#MiniMax-M2.7 技术报告详解:10B 激活参数如何撑起 Agentic Intelligence
论文/技术报告:The MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence
机构:MiniMax
时间:2026-05-26
arXiv:<https://arxiv.org/abs/2605.26494>
#0. 先用一句话讲清楚
MiniMax-M2.7 这份技术报告的主线不是“又做了一个更大的模型”,而是:
用 229.9B 总参数、每 token 只激活约 9.8B 参数 的 MoE 模型,配合面向真实 agent 任务的数据、强化学习系统和自演化工作流,把“小激活量”转化成接近闭源前沿模型的真实任务能力。
报告标题里的 Mini Activations Unleashing Max Real-World Intelligence 很关键。它不是简单宣传语,而是整篇报告的技术主张:
- 模型侧:用细粒度 MoE、sigmoid gating、full attention、192K 长上下文和 MTP,让单步激活算力尽量低,但模型容量足够大。
- 数据侧:不只做问答/偏好数据,而是围绕 coding、AppDev、终端、搜索、办公、金融、幻灯片等真实 agent 工作流构造“带环境、带验证、带奖励”的训练数据。
- RL 侧:把 LLM 当 policy,把 context management、工具调用、memory、agent loop 都当环境,构建 Forge 这样面向长轨迹 agent 的 RL 系统。
- agent 机制侧:强调 interleaved thinking,也就是“边想、边用工具、边根据观察修正计划”,而不是一次性前置长 CoT。
- 自演化侧:M2.7 已经能参与调试训练运行、修改 agent scaffold、自动跑多轮 ML 工程迭代;这被报告视为 early operational self-evolution。
如果把这篇报告放到 wenjun 关心的 LLM Agent、agentic RL、self-evolving code agent、基础模型训练范式 里看,它的价值不只在分数,而在它把几条趋势串到了一起:
- MoE 低激活成本 是 agent 长轨迹推理/工具调用可规模化的前提;
- 长上下文 + full attention 是让 agent 带着完整工作状态行动的底座;
- 可执行环境和 verifiable reward 是 agent RL 真正有效的核心资产;
- 训练系统本身 agent-native,才可能支持任意复杂 scaffolds 的黑盒/白盒训练;
- 模型参与改进自己的 scaffold,是从“后训练模型”走向“模型辅助模型迭代系统”的开端。
下面按“架构 → 数据 → SFT/RL → Forge 系统 → agent 机制 → 自演化 → 实验结果 → 批判性理解”来讲。
#1. 为什么 MiniMax-M2.7 的关键词是 agent,而不是 chat?
报告开头指出,大模型正在从短对话迁移到长时程 agentic workflows:
- 写和维护生产级代码;
- 在开放网页中搜索、交叉验证、生成报告;
- 操作工具、API、表格、幻灯片、终端环境;
- 在数百步 interleaved reasoning/action 中完成任务。
这类任务暴露出两个传统 chat model 不够重视的问题:
#1.1 长轨迹带来训练和推理成本瓶颈
Agent 任务不是“输入一个问题,输出一个答案”,而是:
看任务 → 思考 → 调工具 → 读观察 → 修计划 → 再调工具 → 写代码 → 跑测试 → 看报错 → 修复 → 汇报
每一步都可能触发一次 LLM completion。上下文会越来越长,工具输出、日志、文件片段、网页证据都会进入上下文。于是模型如果每 token 激活参数太大,成本会被 agent 轨迹长度放大很多倍。
这就是 M2 系列强调 9.8B activated parameters 的原因:它不是为了在单轮 benchmark 上省一点钱,而是为了让长轨迹 agent 的每一步都能承受。
#1.2 真正有用的 agent 任务必须能验证
很多开放式对话数据无法可靠判断“做对了吗”。但 agent 任务如果设计得好,天然可以有强反馈:
- 代码任务可以跑测试;
- 终端任务可以检查文件、命令输出、系统状态;
- AppDev 可以检查页面能不能运行、交互是否正确、视觉是否达标;
- 搜索任务可以要求证据链;
- 表格/金融任务可以检查公式、数值、文件产物。
MiniMax-M2.7 的报告反复强调一个观点:reward 的质量和可信度,是释放 base model 潜力的关键。这点比“用了什么 RL 算法”更重要。
#2. 模型架构:229.9B 总参数,但每 token 只激活 9.8B
M2 是一个稀疏 MoE decoder-only Transformer。核心规格如下:
| 项目 | M2 规格 |
|---|---|
| 总参数 | 229.9B |
| 每 token 激活参数 | 9.8B |
| 层数 | 62-layer decoder-only Transformer |
| hidden size | 3072 |
| vocab size | 200,064 |
| 预训练 token | 29.2T |
| 最大上下文 | 192K |
| attention | full multi-head attention + GQA |
| query heads / KV heads | 48 / 8 |
| MoE experts | 256 fine-grained experts |
| 每 token 激活 experts | top-8 |
| 额外模块 | Multi-Token Prediction, MTP |
这个设计的目标很明确:容量大,但激活小;上下文长,但质量不能牺牲;推理快,但输出质量等价于标准自回归解码。
#2.1 Fine-Grained MoE:更多更小的专家
报告中 MoE 的三个关键改动是:
- Fine-Grained Experts:用更多、更小的专家提高路由组合多样性。
- Sigmoid Gating:不用 softmax top-k 的零和竞争,而是给每个 expert 独立激活分数。
- Expert Bias:给 expert routing score 加可学习 bias,隐式调节专家利用率,减少对 auxiliary load-balancing loss 的依赖。
直白讲,传统 softmax gating 会让专家之间互相竞争:一个 expert 分高,其他 expert 分数相对就被压低。sigmoid gating 则更像“每个 expert 自己判断要不要参与”,多个 expert 可以同时高置信激活,这可能让路由更平滑。
报告的 Table 1 做了一个小规模消融:baseline、加 MTP、加 fine-grained experts 三种模型保持 2B activated / 17.8B total / 500B training tokens 不变。Fine-Grained 版本把 expert 数从 32 提到 128,top-k 从 2 提到 8,在 MATH、MMLU、ARC-Challenge、HumanEval 上多数最好。
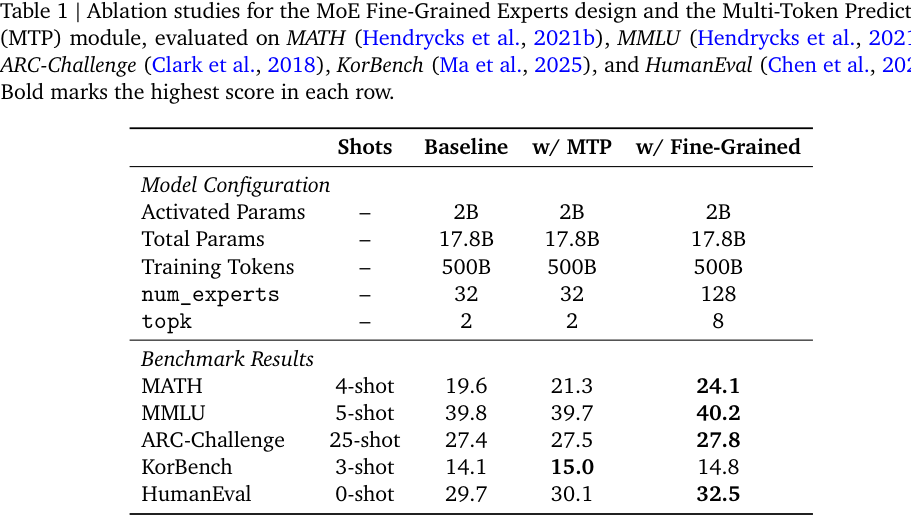
这里最值得关注的不是某个小分数,而是设计哲学:
当总激活参数固定时,把 FFN 容量切成更细颗粒,让 token 可以组合更多 expert,可能比少数大 expert 更有表达力和负载均衡优势。
这对 agent 模型尤其重要,因为 agent 任务分布非常杂:代码、网页、工具、表格、自然语言推理、错误日志、UI 描述都混在一起。更细粒度的专家组合,可能更适合这种 heterogeneous distribution。
#2.2 为什么 M2 坚持 full attention?
这是报告里一个很有意思的技术判断。M2 没有继续使用 MiniMax-Text-01 里的 hybrid attention,而是在所有层采用 full multi-head attention。
原因不是他们不知道 full attention 贵,而是他们认为:
- linear/sparse/sliding-window attention 在标准短 benchmark 上可能看起来没差;
- 但规模上去后,在复杂多跳推理、长上下文 agent、retrieval、in-context learning 上会暴露缺陷;
- proxy benchmark 与真实下游能力的相关性不稳定;
- 线性/稀疏注意力的工程栈也还不如 full attention 成熟,比如 prefix caching、低精度 KV、speculative decoding 集成等。
报告中 hybrid SWA 的实验结论很直接:
- 预训练阶段,SWA 在 128K RULER、MTOB translation 等长上下文任务上明显更差;
- SFT 后,超过 32K context 的 agent 任务和复杂长上下文任务差距更明显;
- 32K 以下,有些任务 SWA 可以持平甚至略好,但长上下文覆盖限制会伤害复杂 agent 能力。
这对当前长上下文模型设计有一个现实提醒:
省 attention 计算很诱人,但如果目标是长程 agent,而不是短问答,attention coverage 的损失可能在常规 benchmark 上被低估。
当然,报告也承认 sub-quadratic attention 长期会越来越重要,只是当前 M2 的生产质量目标下,full attention 更稳。
#3. MTP:既是训练信号,也是推测解码 draft path
M2 使用 Multi-Token Prediction(MTP)。它让模型不仅预测下一个 token,还训练额外模块预测更远的 token。
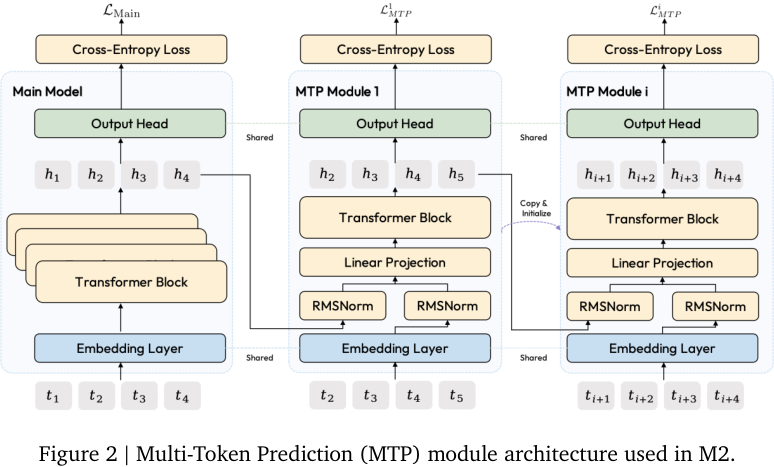
MTP 在 M2 里有两层意义。
#3.1 训练阶段:更丰富的多步预测信号
预训练初期,M2 使用一个 MTP 模块,loss weight 从 0.3 anneal 到 0.1。报告认为 MTP 在 reasoning-heavy 任务上收益较明显。
直觉是:next-token prediction 只要求模型预测一步,而 MTP 要求模型对未来多个 token 的走向也形成表示。这可能让 hidden states 更早捕捉“接下来几步会发生什么”。
#3.2 推理阶段:用于 speculative decoding
在 continued pretraining 的 decay phase,M2 从一个 MTP module 扩展到三个,也就是支持多步 speculative decoding。关键细节是:
- 不随机初始化 MTP modules,而是从主模型复制权重;
- 先冻结主模型,只训 MTP modules 到 loss 稳定;
- 再切换到主模型和 MTP modules 联合训练;
- 推理时由 MTP modules 生成 draft tokens,再由主模型一次 forward 验证。
这和 agent 推理很相关:agent 轨迹长、completion 多,如果每一步都能用 speculative decoding 提升吞吐,整体收益会被放大。
更关键的是,报告后面在 Forge 的 inference acceleration 中提到:MTP 模块会在 RL 中与 policy 通过 top-K KL divergence loss 持续共同训练,以防 RL policy 分布漂移后 draft acceptance rate 掉下去。这说明 MTP 不只是预训练附属模块,而是和 agent RL 系统联动的吞吐基础设施。
#4. 预训练数据:29.2T tokens 与 192K 长上下文
M2 的预训练分为:
- constant phase:19.9T tokens;
- decay phase:9.3T tokens;
- 总计:29.2T tokens。
数据来源包括网页、学术文献、书籍、代码、结构化 QA 等。报告特别提到对代码、数学、STEM 做了上采样,并用 model-based reward scoring 和辅助分类器做质量评估。
#4.1 长上下文扩展:8K → 32K → 192K
M2 的 context window 从 8K 逐步扩到 32K,再到 192K。长上下文数据主要来自:
- 高质量代码拼接;
- 自然长篇 PDF 文档;
- 主题相关文档打包。
这里要注意,192K 对 agent 不只是“能塞更多文本”,而是让模型在一个 episode 里保留更完整的工作状态。尤其如果采用 interleaved thinking,把 thinking blocks、工具调用、工具返回、日志和中间结论都保留在上下文中,长上下文就直接决定 agent 是否能持续自我修正。
#5. 后训练数据:从“答案数据”转向“可执行工作流数据”
MiniMax-M2.7 报告最重要的部分之一,是后训练数据管线。它覆盖五类能力:
- Agentic Coding;
- Agentic Cowork;
- Reasoning-intensive tasks;
- General-purpose conversation and writing;
- Role-play and persona coherence。
其中与 M2.7 的 agent 能力最相关的是前两类。
#5.1 Agentic Coding:SWE、AppDev、Terminal 三条线
报告将 coding agent 数据分成三个互补域:
- SWE:仓库级软件工程任务;
- AppDev:全栈应用开发任务;
- Terminal interaction:真实终端环境中的调试、配置、脚本、系统操作任务。
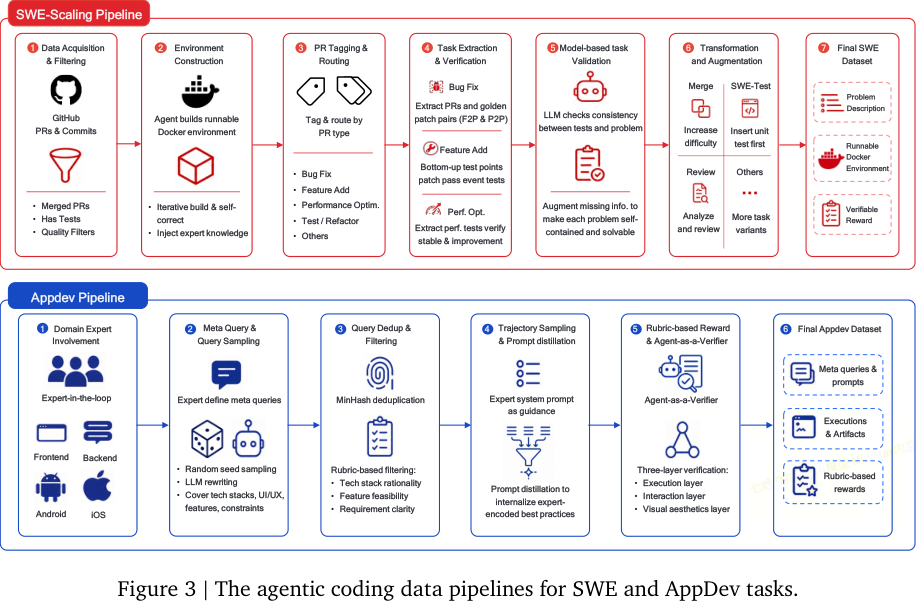
#SWE-Scaling Pipeline
SWE 数据从真实 GitHub PR 出发,但不是直接拿 PR 当训练数据,而是经过一整套转换:
- 收集 permissive license 下的 public GitHub PR 和 linked issues;
- 过滤 merged PR、有测试、质量较高的样本;
- 由 agent 构建可运行 Docker 环境;
- 对 PR 类型做 tagging/routing:bug fix、feature add、performance optimization、test/refactor 等;
- 针对不同 PR 类型构造不同 verifiable reward;
- 用模型检查 tests 与 problem statement 的一致性,补全缺失信息;
- 做 task transformation/augmentation,增加难度和任务变体;
- 输出包含 problem description、runnable Docker environment、verifiable reward 的最终数据。
这个流程的重点是:训练样本不是静态文本,而是一个可执行任务包。
#AppDev Pipeline
AppDev 更偏完整应用开发,包括 frontend、backend、Android、iOS 等。它从 domain expert 定义 meta queries 开始,再做随机采样、LLM rewriting、去重、rubric-based filtering、trajectory sampling 和 prompt distillation。
最有意思的是 Agent-as-a-Verifier:
- execution layer:能不能跑;
- interaction layer:交互是否符合要求;
- visual aesthetics layer:视觉是否达标。
也就是说,奖励不只是“代码测试过了”,还包括用户真正关心的交互和视觉产物质量。
#Terminal-Gym
Terminal-Gym 从 Stack Overflow 等真实编程/系统操作场景出发,构造 terminal-compatible、Linux/Docker-relevant、scriptable、verifiable 的任务。它强调:
- 任务描述要结构化;
- 环境要能自动生成;
- reward 要可验证;
- 难度可以动态演化。
这类数据对 code agent 很关键,因为现实中 agent 经常不是单纯改代码,而是在 shell 里安装依赖、跑测试、看日志、调配置、修环境。
#5.2 Agentic Cowork:搜索、办公、金融、幻灯片
M2.7 不是只做 coding agent,也做更广的 knowledge-worker agent。报告包括:
- Deep Search / Open-Web Research:多步网页浏览、跨来源证据综合;
- Office Tasks:报告、memo、结构化文档;
- Financial Analysis / Spreadsheet Operations:表格、公式、金融建模;
- Slide Generation and Editing:幻灯片生成与编辑。
Deep Search 数据管线尤其值得注意:它会从 seed question 出发,逐步 rewrite 和 obscure entities,让问题变得更难,以区分强弱 agent。同时,每个任务配 evidence specification,只有答案基于实际检索证据才接受。对于没有唯一短答案的 report-style query,则用 rubric-based judge 从 factual accuracy、transparency、uncertainty handling、risk disclosure 等维度评分。
这里的思想是:
未来 agent 能力的关键训练对象,不是“问答对”,而是“任务 + 环境 + 证据 + 产物 + 验证标准”。
#6. SFT:先把 interleaved thinking 教进去
M2 的 SFT 不是传统的单块长 CoT。报告明确说,SFT 的目标是让模型学会 interleaved thinking behavior。
传统 CoT 往往是:
Question → 一大段 reasoning → Answer
而 agent 轨迹更像:
Thinking → Tool Call → Observation → Thinking → Tool Call → Observation → ... → Final
所以 M2 的 SFT 数据会把 thinking traces 与 intermediate actions/observations 交织在同一轨迹中,让模型学会在行动后根据环境反馈修正自己的推理。
这一步很重要,因为 RL 如果从不会用工具、不会维护 reasoning state 的模型开始,探索成本会非常高。SFT 相当于先给模型一个好的 agent 行为先验,再用 RL 优化。
#7. RL 算法:把模型外的一切都当环境
M2.7 的 RL 形式化很适合理解 agentic RL。
#7.1 MDP 边界:LLM 是 policy,agent loop 是 environment
报告把 agent-environment interaction 建模为 MDP:
- state :当前上下文窗口,包括任务指令、历史、工具输出、产物等;
- action :一次 LLM completion,可能包含自然语言推理、工具调用、context management 操作、sub-agent 通信等;
- observation :环境执行工具/操作后返回的观察;
- transition:由工具、agent harness、memory、context management 决定。
关键设计原则是:
边界画在模型生成接口处。模型生成之外的一切,包括工具环境、上下文管理、memory access、agent state transition,都视为 environment dynamics。
这点非常重要。因为真实 agent scaffold 千差万别,如果 RL 系统试图把所有 agent 内部逻辑都纳入 policy,就会不可扩展。M2.7 的做法是:policy 只负责在给定 context 下生成下一步,环境负责执行和更新状态。
#7.2 CISPO:带 clipped importance sampling 的 policy optimization
报告使用 MiniMax 之前提出的 CISPO(Clipped Importance Sampling Policy Optimization)。直觉上,它通过 importance ratio 调节 old policy 采样出来的数据对 current policy 的梯度贡献,并做非对称 clipping:
- 上界防止过大的 policy update;
- 下界允许把当前 policy 下不太可能的动作大幅降权;
- stop-gradient 保证 importance weight 只调节梯度幅度,不引入二阶项。
这里不必纠结公式细节。更关键的是:M2.7 的 RL 难点不是单轮偏好优化,而是长达 192K tokens、上千中间动作的 agent trajectory。算法必须处理 off-policy、长轨迹 credit assignment、异步 rollout 和训练稳定性。
#7.3 Reward 设计:不能只有 outcome reward
报告认为,长轨迹 agent 只用最终 outcome reward 不够,因为 credit assignment 太稀疏。它设计了 composite reward:
- Process Reward:奖励结构良好的中间推理,惩罚语言混杂、工具调用格式错误等;
- Task Completion Time Reward:奖励更快完成任务,鼓励并行工具调用、减少无效等待;
- Performance Reward:主要任务表现信号;
- Reward-to-go with baseline:降低长轨迹梯度方差。
最值得注意的是 completion time reward。传统 RL 只优化“对不对”,但 agent 在真实产品里还必须“快不快”。同样正确的两条轨迹,一个顺序调用十个工具,一个并行调用,用户体验和成本完全不同。M2.7 把这个纳入 reward,是很实际的 agent 产品化思路。
#7.4 Mixed-domain RL:避免只会 agent,忘掉基础能力
如果只在 agentic tasks 上 RL,模型可能损害基础推理、知识、通用对话能力。报告采用 mixed-domain RL:在每个训练阶段同时混合 reasoning、coding、agent、general 四类数据,并逐阶段调节:
- domain mixing ratios;
- context length;
- reward weights / difficulty;
- training stages。
这反映了一个重要经验:
Agent 能力不是孤立能力,它依赖基础推理、知识、代码、指令跟随、格式稳定性。RL 不能只在单一 agent benchmark 上猛冲。
#8. Forge:面向长轨迹 Agent RL 的训练系统
如果说数据和 reward 是 fuel,那么 Forge 是让这些 fuel 真正烧起来的发动机。
报告把大规模 agent RL 的基础设施问题称为一个 “impossible triangle”:
- System Throughput:吞吐要高;
- Training Stability:policy gradient 方差要可控,训练要稳定;
- Agent Flexibility:支持任意 agent 架构,包括单轮 scaffold、多 agent 系统、动态 context management、黑盒 API agent。
这三者互相冲突:
- 追求吞吐会倾向于先训练短任务,造成分布偏移;
- 任意 agent scaffold 会破坏训练系统对 state transition 的可见性;
- 长轨迹 credit assignment 又会让调度和数据处理成本爆炸。
#8.1 Forge 总架构:agent、middleware、engine 解耦
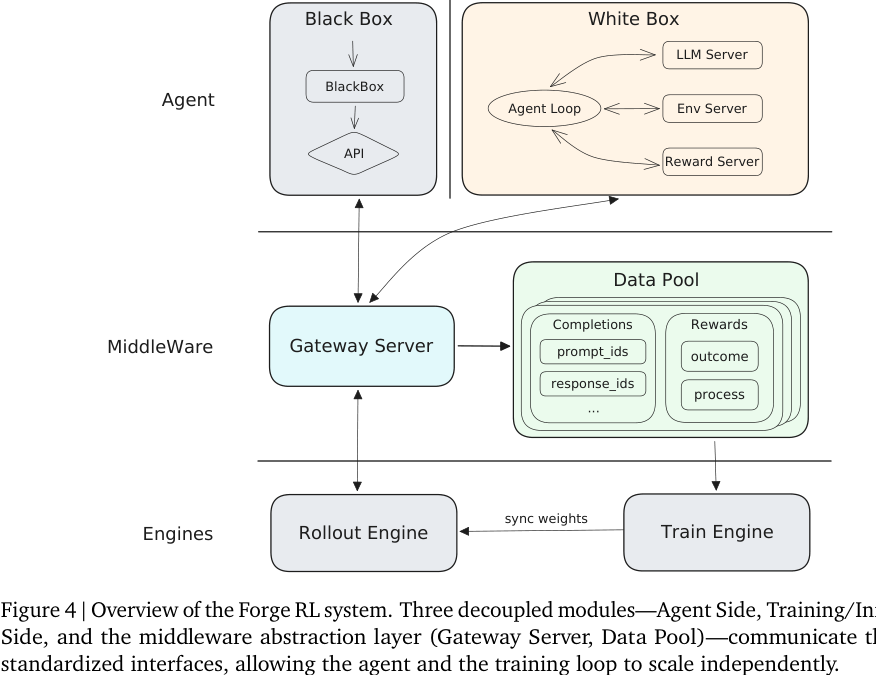
Forge 分为三层:
- Agent Side:任意 agent implementation,只负责产生轨迹;
- Middleware:Gateway Server + Data Pool;
- Training/Inference Side:Rollout Engine + Train Engine。
Gateway Server 负责把各种 agent scaffold 的 completion request 标准化,Data Pool 异步收集轨迹数据。Rollout Engine 负责高吞吐生成,Train Engine 从 Data Pool 消费数据、计算 CISPO 梯度,再把权重同步回 Rollout Engine。
这个设计的重点是:agent 端和训练端可以独立扩展。
#8.2 白盒与黑盒 agent 都要支持
报告区分两类 agent:
- White-box agents:把 context management 逻辑暴露给训练框架,训练系统能重建状态转换;
- Black-box agents:agent 内部逻辑完全不暴露,只通过 API 请求 LLM,系统只收集外部可见的 。
黑盒支持很关键,因为现实中的 agent scaffold 往往很复杂,可能有 deep thinking loops、aggressive context rewriting、hierarchical multi-agent coordination。如果 RL 系统要求它们全部改造成特定接口,生态就很难扩展。
Forge 的 Gateway 抽象让两类 agent 在同一训练循环中工作:白盒 agent 多注册一些 CM 操作,黑盒 agent 只提供请求流。
#8.3 Windowed FIFO:在吞吐和分布一致性之间折中
Agent rollout 时间差异极大:简单 API 调用可能几秒,复杂搜索/代码任务可能几小时。如果严格 FIFO,队首慢任务会阻塞训练;如果完全 greedy,短任务会先进入训练 batch,长任务后进入,造成训练分布偏移和不稳定。
Forge 提出 Windowed FIFO。
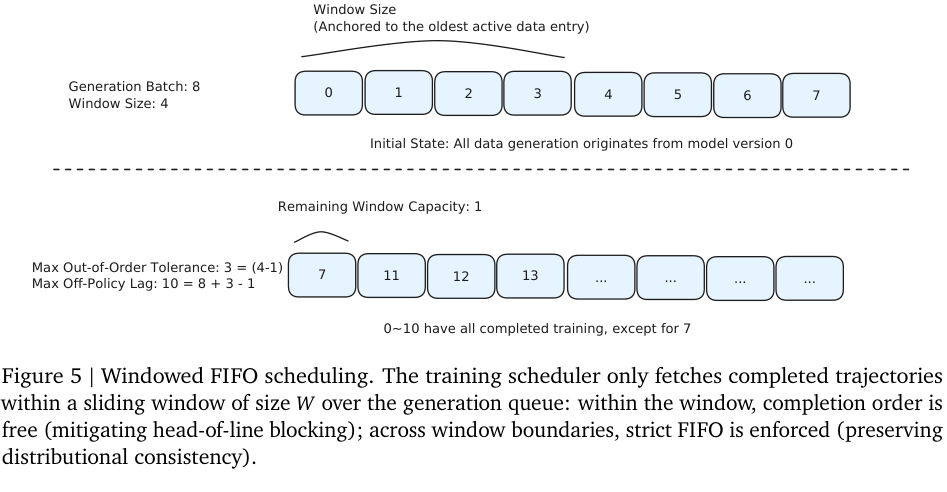
规则是:
- generation queue 有顺序;
- scheduler 只能在从当前 head 开始的窗口 内取已完成轨迹;
- 窗口内可以 greedy,谁先完成拿谁;
- 窗口外即使完成,也不能越过窗口边界;
- 窗口只有在 head-of-window 任务被消费后前进。
这样可以减少 head-of-line blocking,同时保持接近 FIFO 的分布属性。报告给出的经验是 可以维持近似 FIFO 的分布,同时显著减少集群空闲时间。
#8.4 Prefix Tree Merging:长上下文训练别重复算公共前缀
多轮 agent 轨迹里,很多训练样本共享同一个长上下文前缀。如果把每个 sample 独立训练,就会反复计算相同 prefix,浪费巨大。
Forge 使用 prefix tree merging:
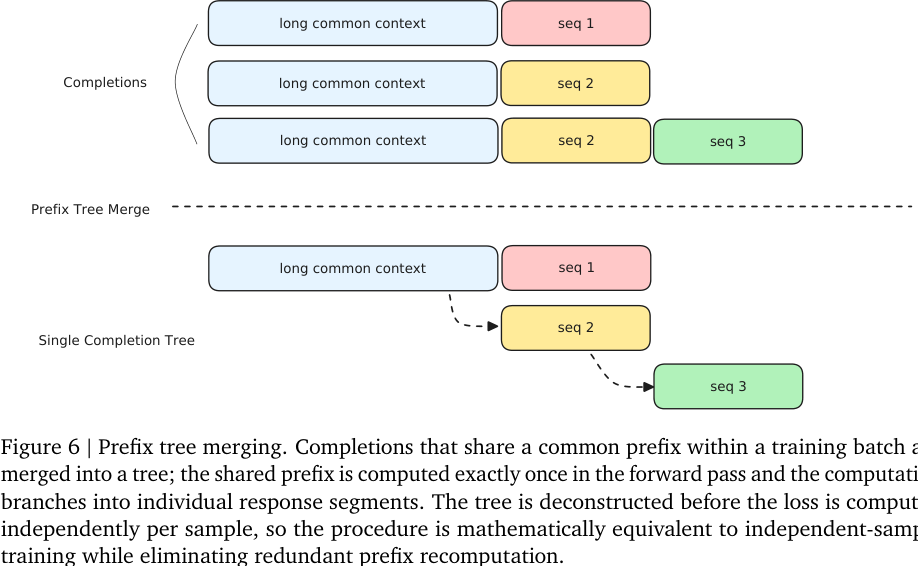
做法是:
- 把同一 batch 中共享公共前缀的 completions 合并成一棵树;
- shared prefix 在 forward 中只算一次;
- 到不同 response segment 处分支;
- forward 后再根据 metadata 拆开,独立计算每个 sample 的 loss。
报告强调这在数学上等价于独立样本训练,没有近似误差,因为 causal attention 下共享前缀的 activations 不依赖后续分支。它声称实践中可以达到 最高 40× training speedup,并降低显存占用,使更长序列和更大 batch 可行。
#8.5 Inference acceleration:MTP、prefill/decode disaggregation、全局 KV cache
Forge 为 agent RL rollout 做了三类推理优化:
- MTP-based speculative decoding:MTP modules 与 RL policy 持续共同训练,保持 draft acceptance rate;
- Heterogeneous prefill-decode disaggregation:prefill 和 decode 分离调度,避免 MoE 混合调度干扰;
- Global L3 KV Cache Pool:分布式全局 KV cache,通过 group-level rollout scheduling 提高 prefix cache hit rate,减少多轮 agent 交互中的重复 prefilling。
这背后的大逻辑是:agent RL 的成本瓶颈不只是训练 forward/backward,也包括海量 rollout generation。没有推理系统优化,RL scaling 很容易被 rollout 吞吐卡死。
#9. Agentic Mechanism:Interleaved Thinking
M2.7 报告中,interleaved thinking 是 agent 行为建模的核心机制。
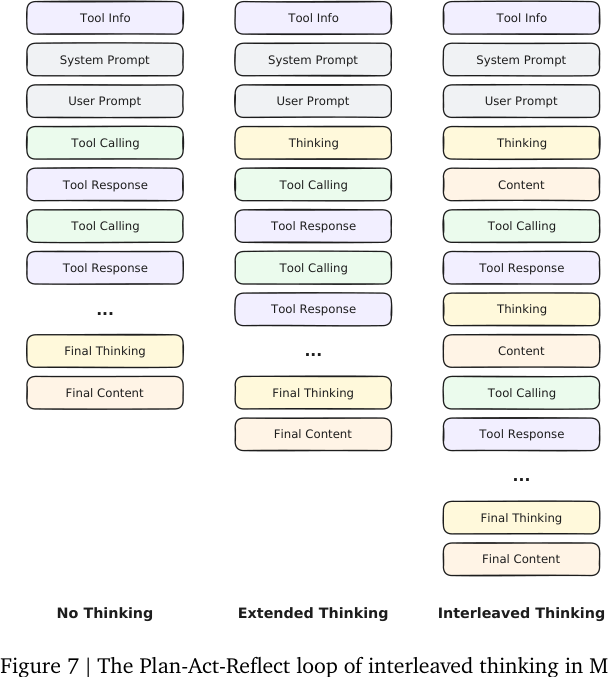
#9.1 三种模式的差别
可以把工具使用中的思考方式分成三类:
#No Thinking
模型基本直接调用工具,中间缺少显式规划和反思。
Tool call → observation → tool call → observation → final
优点是短,缺点是复杂任务容易乱撞。
#Extended Thinking
模型先写一大段 thinking,再开始调用工具。
long thinking → tool call → observation → tool call → final
这比 no thinking 好,但问题是:很多关键信息只有工具调用后才知道。前置思考无法根据中途观察实时修正。
#Interleaved Thinking
模型在每轮工具调用前后都保留和更新 reasoning state:
thinking → action → observation → thinking → action → observation → ... → final
报告形式化为:
每个 reasoning segment 都条件于之前的 reasoning、action、observation,因此模型能更新假设、修计划、解释异常。
#9.2 Reasoning state persistence 是关键
M2 的一个重要选择是:把每一轮模型输出中的 thinking blocks 也追加到历史中,作为下一轮上下文。
如果把历史 thinking blocks 丢掉,模型每轮都要重新推导上下文、约束和中间结论,容易 state drift。报告称他们做了 ablation,保留 reasoning state 在 deep search 和 software engineering 等长程任务上收益尤其明显。
这和 wenjun 最近关心的 agent 长轨迹 RL 很相关:长轨迹的问题不只是“能不能执行很多步”,而是模型能不能在很多步之间保持可更新的内部工作状态。Interleaved thinking 是一种显式文本形态的工作状态持久化。
#10. Self-Evolution:模型参与改进自己的训练和 scaffold
报告最有未来感的一节是 self-evolution。
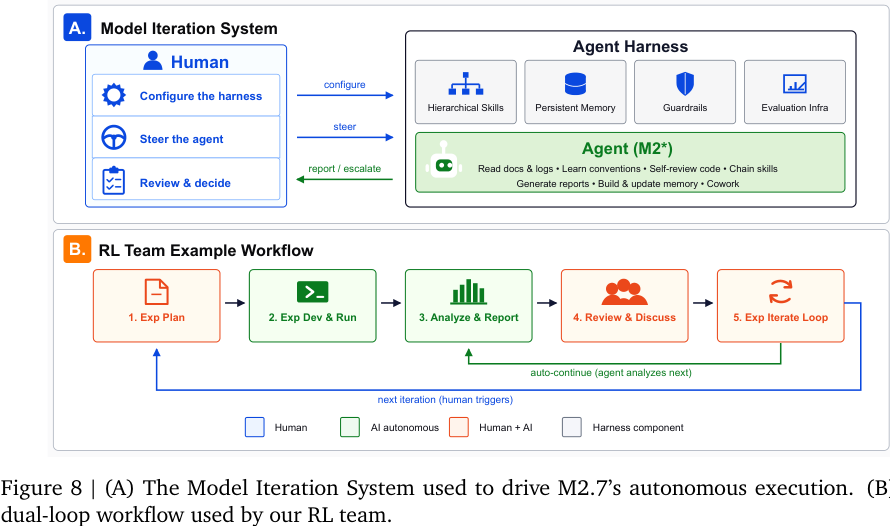
MiniMax 把 M2.7 的 self-evolution 描述为“early operational form”,不是说模型已经完全自主改进自身权重,而是说它已经能在模型迭代系统里承担一部分真实研发工作:
- 读取 docs 和 logs;
- 学习项目 conventions;
- self-review code;
- chain skills;
- 生成报告;
- 构建和更新 memory;
- 调试训练运行;
- 修改配置和 agent scaffold。
#10.1 Humans steer, models build
Figure 8A 里的 Model Iteration System 很像一个工程化 agent harness:
- 人类负责 configure harness、steer agent、review & decide;
- agent harness 提供 hierarchical skills、persistent memory、guardrails、evaluation infra;
- M2* agent 负责读日志、学规范、自审代码、串联技能、生成报告、协作。
这是一种很现实的 self-evolution 路线:不是一上来让模型完全闭环训练自己,而是先让模型嵌入研发流程,承担可验证、可回滚、可审查的迭代任务。
#10.2 RL team dual-loop workflow
Figure 8B 展示 RL 团队的双循环:
- Exp Plan:人类 + AI;
- Exp Dev & Run:AI autonomous;
- Analyze & Report:AI autonomous;
- Review & Discuss:人类 + AI;
- Exp Iterate Loop:人类 + AI。
报告称,M2.7 在实践中可以承担 RL 团队 30% 到 50% 的每日迭代工作量。它还能针对内部 programming scaffold 做 100 轮自主迭代,分析失败、修改代码、评估变化,引入 loop detection 等机制,并在内部评估上带来约 30% 性能提升。
这里最值得深挖的是:
self-evolution 的起点不是“模型直接改权重”,而是“模型改产生数据、运行实验、构造 scaffold、评估行为的外部系统”。
对于 code agent / research agent,这可能是更实际的自演化路径。因为权重更新需要昂贵训练,但 scaffold、数据、环境、评测、prompt、tool policy 的迭代可以更快闭环。
#11. 实验结果:M2 → M2.5 → M2.7 的系列内演进
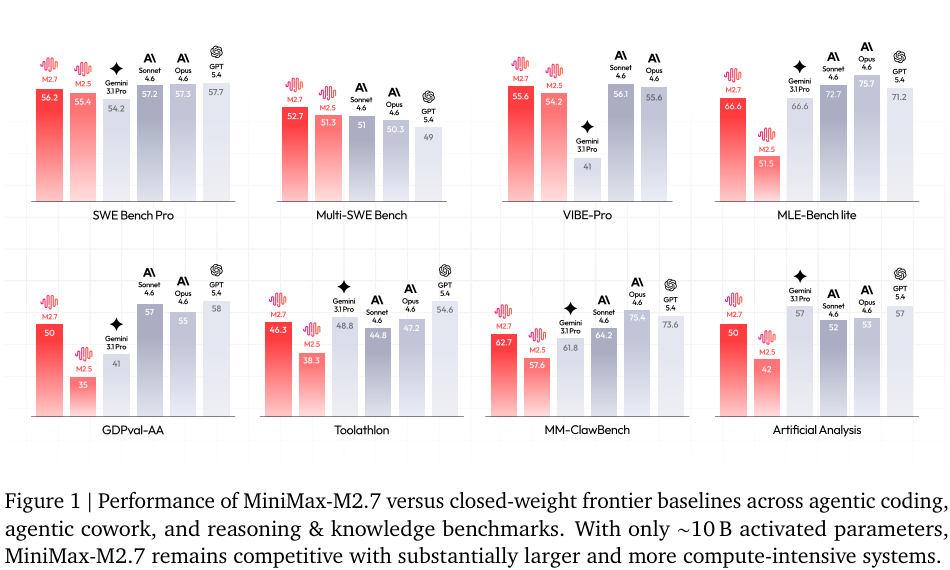
M2.7 与 M2.5 以及闭源前沿模型比较。报告特别强调:M2.7 只有约 10B activated parameters,却在多个 agentic benchmark 上接近甚至达到闭源 frontier 级别。
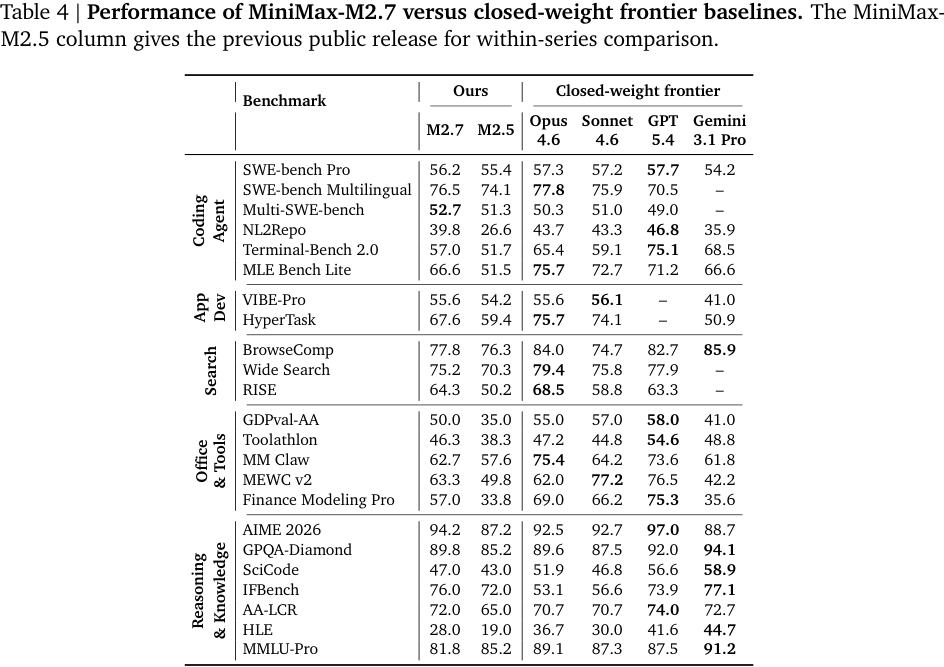
#11.1 Coding Agent
M2.7 的代表性结果:
| Benchmark | M2.7 | M2.5 | 备注 |
|---|---|---|---|
| SWE-bench Pro | 56.2 | 55.4 | 接近 Opus/Sonnet/GPT 5.4 |
| SWE-bench Multilingual | 76.5 | 74.1 | 接近最高闭源模型 |
| Multi-SWE-bench | 52.7 | 51.3 | 在表中超过列出的闭源模型 |
| NL2Repo | 39.8 | 26.6 | 大幅提升,体现 full-stack repo 数据收益 |
| Terminal-Bench 2.0 | 57.0 | 51.7 | 相比 M2.5 提升明显 |
| MLE Bench Lite | 66.6 | 51.5 | +15.1,self-evolution case study 重点 |
这里最值得看的是 NL2Repo、Terminal-Bench、MLE Bench Lite,因为它们更像真实 agent 工程任务,而不是单纯补丁生成。
#11.2 AppDev / Search / Office & Tools
AppDev:
- VIBE-Pro:55.6,接近领先闭源模型;
- HyperTask:67.6,比 M2.5 的 59.4 提升 8.2。
Search:
- BrowseComp:77.8;
- Wide Search:75.2;
- RISE:64.3,比 M2.5 的 50.2 大幅提升。
Office & Tools:
- GDPval-AA:50.0,比 M2.5 的 35.0 提升 15;
- Toolathlon:46.3,比 M2.5 的 38.3 提升 8;
- MEWC v2:63.3,比 M2.5 的 49.8 提升 13.5;
- Finance Modeling Pro:57.0,比 M2.5 的 33.8 提升 23.2。
Office/Tools 这块提升很大,说明 M2.7 的 agentic cowork 数据和工具 reward 可能起了明显作用。
#11.3 Reasoning & Knowledge
M2.7 在 reasoning/knowledge 上也很强:
- AIME 2026:94.2;
- GPQA-Diamond:89.8;
- IFBench:76.0;
- AA-LCR:72.0;
- HLE:28.0。
但这部分并不总是领先闭源模型。例如 GPT 5.4 / Gemini 3.1 Pro 在若干知识/推理指标上仍更高。报告的核心卖点不是“所有 benchmark 第一”,而是“以约 10B 激活参数在真实 agent 任务上接近 frontier”。
#11.4 系列内演进:M2 → M2.5 → M2.7
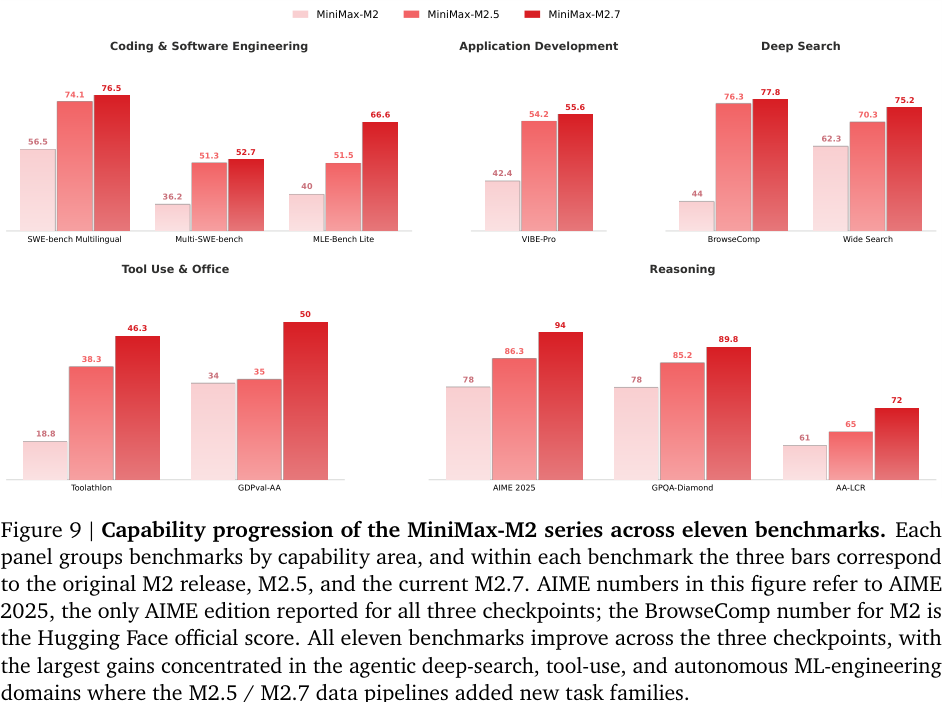
Figure 9 展示从 M2 到 M2.5 再到 M2.7 的进步。最明显的提升集中在:
- BrowseComp:44 → 76.3 → 77.8;
- Toolathlon:18.8 → 38.3 → 46.3;
- MLE-Bench Lite:40 → 51.5 → 66.6;
- GDPval-AA:34 → 35 → 50;
- SWE-bench Multilingual:56.5 → 74.1 → 76.5。
这说明 M2 系列能力提升主要来自后训练数据、RL 系统、agent scaffold 和 self-evolution 的共同演进,而不只是 base architecture。
#12. MLE Bench Lite case study:自演化最直接的证据
报告把 MLE Bench Lite 作为 self-evolution 的核心 case study。
设置是:让 M2.7 作为独立 ML engineer,在 MLE Bench Lite 的 22 个竞赛任务上执行标准 ML workflow。它使用一个由短期记忆和自我反馈驱动的 autonomous harness;每轮迭代后写 memory file,并进行自我批评,形成下一轮优化方向。
实验做了 3 次独立 trial,每次允许 24 小时迭代演化。
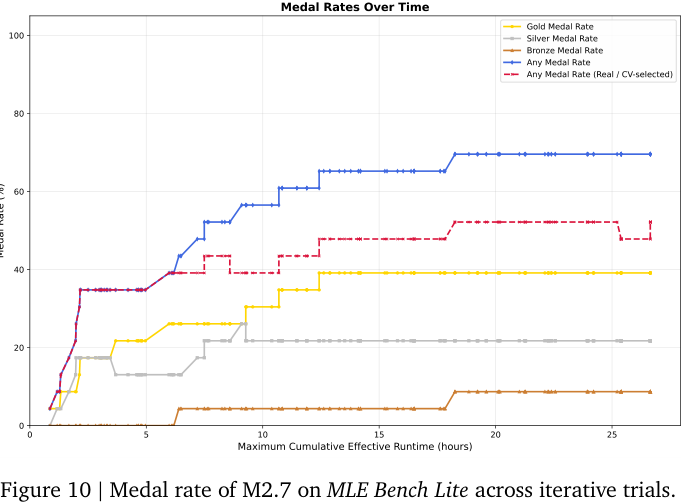
报告中的关键结果:
- 最佳运行:9 枚金牌、5 枚银牌、1 枚铜牌;
- 平均 medal rate:66.6%;
- 与 Gemini 3.1 Pro 持平;
- 能自动调试训练 scaffold、修改配置文件,并进行数百轮迭代。
从研究角度看,这个 case 的意义不只在 medal rate,而在它验证了一种能力组合:
- 读懂 ML 任务和评价指标;
- 写/改训练代码;
- 跑实验并处理报错;
- 从结果中总结下一步;
- 把经验写入短期 memory;
- 在多轮中持续改进。
这非常接近“self-evolving code agent”或“research agent”的最小闭环。
#13. 我怎么看这篇报告的技术路线?
#13.1 它的核心贡献是系统路线,而不是单个技巧
如果只拆单点,M2.7 的很多技术都不是第一次出现:
- MoE;
- MTP/speculative decoding;
- full attention vs SWA;
- agent SFT;
- RL with process reward;
- prefix cache;
- agent memory;
- self-improvement loops。
但这篇报告的价值在于把它们组织成一个统一路线:
低激活 MoE backbone
→ 长上下文 full attention
→ 可执行 agent 数据
→ interleaved thinking SFT
→ agent-native RL 系统 Forge
→ 推理/训练吞吐优化
→ 模型参与 scaffold / 实验迭代
→ 更强的 agentic benchmark 表现
它不是“一个模型”,更像是一套 agentic model factory。
#13.2 真正稀缺的是环境、验证和系统,不只是模型参数
M2.7 的报告反复说明 reward credibility 的重要性。对于 agent RL 来说,真正难的是:
- 怎么构造大规模、真实、多样的任务;
- 怎么自动搭建可运行环境;
- 怎么确保 reward 不被 hack;
- 怎么让 judge 评分可信;
- 怎么让训练系统支持任意 scaffold;
- 怎么处理 rollout 时长极不均匀;
- 怎么在长上下文里不重复浪费计算。
这些是模型公司真正的基础设施壁垒。参数规模可以被追赶,但高质量 agent data + execution environment + RL infra 的积累更难复制。
#13.3 Full attention 的选择很保守,但很现实
M2.7 明确放弃 hybrid SWA,选择 full attention。这在 192K context 下成本很高,但从 agent 质量角度是稳健选择。
这说明在 frontier agent 模型里,架构创新不一定优先于可靠性。只要稀疏 attention/linear attention 在真实长程 agent 上有不可预测的质量损失,模型厂商就会宁愿付更高计算成本,用 full attention 保证能力。
对研究来说,这也指出了一个很有价值的问题:
怎样设计真正能保住 agent 长程推理、retrieval、in-context learning、tool-state tracking 的高效 attention?
标准短 benchmark 证明不了这一点。
#13.4 Interleaved thinking 是当前 agent 的“外显工作记忆”
M2.7 保留每轮 thinking blocks,让后续回合继续看到之前推理。这本质上是把工作记忆外显成文本上下文。
它有效,但也有代价:
- 上下文变长;
- thinking token 成本高;
- reasoning trace 可能泄露或污染;
- 长轨迹里错误推理也会被保留;
- 模型可能过度依赖 verbal reasoning。
这和 latent reasoning / working memory 方向形成对照:未来是否可以把 interleaved thinking 的一部分从自然语言转成 latent state 或压缩 memory?M2.7 没有解决这个问题,但它提供了强 baseline:至少在当前工程上,保留显式 reasoning state 对 agent 很有用。
#13.5 Self-evolution 还处在 scaffold-level,而不是 weight-level
报告中的 self-evolution 很令人兴奋,但要准确理解:
- 它不是模型完全自主训练下一代权重;
- 它更多是在实验、代码、配置、scaffold、评测和 memory 层面做自动迭代;
- 人类仍然 steer、review、decide;
- reward、环境、guardrails、evaluation infra 仍由人类/系统设计。
但这并不削弱它的重要性。相反,这可能是更现实的路径:让模型先成为模型研发流程里的高效工程师,再逐步扩大闭环范围。
#14. 和 LLM Agent / model-based RL / latent reasoning 的关系
#14.1 对 LLM Agent:agent 能力来自“模型 + 环境 + 训练系统”共同设计
M2.7 强调的不是单一 prompt scaffold,而是:
- base model 架构支持长上下文和低成本激活;
- SFT 教会 interleaved thinking;
- RL 优化真实长轨迹;
- Forge 支持黑盒/白盒 agent;
- 数据环境提供可验证反馈;
- 推理系统支持长轨迹吞吐。
这说明 agent 不是一个 wrapper,而是一种训练范式。
#14.2 对 model-based RL for LLM Agent:目前更像 environment-driven RL,不是 world-model RL
M2.7 的 RL 把工具、context management、memory、agent loop 都当 environment dynamics。这是很清晰的 agent RL 抽象。
但它还不是 wenjun 关心的那种 model-based RL / Dreamer for LLM Agent:
- 没有显式学习一个可 rollout 的 world model;
- 没有在 latent imagination 中模拟长程工具结果;
- 主要还是通过真实环境 rollout + reward 优化 policy。
不过,它给 model-based 方向提供了一个强现实基线:如果未来要做 LLM agent 的 world model,必须面对 M2.7 已经暴露的这些系统问题:长上下文、异步轨迹、工具状态、reward credibility、scaffold heterogeneity、训练吞吐。
#14.3 对 latent reasoning:M2.7 仍然走显式 reasoning trace 路线
M2.7 的 interleaved thinking 是显式文本 reasoning,不是 latent-space reasoning。它通过保留 thinking blocks 来维持 state persistence。
这和 RiM / Coconut 等 latent reasoning 工作形成有趣对比:
- M2.7:用自然语言 thinking 作为可审计、可训练、可持久化的外显工作记忆;
- latent reasoning:希望把部分推理移到 hidden states / memory blocks / continuous thoughts 中,降低延迟和语言负担。
未来一个很自然的问题是:能不能把二者结合?例如:
- agent 关键决策点保留可读 thinking;
- 高频局部计算用 latent memory;
- 长轨迹历史用 learned compression;
- world-model imagination 在 latent space 中进行;
- 最终只把必要的 reasoning trace 外显给人类和 verifier。
M2.7 的报告没有走这条路,但它把“agent 长轨迹推理需要持久状态”这个需求讲得非常清楚。
#15. 局限与需要谨慎的地方
#15.1 很多关键细节仍是高层描述
报告覆盖面很广,但很多细节没有完全展开,例如:
- 数据规模、过滤阈值、各 domain mixing ratio;
- reward 模型训练和可信度评估;
- CISPO 与其他 RL 方法的系统性对比;
- Windowed FIFO / prefix tree merging 的实际集群指标;
- MTP speculative decoding 的 acceptance rate 和速度收益;
- self-evolution 中失败案例和安全边界。
作为技术报告,它展示路线和结果,但很多复现细节仍不充分。
#15.2 Benchmark scaffold 公平性仍需外部验证
Table 4 中很多 benchmark 是在作者 scaffold 下评测的,报告也说明各模型共享 scaffold 和工具环境。但 agent benchmark 对 scaffold、工具、prompt、采样参数非常敏感。闭源模型的真实最佳表现可能依赖各自最佳 agent harness。
所以这些结果适合看趋势和能力区间,不宜过度解读为绝对排名。
#15.3 Reward hacking 和 judge bias 仍是长期风险
报告大量使用 rubric-based judge、Agent-as-a-Verifier、teacher model distillation。它们能扩展数据规模,但也带来:
- judge 偏差;
- reward hacking;
- teacher model 风格同质化;
- 任务合成分布偏移;
- evidence checking 不彻底。
M2.7 强调 reward credibility,但如何系统证明 reward 不被利用,仍是 agent RL 未来的核心问题。
#15.4 Self-evolution 需要人类决策闭环
M2.7 能承担 30%-50% 日常迭代工作量很强,但目前仍是 human-steered / human-reviewed。真正高风险的模型训练方向、数据策略、发布决策,仍需要人类把关。
这意味着 self-evolution 的短期形态更像“模型研发自动化”,而不是完全 autonomous AGI research loop。
#16. 总结:M2.7 的启发是什么?
MiniMax-M2.7 的技术报告传达了一个非常清晰的判断:
下一阶段模型能力竞争,不只是 base model 参数和 benchmark,而是围绕 agent 任务的完整生产系统竞争。
它的关键启发可以概括为六点:
- 小激活 MoE 是长轨迹 agent 的成本底座:10B activated 级别如果能接近 frontier,agent 推理成本会更可控。
- 长上下文质量比上下文长度数字更重要:M2 选择 full attention,说明复杂 agent 对 attention coverage 很敏感。
- 可执行环境 + 高可信 reward 是 agent RL 的核心资产:SWE、AppDev、Terminal、Search、Office 都围绕验证构造。
- 训练系统必须 agent-native:Forge 支持黑盒/白盒 agent、异步 rollout、Windowed FIFO、prefix tree merging,这是 agent RL scale 的前提。
- interleaved thinking 是当前可行的 agent 工作记忆机制:保留 reasoning state 可以显著改善长程任务。
- self-evolution 会先发生在 scaffold / data / eval / experiment loop 层面:模型先成为研发流程里的自动工程师,再逐步接近更强闭环。
对 wenjun 当前关心的研究方向来说,M2.7 最值得继续追问的不是“怎么复刻这个模型”,而是:
- 如果 agent RL 的瓶颈是长轨迹真实环境 rollout,能不能用 learned world model 做更便宜的 imagined rollout?
- 如果 interleaved thinking 的成本太高,能不能训练 latent working memory 来承载部分 reasoning state?
- 如果 self-evolution 主要发生在 scaffold 层,怎样设计可验证、可积累、可迁移的 agent memory 和 skill system?
- 如果 reward credibility 是核心,怎样让 verifier 从 task-specific scripts 走向可泛化的环境理解和结果审计?
MiniMax-M2.7 给出的答案是工程化、系统化的:先把真实 agent 任务跑起来,给它们环境、奖励、训练系统和自我迭代流程。未来更基础的范式突破,很可能就发生在这些系统瓶颈之上。