#MiMo-7B 训练过程详解:一个 7B 推理模型是怎样从预训练到 RL 被“养出来”的
论文/技术报告:MiMo-7B Technical Report / Unlocking the Reasoning Potential of Language Model From Pretraining to Posttraining
机构:Xiaomi MiMo
arXiv:<https://arxiv.org/abs/2505.07608>
GitHub:<https://github.com/XiaomiMiMo/MiMo>
模型:MiMo-7B-Base、MiMo-7B-SFT、MiMo-7B-RL-Zero、MiMo-7B-RL、MiMo-7B-RL-0530
一句话概括:MiMo-7B 的核心不是“7B 也能靠 RL 突然变强”这么简单,而是先从预训练阶段刻意提高 reasoning pattern 的密度,把 base model 训练成一个更适合被 RL 打开的“高潜力策略”,再用可验证数学/代码题、改造版 GRPO、难度驱动代码奖励和高效 rollout 系统,把这种潜力释放出来。
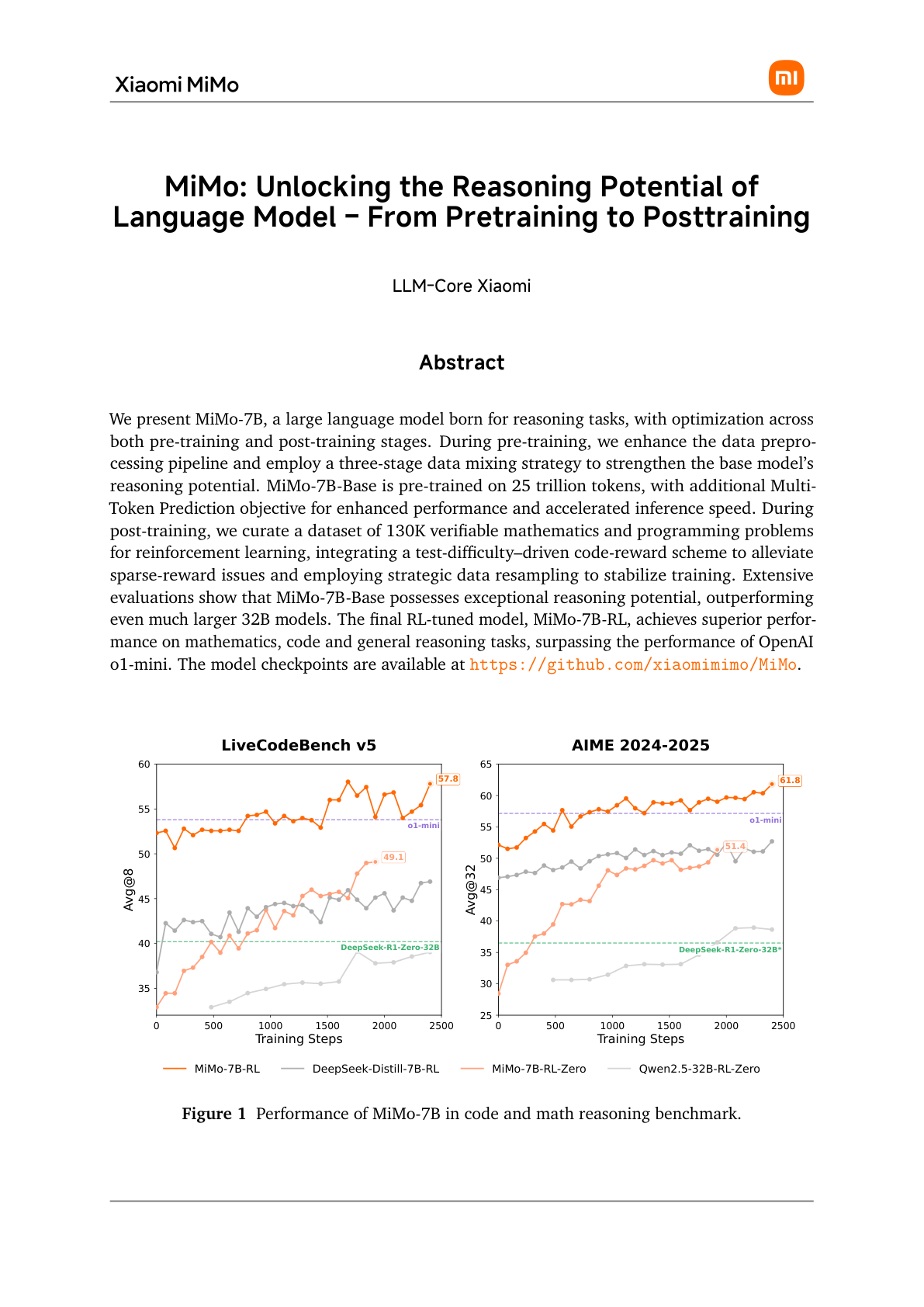
#1. 为什么 MiMo-7B 值得看?
MiMo-7B 这篇报告真正有意思的地方在于,它把一个问题摆到了台面上:
推理模型的能力到底主要来自后训练 RL,还是来自 base model 在预训练阶段已经具备的“推理潜力”?
DeepSeek-R1 之后,大家很容易形成一种直觉:只要有足够多可验证题目、足够大 rollout、足够强 RL,模型就会长出 reasoning。但 MiMo-7B 的叙事更进一步:RL 不是凭空制造能力,而是在 base model 的策略空间里搜索、放大和稳定已有能力。如果 base model 在预训练时没有足够多高质量推理模式,那么后面的 RL 再努力,也更像是在贫瘠土地上施肥。
所以 MiMo-7B 的训练流程可以看成一条完整链路:
推理导向数据清洗/合成
↓
三阶段预训练:25T tokens + 长上下文 + MTP
↓
MiMo-7B-Base:高 pass@k、强探索潜力的 base policy
↓
SFT 冷启动:格式、对话、推理轨迹先验
↓
数学/代码可验证 RL:130K problems + 改造 GRPO
↓
系统工程:continuous rollout + async reward + early termination
↓
MiMo-7B-RL / MiMo-7B-RL-0530
这条链路里,每一环都在服务同一个目标:让一个 7B dense 模型尽可能适合长链条、可验证、可探索的推理任务。
#2. 总览:MiMo-7B 一共训练出了哪些版本?
报告里主要涉及五个模型状态:
| 模型 | 从哪里来 | 主要用途 | 关键含义 |
|---|---|---|---|
| MiMo-7B-Base | 从零预训练 | base model | 验证“预训练推理潜力” |
| MiMo-7B-SFT | Base 经过 SFT | RL 冷启动模型 | 提供格式、对话和推理行为先验 |
| MiMo-7B-RL-Zero | Base 直接 RL | 类似 R1-Zero 路线 | 测试不经过 SFT 时 base 的 RL 潜力 |
| MiMo-7B-RL | SFT 后 RL | 主力发布模型 | 最终数学/代码/通用能力更高 |
| MiMo-7B-RL-0530 | 更大 SFT 数据 + 更长 RL window | 后续增强版 | SFT 从 500K 扩到 6M,RL 长度从 32K 扩到 48K |
最关键的对比是 RL-Zero vs RL:
- RL-Zero 说明 MiMo-7B-Base 本身确实有很强的 RL 可塑性;
- SFT + RL 最终上限更高、更稳定,尤其数学和代码能同时涨;
- 轻量 SFT 只做格式对齐并不够,报告观察到它会起步更高,但很快被 base 直接 RL 的增长曲线反超。
这对理解 reasoning model 很重要:SFT 不是越少越“纯”,也不是越多越安全;真正关键是 SFT 是否提供了高质量推理先验,同时又不压死后续 RL 的探索空间。
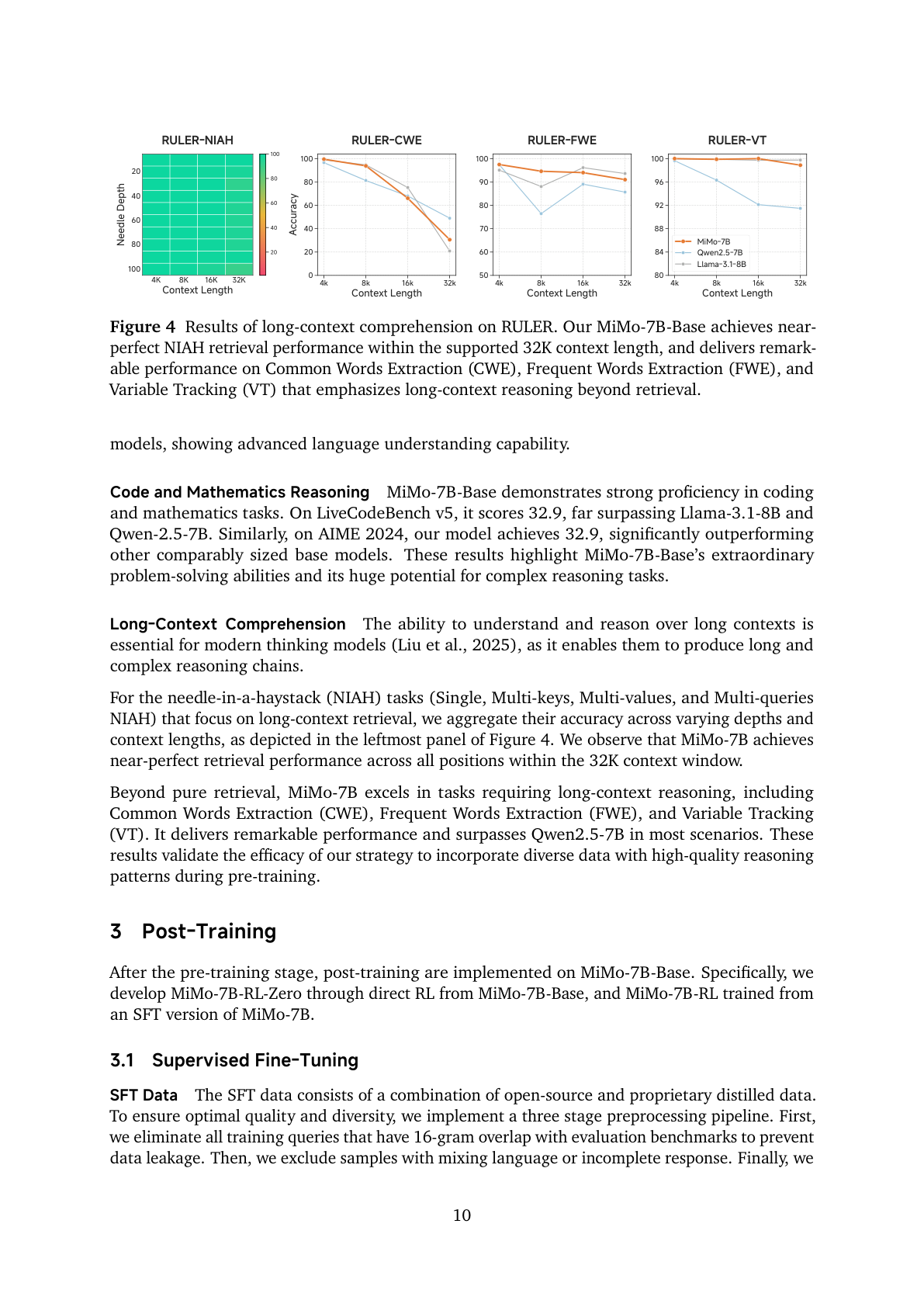
#3. 第一阶段:预训练不是泛泛堆 token,而是提高 reasoning pattern 密度
MiMo-7B-Base 从零训练,总 token 数约 25T tokens。但报告最强调的不是 25T 这个数字,而是预训练数据的结构。
#3.1 数据来源:网页、论文、书、代码、合成推理数据
MiMo-7B 的预训练语料包含:
- web pages;
- academic papers;
- books;
- programming code;
- synthetic data。
这听起来和一般 LLM 差不多,但 MiMo 的重点是:这些数据要尽量保留数学公式、代码块、论坛讨论、教程里的推理过程。
报告指出,常见网页抽取器经常会破坏数学公式和代码片段。例如:
- LaTeX 公式被丢失或乱码;
- code block 被压平成普通文本;
- forum QA 的结构被破坏;
- PDF 中 STEM/代码内容解析失败。
如果这些内容被破坏,模型看到的就不是完整推理,而是碎片化噪音。于是 MiMo 做了两类增强:
- 优化 HTML extraction:更好保留数学、代码、论坛结构;
- 增强 PDF parsing:更好处理论文和书中的 STEM / code content。
这一步可以理解为:
与其训练时再指望模型自己从残缺文本里悟出推理,不如先把网页和 PDF 中原本存在的推理结构尽量完整地抽出来。
#3.2 全局去重:URL dedup + MinHash dedup
MiMo 做了网页 dump 的 URL 去重和 MinHash 去重,并且强调通过工程优化,可以在一天内完成全局去重。
去重的意义不只是避免 benchmark contamination 或过拟合,它还影响训练效率:
- 重复广告、模板、低质量页面会浪费 token;
- 重复题解/答案可能让模型记忆而非推理;
- 重复分布会扭曲数据 mixture 的真实权重。
但报告也指出一个问题:去重算法通常不理解内容质量。MinHash 只看相似,不知道某段文本是不是高价值数学推理。因此去重之后,还要用多维质量分数重新调数据分布。
#3.3 多维过滤:不用简单 heuristic,而是训练小模型做质量 tagger
很多通用预训练数据过滤规则会误伤推理数据。比如:
- 数学页面符号密度高,被误判为乱码;
- 代码页面有大量括号、缩进、特殊字符,被误判为低质量;
- 竞赛题解或论坛讨论格式复杂,被普通规则过滤。
MiMo 的做法是 fine-tune small LLMs 作为 data quality taggers,做:
- domain classification;
- multi-dimensional quality assessment;
- reasoning depth / knowledge density 相关筛选。
这背后的直觉是:推理数据往往长得不像“干净自然语言”。如果用普通网页清洗规则,会把最有价值的数学和代码内容过滤掉。
#3.4 合成推理数据:不是只做 instruction data,而是放进预训练
MiMo 使用 advanced reasoning models 生成大量 synthetic reasoning data,主要包括三类:
- 选择高 reasoning depth 的 STEM 内容,让模型基于源材料生成深入分析;
- 收集数学和代码问题,让 reasoning model 求解;
- 加入 general domain queries,尤其 creative writing 等任务。
这里有一个很有意思的观察:报告称他们的 preliminary experiments 发现,synthetic reasoning data 与普通非推理数据不同,可以训练非常多 epoch 而不容易过拟合。
这可能意味着:
- 推理轨迹本身提供了更丰富的 token-level supervision;
- 同一类问题的解题过程有多样性,不是简单重复标签;
- 高质量 synthetic reasoning 可以作为一种“推理模式蒸馏”的预训练信号。
但也要谨慎:报告没有完全展开这个结论的边界条件。它更像一个经验观察,值得后续研究验证。
#4. 三阶段预训练 mixture:从通用语料到数学/代码,再到长上下文合成推理
MiMo-7B 的预训练不是一个固定 mixture 从头训到尾,而是三阶段。
#4.1 Stage 1:广覆盖,但降权低知识密度内容
Stage 1 使用所有数据源,但不包括 synthetic responses for reasoning task queries。
它做两件事:
- downsample 过度代表的低价值内容:广告、新闻、招聘、知识密度/推理深度不足的材料;
- upsample 高质量专业领域数据。
这一步的目标是建立通用语言、知识和基础推理能力,但避免大量低价值网页把训练预算吃掉。
#4.2 Stage 2:数学和代码提高到约 70%
Stage 2 在 Stage 1 的 curated distribution 基础上,大幅增加数学和代码相关数据到约 70%。
这其实是 MiMo 最重要的预训练策略之一。它隐含的判断是:
如果目标是 reasoning model,那么不能只在后训练阶段才看到数学/代码。base model 必须在预训练中长期暴露于高密度形式推理、算法结构、符号操作和程序逻辑。
Stage 1 和 Stage 2 的上下文长度都是 8,192 tokens。
#4.3 Stage 3:加入约 10% synthetic responses,并把 context 扩到 32K
Stage 3 有两个变化:
- 加入约 10% 数学、代码、创意写作 query 的 synthetic responses;
- context length 从 8,192 扩到 32,768。
这一步既像能力增强,也像“长推理适应”:
- synthetic responses 让模型看到完整解题过程;
- 32K context 让模型适应长问题、长推理、长输出;
- 这为后面 RL 中最大 32K generation length 做铺垫。
从训练 curriculum 看,MiMo 的策略是:
先学广泛知识和语言结构
→ 再强化数学/代码形式推理
→ 最后适应长上下文和完整 reasoning response
这比“最后做一点数学 SFT”更底层,因为它改变的是 base model 的参数空间和探索边界。
#5. 模型架构:标准 dense Transformer + MTP,为长推理解码提速
MiMo-7B 是 decoder-only Transformer,采用相对标准的组件:
- GQA;
- pre-RMSNorm;
- SwiGLU;
- RoPE。
关键超参包括:
| 项目 | 设置 |
|---|---|
| Transformer layers | 36 |
| hidden dimension | 4096 |
| FFN intermediate dimension | 11008 |
| attention heads | 32 |
| KV groups | 8 |
#5.1 为什么要 MTP?
Reasoning model 的一个现实问题是:输出太长。
如果模型在数学/代码题上动辄生成几千到几万 token,那么自回归逐 token 解码的延迟会很高。MiMo 引入 Multi-Token Prediction, MTP,灵感来自 DeepSeek-V3 和 multi-token prediction 相关工作。
MTP 的直觉是:
不只预测下一个 token,还让模型学习预测后面多个 token。这样模型内部表示会更有“预规划”能力,推理时也可以配合 speculative decoding 加速。

#5.2 预训练时一个 MTP layer,推理时多个 MTP layers
MiMo 的设计有点特别:
- 预训练阶段只用 single MTP layer,因为 preliminary studies 发现多个 MTP layer 没有进一步提升;
- 预训练后,把 single MTP layer 复制成两个相同副本;
- 冻结 main model 和 first MTP layer,再 fine-tune 两个新的 MTP layers,用于 inference speedup。
报告称,在 AIME24 上:
- 第一层 MTP acceptance rate 约 90%;
- 第三层仍超过 75%。
这说明在长 reasoning path 里,连续 token 的可预测性很高。MTP 对这类模型尤其有价值,因为 reasoning 输出中常有局部模式:公式展开、自然语言解释、代码片段、步骤编号等。
#5.3 预训练超参
优化器和训练设置:
| 项目 | 设置 |
|---|---|
| optimizer | AdamW |
| beta1 / beta2 | 0.9 / 0.95 |
| weight decay | 0.1 |
| gradient clipping | max norm 1.0 |
| Stage 1/2 max seq len | 8192 |
| Stage 3 max seq len | 32768 |
| Stage 1/2 RoPE base | 10000 |
| Stage 3 RoPE base | 640000 |
学习率 schedule:
- Stage 1:前 84B tokens 从 0 warmup 到 1.07e-4;
- 之后 10.2T tokens 保持 1.07e-4;
- 再用 7.5T tokens cosine decay 到 3e-5;
- Stage 2 的 4T tokens 和 Stage 3 前 1.5T tokens 保持 3e-5;
- 最后 500B tokens cosine decay 到 1e-5。
batch size:
- 前 168B tokens 线性 warmup 到 batch size 2560;
- Stage 1/2 保持 2560;
- Stage 3 固定为 640。
MTP loss weight:
- 前 10.3T tokens 为 0.3;
- 之后降为 0.1。
这个 schedule 的设计可以理解为:早期用大 batch 和较高 LR 学广泛分布;中后期逐步降 LR,最后长上下文阶段用更小 batch 适配长序列。
#6. 如何证明 base model 有“推理潜力”?看 pass@k,而不是只看 pass@1
MiMo 报告很强调一个观点:传统 pass@1 或平均采样分数会低估 base model 的推理潜力。
如果一个 base model 对某题单次采样只有 20% 成功率,但采样 32 次总能出现正确解,那它对 RL 来说就很有价值。因为 RL 需要的是:
- 策略空间里存在好轨迹;
- reward 能把好轨迹筛出来;
- update 能提高好轨迹概率。
因此报告采用 pass@k 来估计能力上界。结果显示,MiMo-7B-Base 在多个 reasoning benchmark 上的 pass@k 曲线高于同规模甚至更大 baseline,且 k 越大差距越明显,尤其 LiveCodeBench。
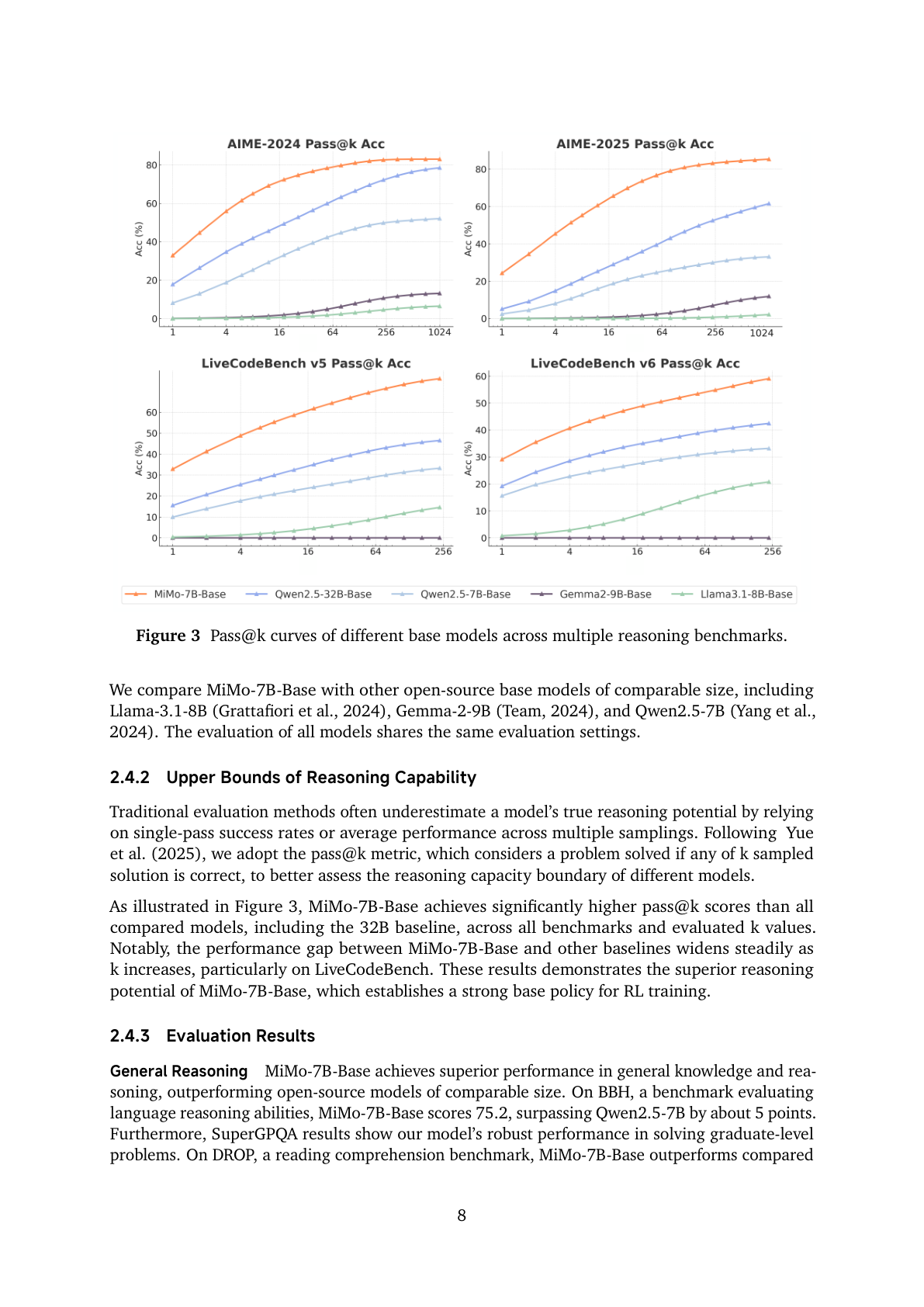
这对 RL 很关键。用人话说:
pass@1 看的是模型现在“第一反应”有多准;pass@k 看的是模型脑子里有没有可能搜到正确路径。RL 更需要后者。
这也是 MiMo-7B-Base 能直接做 RL-Zero 的原因之一。
#7. SFT:不是最终答案,而是 RL 的冷启动
预训练之后,MiMo 做 supervised fine-tuning。
#7.1 SFT 数据:开源 + 私有蒸馏数据,最终约 500K 样本
SFT 数据由 open-source 和 proprietary distilled data 组成。清洗流程三步:
- 去除与 evaluation benchmarks 有 16-gram overlap 的 training queries,防止数据泄漏;
- 去掉 mixing language 或 incomplete response 的样本;
- 每个 query 最多保留 8 个 responses,在多样性和冗余之间折中。
最终 SFT 数据约 500K samples。
SFT 超参:
| 项目 | 设置 |
|---|---|
| learning rate | 3e-5 constant |
| batch size | 128 |
| max length | 32768 tokens |
| packing | samples packed to max length |
#7.2 SFT 的作用:格式、对话、推理行为先验
报告里的实验很有意思:从 Base 直接 RL 时,早期模型主要先学会适配答案抽取格式,例如数学题里的 \boxed{}。这说明如果完全没有 SFT,RL 的前期一部分预算会浪费在“让 reward function 能读懂答案”上。
但报告也发现,轻量 SFT 只做格式对齐不够。MiMo-7B-RL-LiteSFT 初始更高,但 500 steps 后被 Base 直接 RL 的轨迹反超,最终也不如重 SFT 后的 MiMo-7B-RL。
这说明 SFT 的理想作用不是只教格式,而是提供更完整的:
- answer formatting;
- chain-of-thought / long reasoning style;
- math/code 解题先验;
- general dialogue / instruction following;
- 避免 RL 早期乱探索。
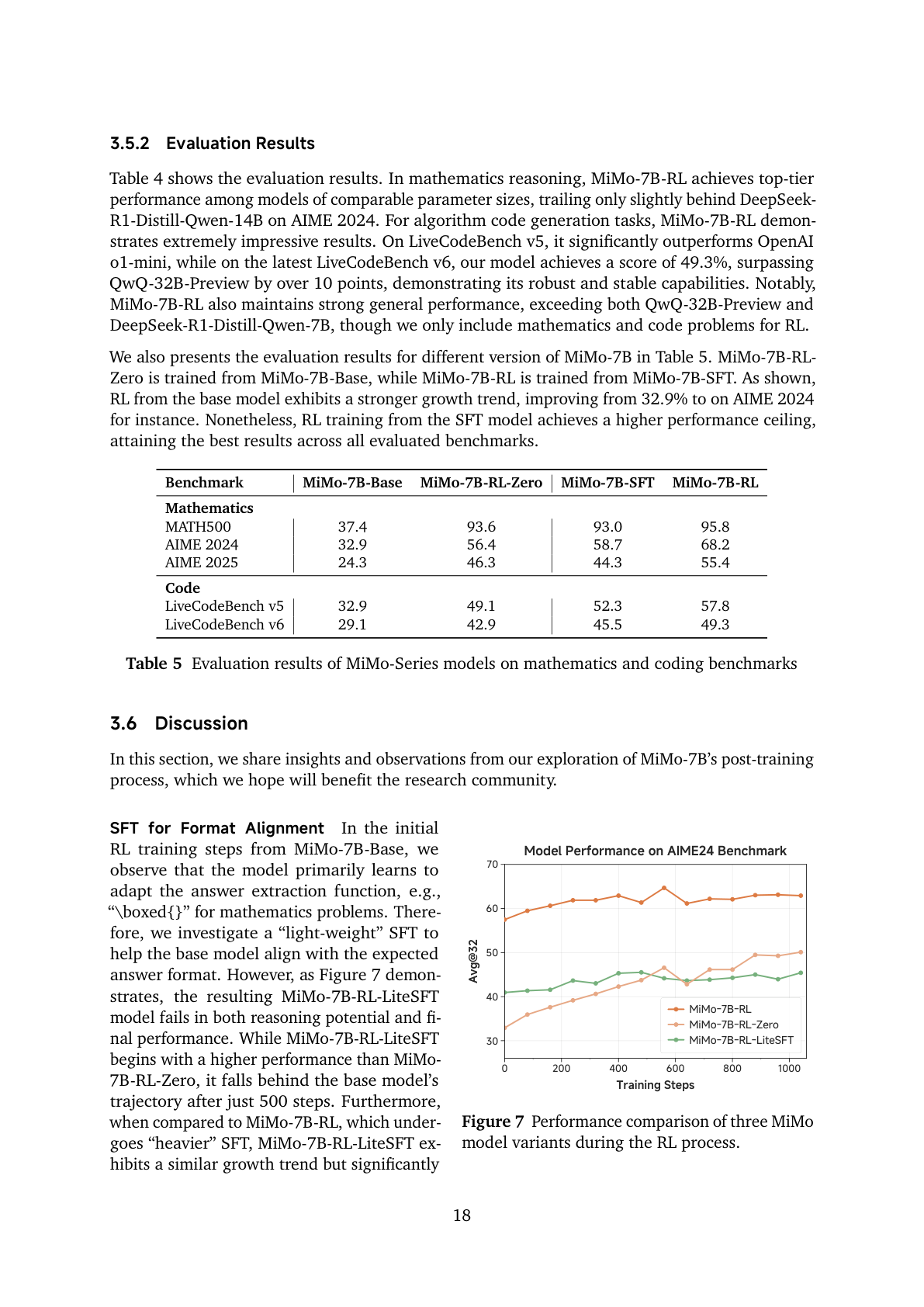
#8. RL 数据:130K 可验证数学/代码题,不靠模型奖励
MiMo 的 RL 数据包括两类:
- 100K mathematics problems;
- 30K code problems。
合计约 130K verifiable problems。
#8.1 数学数据:保留原题,过滤证明题和选择题
数学题来源包括开源数据和私有收集的竞赛级题目。清洗重点:
- 用 LLM 过滤 proof-based 和 multiple-choice problems;
- 不把题目强行改成 integer answer,以降低 reward hacking 风险;
- 全局 n-gram 去重;
- 与评测集 decontamination。
难度筛选也很关键:
- 先过滤 advanced reasoning models 都解不了的题:可能太难或答案错误;
- 对剩余题,用 MiMo-7B 的 SFT 版本 rollout 16 次;
- 去除 pass rate 超过 90% 的题;
- 这个过程移除了原始题集中约 50% easy problems。
这背后的逻辑是:
RL 数据太简单,模型全做对,没有梯度;太难,模型全做错,也没有有效正样本。最有价值的是模型“有时做对、有时做错”的临界区题目。
#8.2 代码数据:必须有 test cases,且要排除坏题
代码题来源包括开源数据和新收集题集。清洗规则:
- 去掉没有 test cases 的题;
- 如果有 golden solution,要求 golden solution 必须通过所有 test cases;
- 如果没有 golden solution,则用 advanced reasoning models 16 次 rollout,若没有任何 test case 能被解决则丢弃;
- 类似数学,用 MiMo-7B-SFT 去掉 16 次 rollout 全对的 easy problems。
最终得到 30K code problems。
#8.3 奖励函数:只用 rule-based accuracy rewards
MiMo 明确不用额外奖励:
- no format reward;
- no length penalty reward;
- no learned reward model。
数学用 rule-based Math-Verify library 判断正确性。代码用 test cases,但不是简单 all-or-nothing,而是后面要讲的 test difficulty driven reward。
这点很重要:MiMo 尽量避免 learned reward model 带来的 reward hacking,把训练建立在可验证信号上。
#9. RL 算法:改造版 GRPO,去 KL、动态采样、提高 clip 上界
MiMo 使用 modified GRPO。基本形式是:对每个问题采样一组 responses,用组内 reward 标准化得到 advantage,然后做 clipped policy optimization。
报告采纳了社区近期几个改进:
#9.1 Removal of KL Loss
直接移除 KL loss。报告引用的观察是:去掉 KL 可以释放 policy model 潜力,同时不破坏稳定性。
直觉上,KL 会把模型拉回 reference policy,防止跑偏;但在推理 RL 中,如果 reference policy 本身还不够强,过强 KL 可能限制探索。MiMo 选择相信可验证 reward 和其他稳定机制。
#9.2 Dynamic Sampling
RL rollout 时 over-sample,然后过滤掉 pass rate = 1 和 pass rate = 0 的 prompts,只保留有有效梯度的问题,同时维持固定 batch size。
这一步可以理解为自动找训练临界区:
- 全对题:没有学习信号;
- 全错题:组内没有正向样本;
- 有对有错题:最适合更新。
Dynamic sampling 会随着模型能力提升自动调整题目难度。
#9.3 Clip-Higher
提高 PPO/GRPO clipping 的上界 epsilon_high,下界 epsilon_low 固定。这是为了缓解 entropy convergence,让 policy 更愿意探索新解法。
对 reasoning RL 来说,这尤其重要:如果模型太早熵塌缩,就会固定到某些模板化思路,很难发现更长、更复杂的解题路径。
#9.4 RL 超参
| 项目 | 设置 |
|---|---|
| training batch size | 512 |
| actor mini-batch size | 32 |
| gradient updates / iteration | 16 |
| learning rate | 1e-6 |
| max sequence length | 32768 |
| training temperature | 1.0 |
| top-p | 1.0 |
#10. 代码 RL 的关键:test difficulty driven reward
普通代码 RL 常用 all-or-nothing reward:代码通过所有测试,reward=1;否则 reward=0。
问题是,算法题往往很难。一个模型可能已经写出了能过一部分 subtasks 的代码,但只要没过全部测试,就完全没有奖励。这会造成严重 sparse reward。
MiMo 提出 test difficulty driven reward,灵感来自 IOI 评分。
#10.1 先按测试用例难度分组
他们用多个模型对每个 coding problem 做多次 rollout,统计每个 test case 的 pass rate。
- pass rate 高:容易测试;
- pass rate 低:困难测试。
然后把测试用例聚类为不同 difficulty levels。
#10.2 两种奖励规则:strict 和 soft
分组后设计两类奖励:
Strict Reward:只有当某个解法通过某难度组及所有更低难度组的测试时,才能拿到该难度对应 reward。
Soft Reward:把每组总分平均分给该组内测试,通过哪些测试就加哪些分。
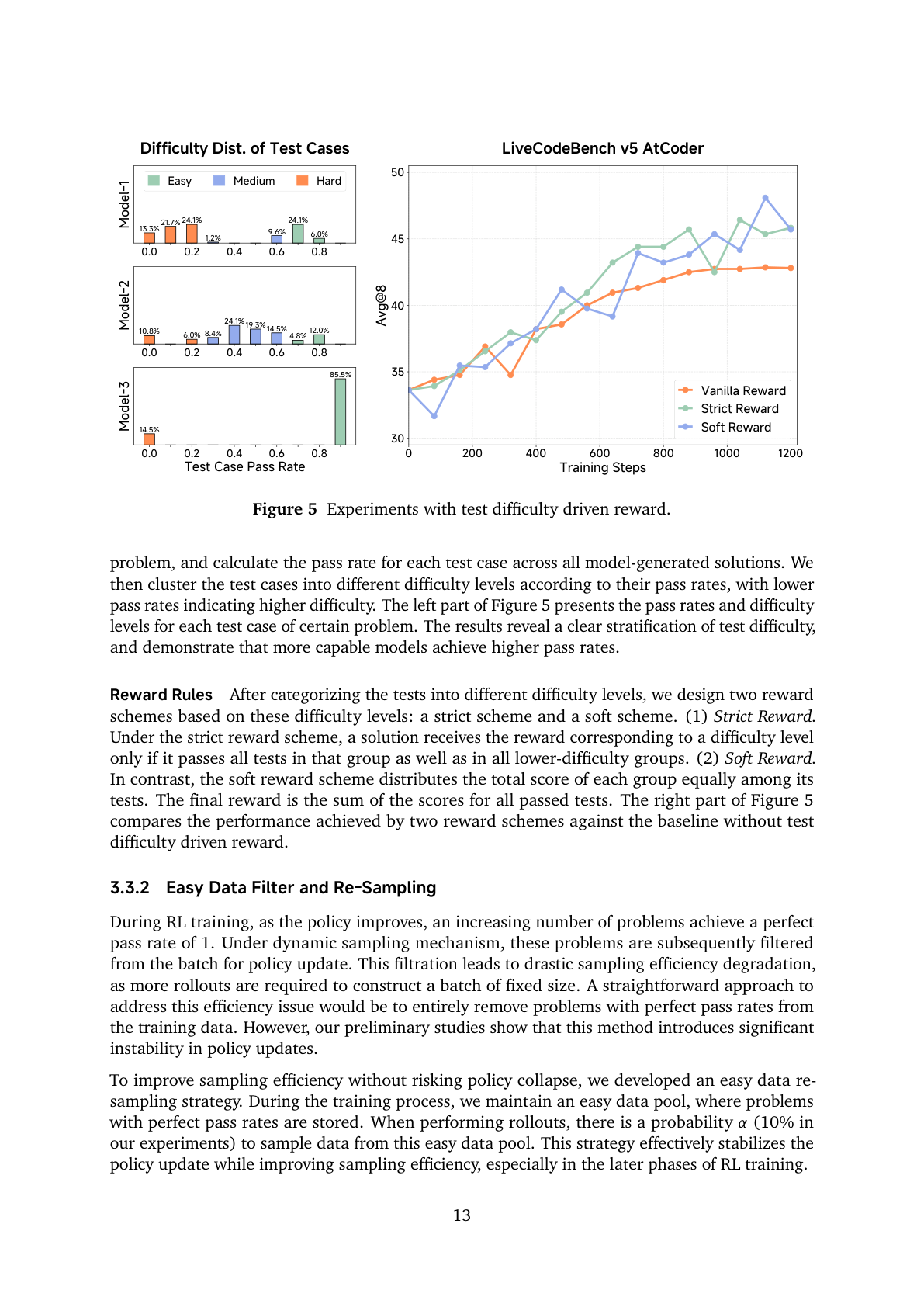
这个设计的意义是:
- 对很难的题,模型只要解决一部分 subtasks,也能得到非零信号;
- reward 更接近人类竞赛评分;
- hard code problems 不再被 all-or-nothing 奖励浪费;
- dynamic sampling 也更容易拿到有效梯度。
对 code agent / coding RL 很有启发:代码任务的奖励不应该只看最终全通过,还应该利用 test suite 内部结构,把测试用例本身变成细粒度课程。
#11. Easy Data Filter and Re-Sampling:能力变强后,如何避免采样效率崩掉?
Dynamic sampling 有一个副作用:随着模型变强,越来越多题会 pass rate = 1,然后被过滤掉。为了凑够固定 batch,需要越来越多 rollout,采样效率下降。
最简单的方法是:把 easy problems 从训练集中删掉。
但报告发现,这会导致 policy update 不稳定,甚至 collapse。为什么?可能因为 easy problems 虽然没有强梯度,但它们维持了策略分布的基本稳定性;完全删掉后,训练分布突然变得过难或过偏。
MiMo 的方案是维护一个 easy data pool:
- 训练中把 pass rate = 1 的问题放进 easy pool;
- rollout 时以概率
alpha = 10%从 easy pool 采样; - 其余时间采样正常数据。
这相当于在 hard curriculum 中保留少量 easy replay,作用类似稳定器:
大部分 batch 用临界难度题推动能力增长
少部分 batch 用 easy pool 防止分布漂移和策略崩掉
#12. RL 系统工程:Seamless Rollout Engine 解决 GPU 空转
MiMo 的 RL 系统基于 verl + Ray + vLLM。报告花了不少篇幅讲系统工程,因为长序列 reasoning RL 的瓶颈不只是算法,还有 GPU 利用率。
问题主要有三个:
- rollout 长度高度不均匀:有些样本很快结束,有些生成 30K token;
- code reward computation 很慢:需要跑大量 test cases;
- dynamic sampling 会产生额外无效样本和同步等待。
朴素实现里,很多 GPU 会等待少数长 rollout worker,导致 idle time 很高。
MiMo 提出 Seamless Rollout Engine,包含三个组件:
- continuous rollout;
- asynchronous reward computation;
- early termination。

#12.1 Continuous Rollout
朴素 dynamic sampling 会等所有 rollout workers 完成后再统一算 reward。Seamless Rollout Engine 会持续监控已完成 worker:
- 某个 rollout 完成就立刻进入 reward computation;
- 根据当前 valid samples 和 pass-rate 统计,判断是否需要启动新 rollout;
- 避免全局 barrier。
这类似把 rollout 变成流水线,而不是一批一批同步执行。
#12.2 Asynchronous Reward Computation
数学 reward 很快,但代码 reward 很慢。MiMo 用 Ray 做异步 reward computation,并为 code-specific reward computation 分配专门服务器,避免 judge 成为 rollout pipeline 的瓶颈。
这点对 code RL 非常现实:如果 reward 需要执行几千道题、每题几百个 test cases,CPU/沙箱/IO 的调度也会成为训练系统核心部分。
#12.3 Early Termination
当 valid samples 已经超过所需 batch size 时,可以终止多余 rollout。但如果粗暴终止,可能会系统性偏向短输出,压制长 reasoning。
MiMo 用 FIFO selection:只有当 valid sample 数满足 batch requirement,且被选样本之前启动的任务都完成后,才终止后续任务。这样尽量保持数据分布不被“谁短谁先入选”扭曲。
#12.4 系统效果
报告在 256 H20 GPUs 上的 5-step trace 中比较:
| 方法 | Overall Speedup | Rollout Speedup | GPU Idle Ratio | Sample Waste Ratio |
|---|---|---|---|---|
| Naive Dynamic Sampling | 1.00x | 1.00x | 69.3% | 22.1% |
| + Continuous Rollout | 1.99x | 2.20x | 38.8% | 13.9% |
| + Async Reward | 2.09x | 2.34x | 34.0% | 16.4% |
| + Early Termination | 2.29x | 2.61x | 27.7% | 12.9% |
Validation 也有 1.96x speedup,GPU idle ratio 从 65.8% 降到 32.9%。
这说明长推理 RL 不是简单“多堆 GPU”就行,系统调度会直接决定训练是否经济可行。
#13. vLLM 改造:支持 MTP,并增强 external launch 稳定性
MiMo 的 RL 系统使用 vLLM 作为 inference engine,并做了两类增强。
#13.1 MTP Support
因为 MiMo 模型带 MTP modules,所以他们在 vLLM 中实现并开源了对应支持,使 MTP-equipped architecture 可以高效推理。
#13.2 Better Robustness
verl 中 vLLM 使用 external launch mode,某些场景不稳定。MiMo 做了两个增强:
- pre-emption 时清除 prefix caching 中 computed blocks,保持 KVCache consistency;
- 增加 scheduler steps 时禁用 asynchronous output processing,保证兼容性和性能。
这些细节看似工程,但在 RL 训练中很关键:任何 KV cache 不一致、推理引擎异常,都可能造成 rollout 错误、reward 错误或训练中断。
#14. 最终效果:7B 模型的数学、代码与通用能力
MiMo-7B-RL 在多个 benchmark 上表现很强:
| Benchmark | MiMo-7B-RL |
|---|---|
| MATH500 | 95.8 |
| AIME 2024 | 68.2 |
| AIME 2025 | 55.4 |
| LiveCodeBench v5 | 57.8 |
| LiveCodeBench v6 | 49.3 |
| GPQA Diamond | 54.4 |
| SuperGPQA | 40.5 |
报告称 MiMo-7B-RL 在 AIME 2025 上超过 o1-mini,在 LiveCodeBench v5/v6 上也强于 o1-mini。
不同版本之间的对比也很说明问题:
| Benchmark | Base | RL-Zero | SFT | RL |
|---|---|---|---|---|
| MATH500 | 37.4 | 93.6 | 93.0 | 95.8 |
| AIME 2024 | 32.9 | 56.4 | 58.7 | 68.2 |
| AIME 2025 | 24.3 | 46.3 | 44.3 | 55.4 |
| LiveCodeBench v5 | 32.9 | 49.1 | 52.3 | 57.8 |
| LiveCodeBench v6 | 29.1 | 42.9 | 45.5 | 49.3 |
几个观察:
- RL-Zero 已经很强:Base 直接 RL 就能大幅提升;
- SFT 本身也很强:数学/代码 pass@1 直接明显提高;
- SFT + RL 最强:说明 SFT 没有完全损害 RL 潜力,反而提供更高起点和更稳定增长;
- 代码提升稳定:test-case reward 比数学更难被 hack,报告也提到 base RL 后期数学会波动,代码继续涨。
#15. 后续增强版 MiMo-7B-RL-0530:SFT 扩到 6M,RL window 扩到 48K
README 和报告 discussion 中提到后续版本 MiMo-7B-RL-0530。它有两个关键增强:
- SFT 数据从约 500K 扩到 6M;
- RL training window 从 32K 持续扩到 38K,再到 48K。
#15.1 SFT 扩容并没有压死 RL 潜力
报告称 6M SFT 带来明显提升,包括数学、代码、科学推理和通用对话,同时没有损害后续 RL potential。
| Benchmark | SFT-500K | SFT-6M | RL | RL-0530 |
|---|---|---|---|---|
| AIME 24 | 58.7 | 68.3 | 68.2 | 80.1 |
| AIME 25 | 44.3 | 50.9 | 55.4 | 70.2 |
| MATH500 | 93.0 | 94.8 | 95.8 | 97.2 |
| GPQA Diamond | 50.7 | 54.1 | 54.4 | 60.6 |
| LiveCodeBench v5 | 52.3 | 53.4 | 57.8 | 60.9 |
| AlignBench v1.1 | 6.7 | 7.1 | 6.9 | 7.4 |
这说明一个可能的经验规律:只要 SFT 数据足够高质量、多样、推理密集,大规模 SFT 不一定会“把模型训死”,反而能给 RL 更好的初始策略。
#15.2 生成长度预算是 reasoning scaling 的一部分
MiMo-7B-RL-0530 使用 on-policy RL,并逐步增加 generation length:
32K → 38K → 48K
报告观察到,持续提高 generation budget 能持续提升 AIME24 表现,最终 7B 模型在数学推理上达到接近 DeepSeek-R1 的水平。
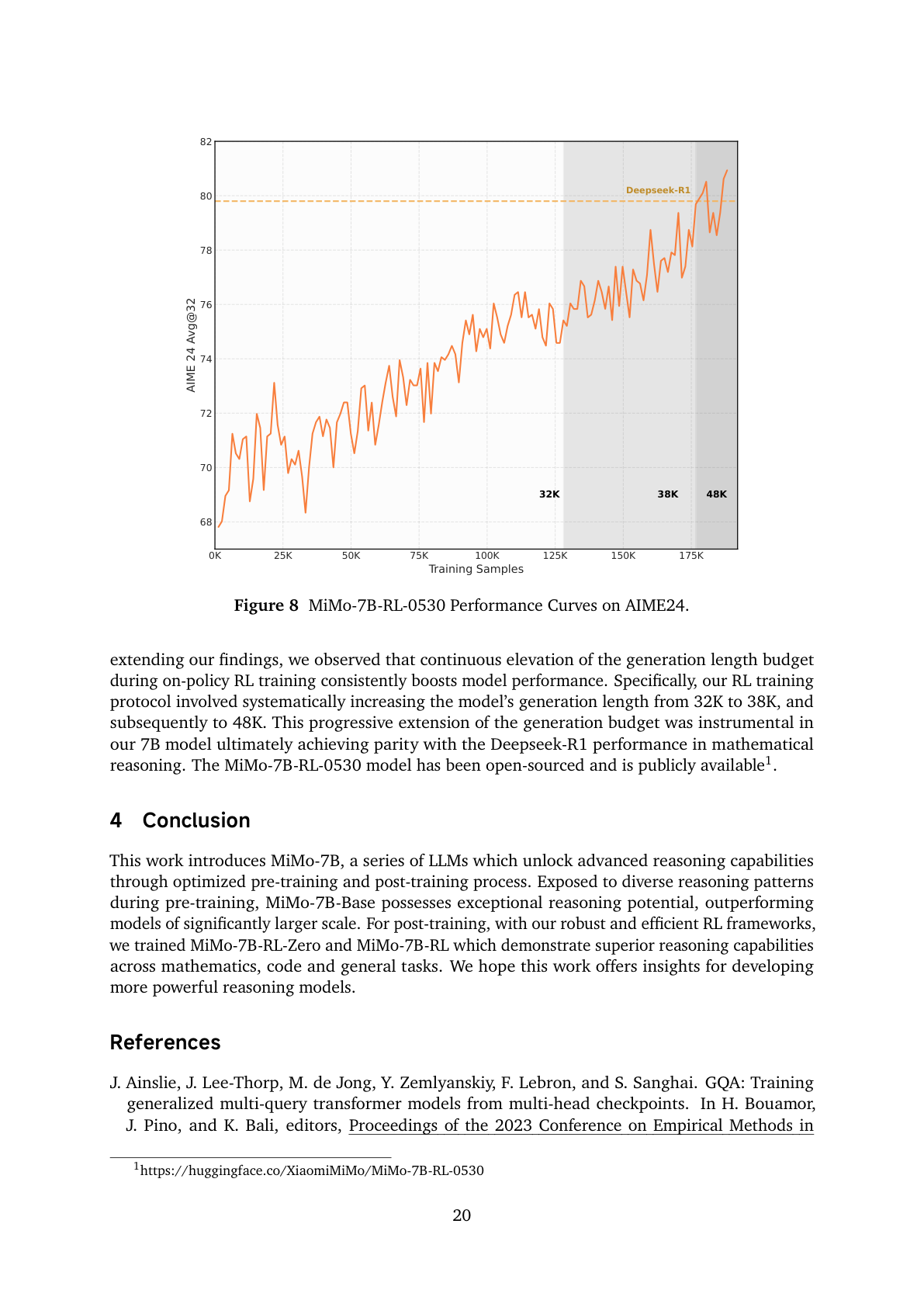
这个结论对长轨迹 agent RL 也很有启发:上下文长度/生成预算不是单纯的推理时参数,而是训练时 curriculum 的一部分。模型如果训练时从未在 48K budget 下探索,很难指望推理时突然稳定利用这么长的轨迹。
#16. MiMo-7B 暴露出的几个训练规律
#16.1 Base model 的 pass@k 可能比 pass@1 更能预测 RL 潜力
如果一个 base model pass@1 一般,但 pass@k 很高,它说明模型已经能采到正确轨迹,只是概率不够集中。RL 正好可以提高这些好轨迹的概率。
这对 base model 评估很重要:未来训练 reasoning base model 时,不能只看常规 benchmark 的单次分数,还要看:
- pass@k;
- entropy;
- solution diversity;
- correct trajectory 的可采样性;
- 错解和正解之间的 reward 可分性。
#16.2 预训练数据的“推理密度”比单纯 token 数更重要
MiMo 的 25T tokens 当然很大,但更关键的是:
- 数学/代码 extraction 不被破坏;
- synthetic reasoning 被放入预训练;
- Stage 2 数学/代码占比到 70%;
- Stage 3 用长上下文和 synthetic responses 收尾。
这说明 reasoning model 的 base training 可能需要专门配方,而不是通用 LLM 训练完再 SFT/RL。
#16.3 可验证 RL 的数据难度要卡在“临界区”
MiMo 数学/代码数据都过滤了太简单和太难的题。Dynamic sampling 也是同一思想:只训练有有效梯度的问题。
这类似 curriculum learning,但不是人工分阶段,而是用 rollout pass rate 动态定义难度。
#16.4 Code RL 的 reward 可以比 math 更细
数学题很多时候只有最终答案,reward 比较稀疏。代码题虽然也可以 all-or-nothing,但 test suite 内部天然有结构。
MiMo 的 test difficulty driven reward 把 test cases 变成 subtask-level signal,这对训练 coding model 很关键。未来更复杂的 agent RL 也可能需要类似结构:
- terminal task 的中间 observation;
- unit tests 的分层;
- benchmark 中 hidden/public tests 的难度估计;
- tool-use trajectory 的局部可验证节点。
#16.5 RL 系统本身会改变可研究的问题边界
Seamless Rollout Engine 把 naive dynamic sampling 的整体训练速度提高到 2.29x。如果没有这种系统优化,很多算法看起来“理论上可行”,但实际 GPU idle 太高,根本跑不起。
对长轨迹 RL 尤其如此:
- rollout 长度重尾;
- reward 计算慢;
- 有效样本比例动态变化;
- 同步 barrier 极其昂贵。
所以未来 agentic RL 的核心不只是 objective,也包括 rollout/reward/training 的异步系统设计。
#17. 对 LLM Agent / 长轨迹 RL 的启发
MiMo-7B 虽然主要做数学和代码题,不是完整 tool-use agent,但它对 agent 研究有几个直接启发。
#17.1 Agent base model 也需要“预训练时就像 agent”
MiMo 的核心是:推理能力不是后训练凭空出现的,而是 base model 需要在预训练中看到足够多推理模式。
类比到 agent:如果我们希望模型会长期规划、读文件、调用工具、修 bug、根据 observation 调整策略,那么也许不能只靠后训练 agent trajectories,而要在预训练/持续预训练阶段提高这些模式的密度:
- terminal logs;
- issue → patch → test → fix trajectories;
- action / observation 交替数据;
- long-horizon debugging traces;
- self-reflection and backtracking traces。
#17.2 可验证任务的数据选择比算法名更重要
MiMo 用 130K 高质量可验证题,而不是越多越好。Agent RL 也类似:
- 任务必须能可靠验证;
- 太简单没有梯度;
- 太难没有正样本;
- reward 不能容易被 hack;
- 数据要不断跟随 policy 能力移动。
#17.3 长轨迹训练需要动态采样和异步系统
Agent trajectories 比数学/代码更长、更重尾、更不均匀。MiMo 的 continuous rollout、async reward、early termination 可以看作 agent RL 系统的雏形。
未来如果做 software engineering agent RL,可能需要:
- 多 worker 异步执行环境;
- test reward 并行化;
- 根据任务 pass rate 动态采样;
- 防止短任务偏置;
- 对长轨迹做 FIFO / windowed scheduling;
- 将工具 observation 的计算和 policy update 解耦。
#17.4 生成长度 curriculum 可能对应 agent horizon curriculum
MiMo-7B-RL-0530 从 32K 扩到 48K 后继续涨。这对 agent 意味着:
不要指望模型在短轨迹训练后,推理时自然泛化到超长轨迹。训练时就要逐步扩大 horizon。
Agent 里对应的 curriculum 可能是:
单文件 bug fix
→ 多文件 bug fix
→ 小 feature
→ repo-level feature
→ 多轮 issue + PR + CI 修复
而不是一开始就扔给模型完整 SWE-bench Verified 或真实工程任务。
#18. 这篇报告也有哪些局限?
#18.1 数据细节仍然不完全公开
报告给出了数据类型、清洗策略、比例和规模,但很多关键细节无法复现:
- synthetic reasoning data 的具体生成 prompt;
- small LLM quality tagger 的训练细节;
- 私有数学/代码题来源;
- SFT proprietary distilled data;
- difficulty assessment 的完整 pipeline。
因此我们可以学习设计原则,但很难完全复刻。
#18.2 数学 reward hacking 仍然存在
报告提到 Base RL 后期数学性能会波动甚至下降,原因之一是 base model 可能 hack 数学 reward;代码因为 test-case verifier 更硬,反而更难 hack。
这说明数学可验证 RL 的 reward 仍然没有代码那么可靠。最终答案匹配、Math-Verify、格式抽取都可能成为攻击面。
#18.3 SFT 数据扩容的边界还不清楚
MiMo-7B-RL-0530 表明 500K → 6M SFT 有收益,但这不意味着无限扩 SFT 都好。关键仍然是:
- SFT 数据质量;
- 推理轨迹多样性;
- 是否包含错误/捷径;
- 是否压低 entropy;
- 是否损害 RL exploration。
#18.4 7B 成功不等于所有能力都能小模型化
MiMo 在数学和代码上很强,但通用智能、真实 agent、多模态、开放式研究任务仍然是更复杂的分布。报告证明的是:如果预训练和 RL 数据高度围绕可验证推理设计,7B 模型可以释放很强能力。它不直接证明 7B 足够解决所有长程开放任务。
#19. 最后总结:MiMo-7B 的训练 recipe 可以抽象成什么?
如果把 MiMo-7B 的训练过程抽象成 recipe,大概是:
1. 先在预训练阶段提高 reasoning pattern 密度
- 保留数学公式、代码块、论坛结构、STEM PDF
- 用小模型做多维质量过滤
- 合成高质量 reasoning traces
2. 用三阶段 mixture 做能力 curriculum
- Stage 1:通用高质量数据
- Stage 2:数学/代码提高到约 70%
- Stage 3:加入约 10% synthetic responses,并扩到 32K context
3. 架构上加入 MTP
- 预训练时辅助学习未来 token
- 推理时 speculative decoding 加速长 reasoning
4. SFT 做冷启动,但不是只教格式
- 去污染、去坏样本、保留多样 responses
- 让模型具备长推理、对话、格式和任务先验
5. RL 只用可验证数学/代码题
- 100K math + 30K code
- 过滤太难/太简单问题
- rule-based accuracy rewards
6. 改造 GRPO
- remove KL
- dynamic sampling
- clip-higher
- 32K max generation
7. 代码 reward 做细粒度化
- 按 test case pass rate 分难度
- strict/soft partial reward 缓解 sparse reward
8. 系统层面消除 rollout/reward idle
- continuous rollout
- async reward computation
- early termination
9. 后续继续扩 SFT 和 RL horizon
- SFT 500K → 6M
- RL window 32K → 38K → 48K
MiMo-7B 最值得带走的观点是:
Reasoning model 的训练不是“预训练一个普通 base,再靠 RL 点石成金”。更像是从数据抽取、数据 mixture、架构目标、SFT 冷启动、RL 数据难度、reward 设计到 rollout 系统的一整套 co-design。预训练决定可探索空间,SFT 决定起点和行为先验,RL 决定把哪些轨迹概率放大,系统工程决定你能不能负担这种搜索。
对之后做 LLM Agent、代码智能和长轨迹 RL 来说,MiMo-7B 的价值不只是一个 7B 模型分数,而是提供了一个很清晰的方向:把“模型会不会推理”前移到预训练数据和 base policy 设计里,再用可验证 RL 和高效系统释放它。