#Latent Spatial Memory for Video World Models:把 3D 世界记忆搬进扩散模型的 latent space
论文:Latent Spatial Memory for Video World Models
作者:Weijie Wang、Haoyu Zhao、Yifan Yang、Feng Chen、Zeyu Zhang、Yefei He、Zicheng Duan、Donny Y. Chen、Yuqing Yang、Bohan Zhuang
机构:Zhejiang University、Microsoft Research、Adelaide University、Monash University
这篇论文的核心问题可以用一句话概括:如果我们希望视频生成模型真的像“世界模型”一样记住一个 3D 场景,而不是每一帧都临时编一个看起来合理的画面,那么这个记忆应该存在什么空间里?
过去很多方法的答案是:存在 RGB 空间里。模型生成一帧图像,估计深度,把 RGB 像素反投影成 3D 点云;下一次要生成新视角时,再把点云渲染成图像,送回 VAE / diffusion backbone 里继续生成。
这篇论文的答案是:不要把模型已经学到的 latent feature 解码成 RGB 再编码回来。直接把空间记忆存在 diffusion latent space 里。 作者把这个表示叫作 latent spatial memory,并基于它提出了 Mirage。
如果用人话讲,Mirage 做的是:
传统方法像是让模型每走一步都把脑中的地图打印成照片,再把照片重新扫描回脑子里;Mirage 则直接把“脑内地图”存在模型自己的 latent 表示里,需要时直接读取这张脑内地图。

上图展示了任务直觉:给定一个初始图像和相机运动轨迹,模型需要生成后续视频,并且在视角大幅移动、甚至绕回来时仍然保持几何一致。难点不在于单帧是否好看,而在于这些帧是否属于同一个稳定的 3D 世界。
#1. 这篇论文想解决什么问题?
大规模视频扩散模型已经能生成很逼真的短视频,但如果把它当作“世界模拟器”,问题马上暴露出来:
- 几何漂移:每一帧看起来都像真的,但合在一起不是同一个 3D 场景。墙、窗、桌子、道路可能在时间中慢慢变形。
- 长轨迹不稳定:相机走远再回来时,模型可能忘记一开始看到的东西。
- 缓存开销大:为了保持空间一致,已有方法通常维护 RGB 点云,但每一步都要渲染、VAE 编码、扩散条件注入,计算和显存都很重。
- 信息损失:扩散模型本来在 latent space 工作。把 latent feature 解码成 RGB,再编码回 latent,会丢掉很多语义和纹理信息。
所以论文的出发点不是“再训练一个更大的视频生成器”,而是问一个更基础的表示问题:
如果视频扩散模型的生成过程本来就在 latent space 中完成,为什么 3D 空间记忆一定要降级成 RGB 点云?
这个问题非常关键。RGB 点云对人类可解释,但对模型未必是最自然的内部状态。对于一个 latent diffusion model 来说,RGB 其实是输出接口,不一定是最好的中间记忆格式。
#2. 传统 RGB 点云记忆为什么笨重?
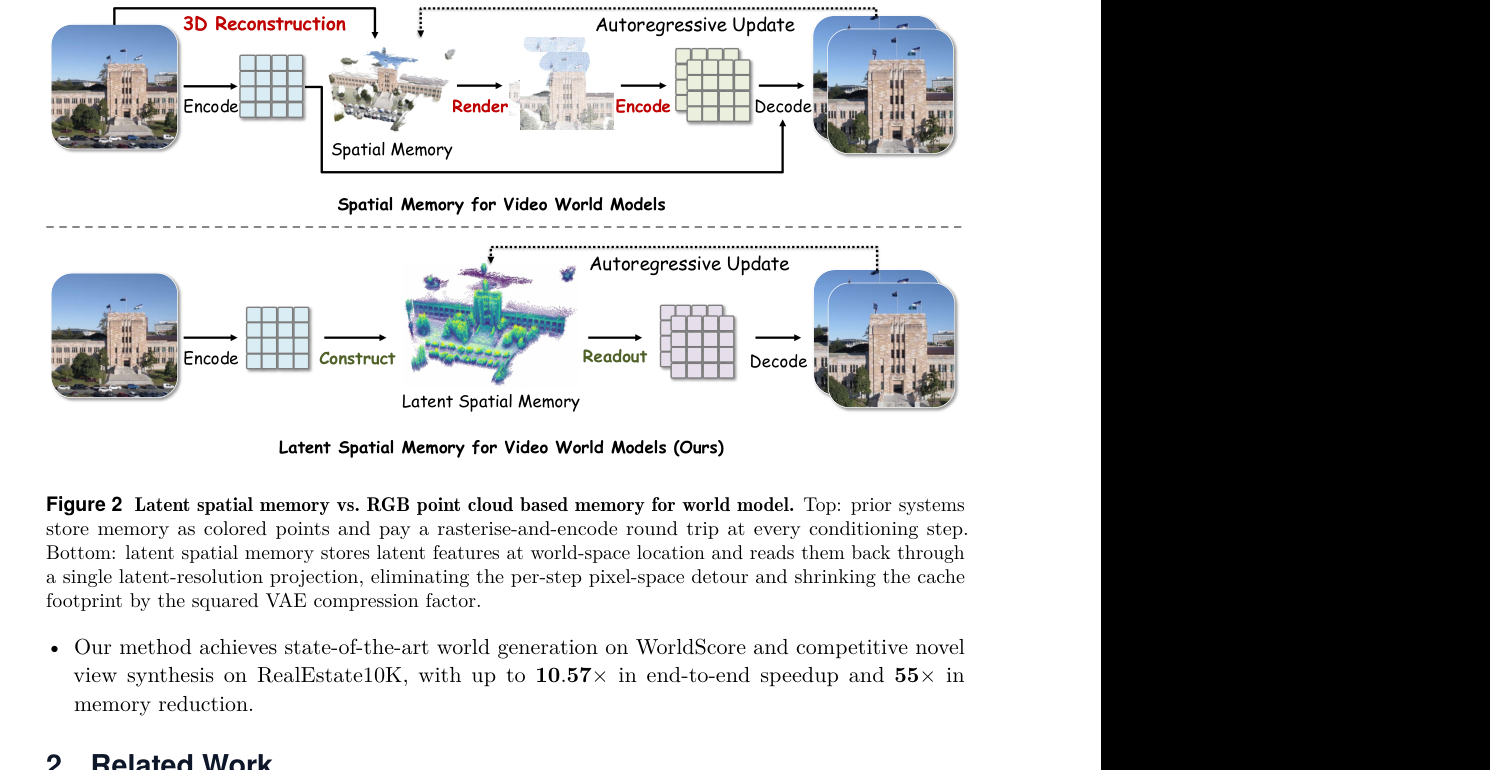
Figure 2 是理解全文最重要的动机图。上半部分是已有 RGB point cloud memory,下半部分是本文的 latent spatial memory。
传统流程大致是:
- 生成或观察一帧 RGB 图像;
- 用深度估计把图像反投影成 3D 点云;
- 把 RGB 颜色挂在 3D 点上;
- 需要新视角时,把点云 render 成一张图;
- 再把这张图 encode 回 VAE latent;
- 把这个 latent 当作条件送给视频扩散模型。
问题在第 4、5 步。它们构成了一个反复发生的 render-and-encode round trip:
- render 很贵,点云越来越大时更贵;
- VAE encoder 很贵,每一步都 encode 更贵;
- RGB 只有三通道,无法完整保留扩散 latent 中丰富的语义、材质和纹理表示;
- 反复 RGB ↔ latent 往返,会让模型在自己最熟悉的表示空间之外绕路。
Mirage 的改法是:把每个 3D 点携带的属性从 RGB 颜色换成 latent feature。也就是一个点不再是 (x, y, z, r, g, b),而更像是:
(world coordinate, diffusion latent feature)
这样读记忆时,不需要先渲染 RGB 图再编码,只需要把 3D latent memory 投影到目标相机视角的 latent grid 上,直接得到可注入 diffusion backbone 的条件特征。
#3. Mirage 的核心机制:初始化、读取、更新

Mirage 的整体流程可以分成三步:初始化 memory、读取 memory、更新 memory。
#3.1 初始化:把首帧 latent token 提升到 3D
给定初始图像 I0,Mirage 先做两件事:
- 用 VAE encoder 把图像编码成 latent feature map;
- 用深度估计模型预测每个位置的 depth。
然后它把 latent feature map 中的每个 token,根据对应深度和相机参数反投影到 3D 世界坐标里。于是 memory M 可以理解为一组 latent-attributed 3D points:
M = {(p_i, f_i)}
其中 p_i 是 3D 位置,f_i 是这个位置对应的扩散 latent feature。
这里的关键不是“用了点云”,而是点云上存的不是 RGB,而是模型内部 latent feature。
#3.2 读取:把 3D latent memory 投影成目标视角 latent grid
当模型要生成某个目标相机视角时,Mirage 会把 memory 中的 3D 点投影到这个目标相机的 latent-resolution 网格上,形成目标视角下的 latent feature tensor。
这一步可以理解成:
不是从 3D 点云渲染出一张 RGB 图片,而是从 3D latent memory “渲染”出一张 latent feature map。
这张 feature map 会通过 ControlNet-style side branch 注入到 diffusion backbone 中,作为几何和外观条件,帮助模型在新视角下生成和历史场景一致的视频帧。
这也解释了为什么它快:它绕开了 RGB rasterization + VAE encode 这条昂贵路径。
#3.3 更新:生成新 chunk 后,把新观测写回 memory
Mirage 按 chunk 生成视频。每生成一个 chunk,它会:
- 解码出 RGB 帧;
- 对这些帧估计深度;
- 把对应 latent feature 反投影回 3D;
- 写入 latent spatial memory。
但它不会无脑写入所有东西。论文特别强调了 dynamic object filtering:移动物体和天空等几何不可靠区域会被过滤掉,避免把短暂、动态、不可稳定定位的内容污染长期空间记忆。
这点很重要。Mirage 的 memory 更适合记住静态或相对刚性的场景结构,比如房间、墙面、道路、建筑、家具,而不是持续追踪每个动态 actor 的状态。
#4. 为什么 latent memory 不只是“省算力”而已?
这篇论文最有意思的地方在于:latent memory 的价值不只是效率优化,而是表示空间更匹配。
RGB 点云有一个隐含假设:世界记忆应该以人眼可见的颜色形式存在。但对 diffusion model 来说,真正参与生成决策的是 latent representation。RGB 是最后给人看的输出,不一定是模型最适合推理和记忆的状态。
所以 latent spatial memory 有三层意义:
- 少一次信息压缩:不把 latent 压成 RGB 三通道,保留更丰富的语义和纹理信息。
- 少一次计算往返:不反复 render RGB 再 VAE encode。
- 更贴近生成器分布:memory readout 直接产生 backbone 熟悉的 latent feature,而不是经过插值、渲染、编码后可能偏离训练分布的信号。
论文的消融也支持这一点。作者把 latent cache 替换成 explicit RGB point cloud 后,Average Score 从 full Mirage 的 70.36 降到 67.71,3D consistency 和 photometric consistency 也下降。这说明 latent cache 不只是“同样东西的更快版本”,而是确实保留了 RGB detour 会丢掉的信息。
#5. 实验结果:质量、闭环一致性和效率
论文主要在两个方向评估:
- WorldScore:更综合地评估世界生成质量,包括静态、动态、相机控制、3D 一致性、照片一致性、运动等维度;
- RealEstate10K:评估新视角合成和 closed-loop 回访一致性。

在 WorldScore 上,Mirage 达到最高 Average Score。论文报告 Mirage 优于同样带空间记忆的 Spatia,也明显超过缺少持久空间表示的一般视频模型。尤其值得注意的是,Mirage 在 3D consistency 和 photometric consistency 上表现强,说明 latent spatial memory 对“同一个世界”的保持确实有帮助。
在 RealEstate10K 上,Table 2 显示 Mirage 的表现也很强:
- Novel View Synthesis:PSNR 18.38,SSIM 0.779,LPIPS 0.250;
- Closed-Loop:PSNRC 20.05,SSIMC 0.825,LPIPSC 0.228。
和 Spatia 相比,Mirage 的 PSNR 略低一点,但 SSIM 和闭环 SSIM 明显更高。这个结果可以理解为:它不一定在所有像素级指标上都碾压,但在结构一致性和回访一致性上优势非常明显。

Figure 7 展示了 closed-loop revisit:相机走一圈后回到接近起点的位置,模型生成的画面应该和初始帧一致。这是检验世界模型记忆能力的关键测试。如果模型只是逐帧生成,回到原点时很容易“忘记”原来的布局;如果它真的维护了空间记忆,就应该能重新看到相同的房间结构、窗户、家具和场景布局。
#6. 效率结果:10.57× 加速和 55× 显存降低从哪里来?
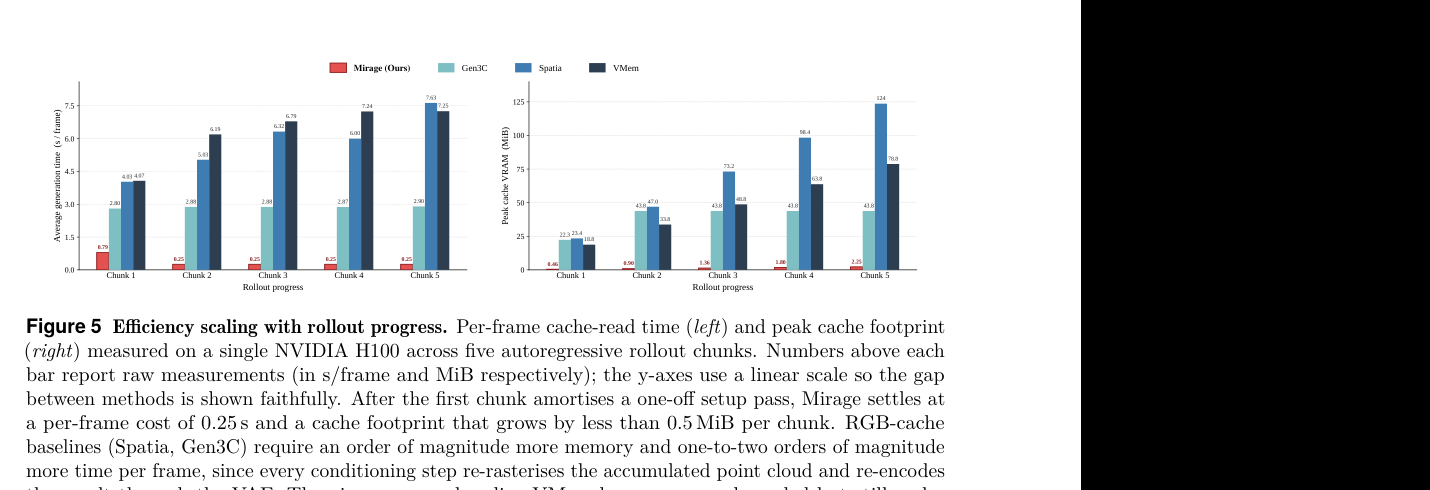
论文报告 Mirage 相比 RGB-cache baselines 最多实现:
- 10.57× faster end-to-end video generation;
- 55× lower GPU memory usage / memory footprint。
这个数字的来源不是某个小 trick,而是整个 pipeline 的关键路径变短了。
RGB-cache 方法每一步都要做:
3D RGB cache → rasterize/render → RGB image → VAE encode → latent condition
Mirage 则变成:
3D latent cache → latent-resolution projection → latent condition
也就是说,Mirage 把 per-step conditioning loop 中最重的 rasterization 和 VAE encoding 移走了。解码和重新编码仍然存在,但它们只在 chunk 更新时发生,被摊销到一整个视频片段上,不再是每个 conditioning step 的关键路径。
Figure 5 的趋势也很直观:随着 rollout 变长,RGB cache 的时间和显存增长越来越明显,而 Mirage 的增长更慢。这对长视频、长轨迹、agent-like world simulation 很重要,因为世界模型真正有价值的地方通常不是 2 秒短片,而是更长 horizon 下的稳定性。
#7. 消融实验说明了什么?
论文第 5.3 节做了几个关键消融,结论很清楚:
| 变体 | Average | 3D Cons | Photo Cons | 说明 |
|---|---|---|---|---|
| Mirage full | 70.36 | 92.21 | 93.95 | 完整方法 |
| Explicit RGB Point Cloud | 67.71 | 90.75 | 91.10 | 把 latent memory 换回 RGB 点云会变差 |
| Feature Upsample, Pixel Resolution Lift | 60.85 | 84.90 | 79.81 | 把 latent feature 上采样到像素分辨率再 lift,明显伤害一致性 |
| No Dynamic Object Filter | 61.20 | 80.88 | 76.10 | 不过滤动态物体会污染长期 memory |
| Single Stage Training | 63.18 | 87.11 | 84.47 | 两阶段训练比直接联合训练稳定 |
这里最值得注意的是两个结果。
第一,No Dynamic Object Filter 掉得很厉害。这说明长期空间记忆不是越多越好。如果把移动物体、天空、几何不可靠区域都写入 memory,模型后面会把过时内容重新 splat 回新视角,造成严重漂移。
第二,Feature Upsample, Pixel Resolution Lift 也掉得很厉害。这说明 latent memory 的网格和几何操作最好匹配 VAE latent 的原生分辨率。如果为了追求像素级几何精度而把 latent feature 上采样到像素空间,反而可能把 feature 推出 backbone 熟悉的分布。
这点对很多 multimodal / world model 系统都有启发:中间表示不一定越高分辨率越好,关键是它是否处在模型训练时熟悉的表示流形上。
#8. 这篇论文的局限
论文自己也指出了一个核心局限:Mirage 当前不维护动态 actor 的长期状态。
因为移动物体的几何位置不稳定,作者选择把移动实体从 persistent memory 里过滤掉。这对静态场景、建筑、室内空间、道路等很有效,但如果场景主要由运动对象构成,比如多人交互、车辆交通、机器人操作中的物体状态变化,那么 latent spatial memory 的收益会变弱。
换句话说,Mirage 更像是一个强大的 static / quasi-static scene memory,还不是完整的动态世界状态模拟器。
这也留下了很自然的下一步问题:
- 如何把动态对象也表示进 latent memory,而不是简单过滤?
- 是否需要把 memory 分成 static layer 和 dynamic actor layer?
- 动态对象的 identity、pose、velocity、affordance 应该如何和 diffusion latent 对齐?
- 对机器人或 LLM Agent 来说,动作导致的状态变化能否写入这种 latent world memory?
这些问题会把 Mirage 从“相机轨迹控制的视频世界模型”推向更一般的“可交互世界模型”。
#9. 和 LLM Agent / model-based RL / latent reasoning 的关系
这篇论文虽然是视觉视频生成方向,但它和 LLM Agent、model-based RL、latent-space reasoning 有一个非常深的共同主题:
一个智能系统的长期记忆,不一定应该存在人类可读的表层空间里,而可能应该存在模型最会计算、最会预测的 latent space 里。
对 LLM Agent 来说,这对应几个类比:
- RGB 点云像是把所有经验都转成自然语言日志,再让模型读回去;
- latent spatial memory 像是直接维护模型内部可用的世界状态表示;
- render-and-encode round trip 像是“先外化成文本,再重新理解成 hidden state”;
- direct latent readout 像是让 agent 直接从结构化 latent memory 中取出下一步推理所需的状态。
这对长轨迹 Agent RL 尤其有启发。长轨迹直接在 token 序列上做 RL,可能会遇到上下文过长、状态冗余、信用分配困难等问题。如果我们能学习某种 latent world memory,把历史交互压缩成可预测、可更新、可读取的状态,那么 agent 的推理和规划就不必完全依赖表层 token history。
当然,视觉空间记忆比语言 agent memory 更容易定义几何一致性。LLM Agent 的 latent memory 要难得多,因为它需要表示任务状态、工具状态、用户意图、环境约束和不确定性。但 Mirage 给出的启发是明确的:不要总把 memory 当作可读文本或像素缓存,也要思考 memory 是否应该和模型内部计算空间对齐。
#10. 总结:这篇论文真正重要的点
这篇论文的贡献可以概括为三层:
- 表示层贡献:提出 latent spatial memory,把 3D 空间记忆从 RGB 点云搬到 diffusion latent space。
- 系统层贡献:提出 Mirage,通过 depth-guided back-projection、latent readout、ControlNet-style 注入和 chunk-level cache update,把该表示接入已有视频扩散模型。
- 经验层贡献:在 WorldScore 和 RealEstate10K 上证明 latent memory 同时提升质量、闭环一致性和效率,最高达到 10.57× 生成加速和 55× 显存降低。
我觉得它最值得关注的不是“又一个视频生成模型”,而是它抓住了一个基础问题:世界模型的记忆应该存在哪里?
如果模型的预测能力主要存在 latent space,那把记忆存在 RGB 或文本这种外部可读形式里,可能天然就是低效且有损的。Mirage 的做法是让记忆回到模型自己的表示空间中。这一点对视频世界模型成立,对机器人世界模型、LLM Agent memory、model-based RL 和 latent reasoning 也都值得继续追问。