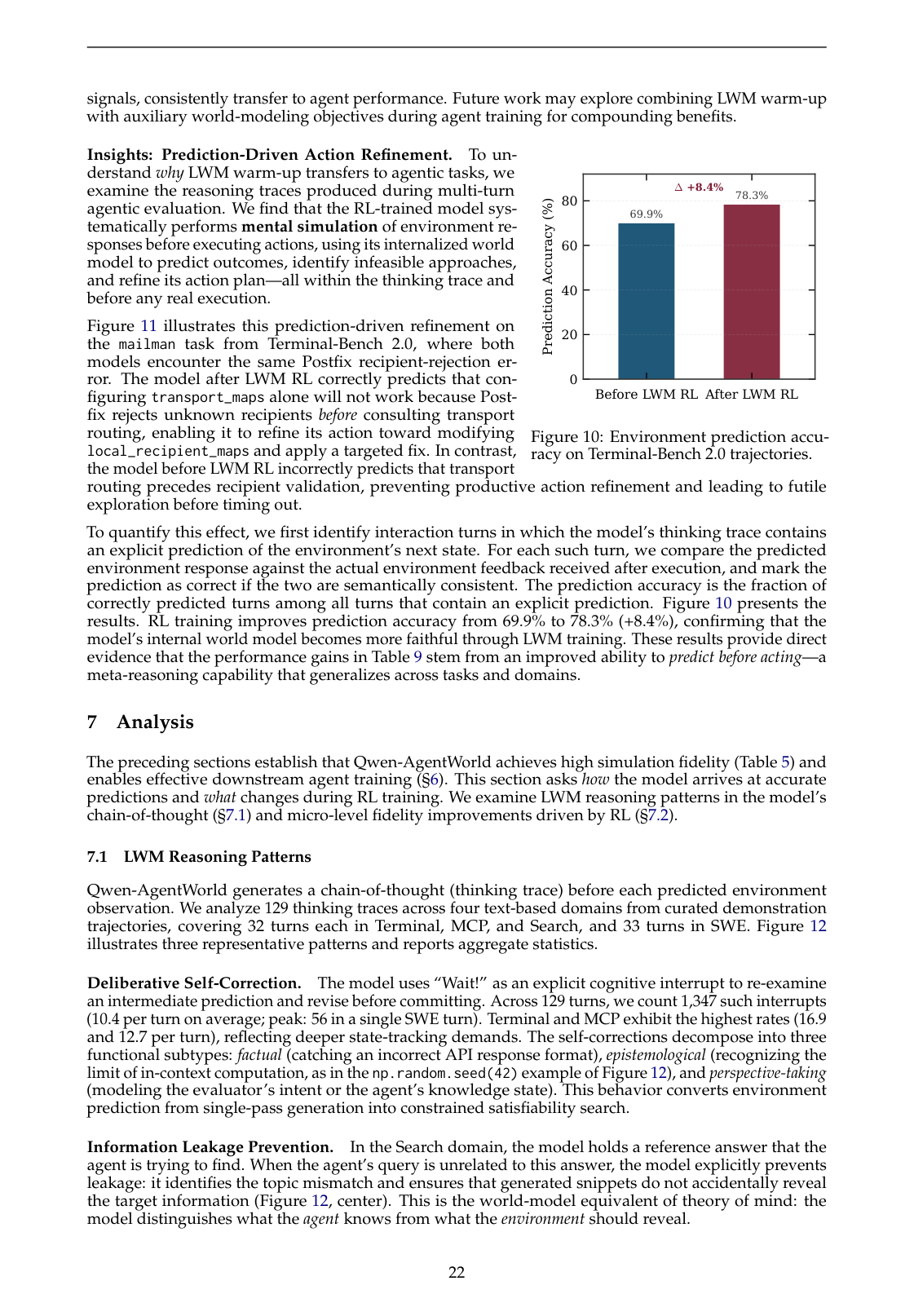
论文在 Terminal-Bench 2.0 上检查模型 reasoning trace 中显式预测环境下一状态的片段,并比较预测和真实环境反馈是否语义一致。结果是:
- LWM RL 前预测准确率:69.9%;
- LWM RL 后预测准确率:78.3%;
- 提升:+8.4%。
这说明 world-model training 不只是提升 benchmark 分数,也确实让模型内部的 next-state prediction 更准。
论文举了一个 mailman / Postfix 的例子:两个模型都遇到 recipient rejection error。LWM RL 后的模型能预测到:只改 transport_maps 不够,因为 Postfix 会在 transport routing 之前先拒绝 unknown recipient;因此它转向修改 local_recipient_maps。而 LWM RL 前的模型误判了系统机制,于是继续在错误方向上探索,最后超时。

这个案例很典型:很多 Agent 失败并不是语言能力不足,而是环境机制模型错了。它不知道某个系统的因果链,导致计划在错误假设上不断递归。
world model training 的价值就在这里:它让模型在内部形成更可靠的“环境因果模型”。
#11. 这篇论文和 model-based RL 的关系
从 RL 视角看,Qwen-AgentWorld 的结构很像把 LLM Agent 拉回 model-based RL 的范式:
| 传统 RL / 机器人 | Qwen-AgentWorld 中的对应物 |
|---|---|
| state | 文本化 observation / GUI hierarchy / terminal state |
| action | tool call / shell command / browser click / API request |
| dynamics model | Language World Model |
| rollout in simulator | Sim RL in Qwen-AgentWorld |
| policy improvement | agentic RL / downstream agent training |
| model pretraining | LWM CPT / SFT / RL |
但它也有一个巨大差别:LLM Agent 的环境是开放文本环境,很多 transition 没有 deterministic program 可以写出来。
例如 search engine、MCP server、网页、真实软件仓库,它们不像 Atari 或 MuJoCo 那样容易定义完整状态转移函数。Qwen-AgentWorld 的路线是:用大模型直接学习这种文本世界的近似 transition。
这会带来一个 trade-off:
- 好处:覆盖范围极广,能模拟很难程序化的环境;
- 坏处:无法保证完全真实,simulator bias 会影响 Agent RL。
所以论文中特别强调 controllability 和 verification。未来真正困难的问题可能不是“能不能生成像真的环境反馈”,而是:
如何知道哪些模拟反馈足够可信,可以拿来训练 policy?
这会牵涉到 uncertainty estimation、sim-to-real routing、hybrid real/sim RL、verifier、environment state grounding 等问题。
#12. 我认为这篇论文最重要的三个启发
#12.1 Agent RL 不应该只依赖真实环境 rollout
真实环境当然重要,但只靠真实环境有几个瓶颈:
- rollout 慢;
- 环境不可控;
- 稀有错误难覆盖;
- 难系统性构造 curriculum;
- 长轨迹任务中的探索成本极高。
Qwen-AgentWorld 给出了一条补充路径:先训练一个语言世界模型,再用它批量生成可控训练环境。
这和我一直关心的长轨迹 Agent RL 问题非常相关。长轨迹直接 RL 很容易卡在 sparse reward、credit assignment、环境成本和探索效率上。一个足够好的 language world model 可以成为中间层:
真实环境少量校准 + 世界模型大量模拟 + policy 在模拟中练习 + 关键点回真实环境验证
这比“无限堆真实 rollout”更像可持续路线。
#12.2 Agent foundation model 需要学环境动态,而不只是学人类示范
很多 Agent 训练数据是 demonstration:专家如何调用工具、如何分解任务、如何写 reasoning。
但 demonstration 学到的是 policy prior:别人怎么做。
world-model data 学到的是 dynamics prior:世界怎么变。
这两者都重要。特别是当 Agent 遇到新任务时,单纯模仿过去动作可能不够;它需要预测动作后果,才能做真正的规划。
这篇论文的 LWM warm-up 结果说明,next-state prediction 本身可以成为 Agent 预训练目标。
#12.3 “可控环境生成”可能比“更大模型”更能推动 Agent 能力边界
我觉得论文里最有未来感的是 controllable simulation。因为它意味着我们可以主动设计训练世界:
- 让搜索环境隐藏答案,逼迫模型多步检索;
- 让 API 返回边界错误,逼迫模型处理异常;
- 让 terminal 状态带有隐蔽副作用,逼迫模型维护状态;
- 让 SWE repo 构造特定依赖冲突,逼迫模型学 debugging;
- 让 MCP 工具链出现 schema drift,逼迫模型学鲁棒调用。
这本质上是在用环境设计塑造智能体能力。
对于 Agent 来说,训练数据不只是“更多任务”,而是“什么样的世界会逼出什么样的能力”。
#13. 局限和需要谨慎的地方
这篇论文很强,但也有几个必须谨慎看待的点。
#13.1 语言世界模型可能产生 simulator bias
如果模拟环境和真实环境存在系统性偏差,Agent 会学到错误策略。
例如:
- search snippet 太理想化;
- terminal 错误输出不完全符合真实系统;
- GUI 状态转移遗漏视觉细节;
- API 返回字段过于规整;
- SWE traceback 与真实依赖环境不一致。
Sim RL 越强,越要防止 policy overfit simulator。
#13.2 GUI / multimodal 环境仍然受文本化表示限制
论文覆盖 Android、Web、OS,但主要通过 accessibility tree、HTML、UI hierarchy 等文本表示。对很多 GUI 任务来说,视觉布局、图像、空间关系、动态动画都很重要。
所以未来很自然的方向是 multimodal LWM:把截图、DOM、accessibility tree、动作轨迹统一起来。
#13.3 评估 world model 仍然很难
AgentWorldBench 是一个重要尝试,但 world model 的好坏不只体现在单步 observation prediction 上。长期 rollout 中,微小状态错误会递归放大。
未来更需要评估:
- 多步 rollout 稳定性;
- 状态一致性随时间衰减;
- simulator-trained policy 的 sim-to-real transfer;
- 何时应该 trust simulator,何时必须回真实环境。
#13.4 数据闭源和可复现性仍有限
论文发布了代码/模型相关入口,但这类超大规模 agent-environment trajectory 的构建本身很重,很多关键数据来自内部基础设施和内部开发轨迹。外部研究者要完全复现训练 pipeline 会很困难。
#14. 和我关心的方向怎么连接?
这篇论文和几个方向直接相连。
#14.1 LLM model-based RL / Dreamer for LLM Agent
Qwen-AgentWorld 基本就是在给 LLM Agent 构建 dynamics model。它还没有完全走到 Dreamer 那种 latent imagination + policy learning 的形态,但方向非常接近:
- 学一个世界模型;
- 在模拟中训练 policy;
- 用环境预测提升 planning;
- 把真实环境成本降下来。
不同之处是它目前主要在文本 observation 空间中模拟,而不是 latent state space 中滚动。未来一个很自然的问题是:
LLM Agent 的 world model 是否应该在 token 空间预测 observation,还是在 latent state 空间预测压缩后的环境状态?
这和 latent-space reasoning / latent world model 直接相关。
#14.2 长轨迹 Agent RL 的可持续性
长轨迹 Agent RL 最大的问题是 rollout 成本高、reward 稀疏、探索低效。Qwen-AgentWorld 给出的答案是:
- 用 LWM 生成可控训练环境;
- 用 Sim RL 提供更密集、更便宜、更可设计的经验;
- 用真实环境做校准和最终验证。
这比纯 Real RL 更像一条可持续扩展路线。
#14.3 Agent 预训练数据如何塑造能力
论文证明了一个重要观点:环境动态预测数据可以提升下游 Agent 能力。也就是说,Agent pretraining 不一定只靠 task solution / tool-use trace,还可以靠“预测环境反馈”。
这会引出一类新的数据问题:
- 哪些环境 transition 最能塑造 planning 能力?
- 哪些 error pattern 最能提升 debugging?
- 哪些 controllable adversarial environment 最能提升鲁棒性?
- world-model data 和 demonstration data 应该怎么混合?
这可能比单纯扩大 instruction tuning 数据更基础。
#15. 总结:这篇论文真正打开的是“环境扩展轴”
我会把 Qwen-AgentWorld 的贡献概括成四句话:
- 它把 LLM Agent 的环境动态建模成一个统一的 next-observation prediction 问题。
- 它用 CPT → SFT → RL 训练出覆盖七类交互环境的 language world model。
- 它证明世界模型既可以作为外部 simulator 做 Sim RL,也可以作为 Agent warm-up 提升下游能力。
- 它最重要的启发是:扩展 Agent 不一定只靠更多真实 rollout,也可以靠可控、可扩展、可设计的语言世界。
如果说以前的 Agent 训练主线是:
更多任务 → 更多示范 → 更强 policy
那么 Qwen-AgentWorld 指向的是另一条线:
更多环境动态 → 更强世界模型 → 更高效的 agentic RL / planning
对未来通用 Agent 来说,policy 和 world model 可能会变成两个同等重要的基础能力:一个决定“我该怎么做”,另一个决定“我做了以后世界会怎样”。真正强的 Agent,应该是在两者之间不断循环:先想象,再行动;从真实世界校准模型,再用模型扩展经验。
这也正是这篇论文最值得关注的地方。