#HRM-Text:一篇试图把“预训练”重新做小的论文
论文:HRM-Text: Efficient Pretraining Beyond Scaling
arXiv: 2605.20613
作者:Guan Wang, Changling Liu, Chenyu Wang, Cai Zhou, Yuhao Sun, Yifei Wu, Shuai Zhen, Luca Scimeca, Yasin Abbasi Yadkori
日期:2026-05-20
这篇论文的核心野心很明确:不要把“从零预训练语言模型”默认等同于万亿 tokens、巨额算力和大厂工程,而是证明:如果架构和训练目标一起改,预训练也许可以被重新做小。
作者提出 HRM-Text:一个 1B 参数的 Hierarchical Recurrent Model 语言模型。它不是标准 decoder-only Transformer,而是把计算拆成慢速的高层模块 H 和快速的低层模块 L;训练上也不做传统 raw text next-token pretraining,而是直接用 instruction-response pairs 做 response-only 的 task-completion objective,并配合 PrefixLM attention mask。
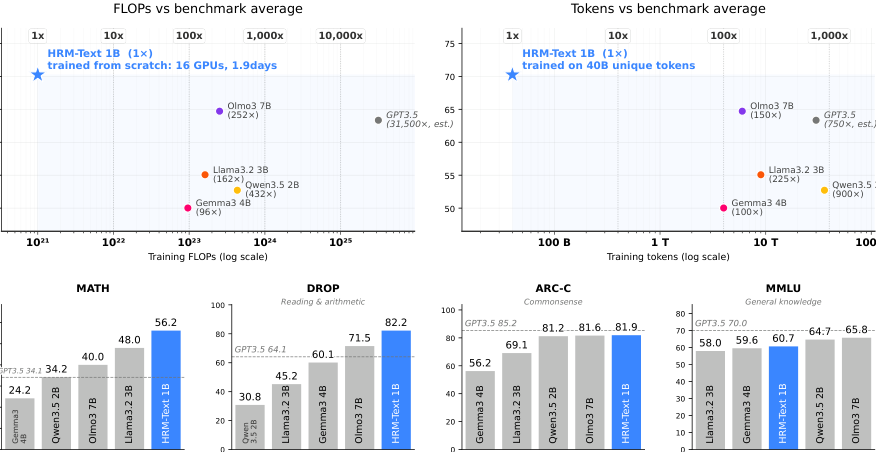
论文声称,这个 1B 模型从零训练只用了 40B unique tokens,总训练约 60B tokens,成本约 1500 美元,在多个 benchmark 上接近或超过一些 2B-7B 开源/开放权重模型:MMLU 60.7、ARC-C 81.9、DROP 82.2、GSM8K 84.5、MATH 56.2。
一句话讲:这不是一篇“又堆大模型”的论文,而是一篇问“预训练是否必须那么贵”的论文。
#1. 它想解决什么问题?
当前 LLM 预训练的默认范式大概是:
- 用海量互联网原始文本做 next-token prediction;
- 用更高质量数据做 mid-training / annealing;
- 再做 instruction tuning、RLHF/RLVR 等后训练;
- 模型和数据越做越大,实验门槛越来越高。
这个范式当然有效,但问题是:它把基础模型研究的入场券变得很贵。 如果一个实验需要几万亿 tokens、几千张 GPU、几百万美元,那大多数小组就很难真正研究“基础模型从零训练”本身,只能研究微调、推理、agent 外壳或小规模 toy setting。
HRM-Text 的问题意识就是:
如果我们不把所有 token 都当成同等重要的 next-token prediction 对象,而是直接训练模型完成任务;如果我们不只靠堆更多层/更多参数,而是让模型在内部反复计算;那么能不能用少得多的 token 和算力,得到一个还不错的基础模型?
这点和你最近关心的“基础模型训练范式”“持续预训练效率”“agent 能力是否来自数据组织和训练目标”是直接相关的。
#2. 方法总览:三件事绑在一起
HRM-Text 不是只有一个 trick,而是三件事一起做:
| 组件 | 它改了什么 | 直观理解 |
|---|---|---|
| HRM 架构 | 用分层递归模块替代标准 Transformer 堆层 | 少放一些不同参数层,但让同一套模块多次思考 |
| MagicNorm + warmup deep credit assignment | 稳定递归语言模型训练 | 前向别爆,反向别炸;先学短信用分配,再逐步放长 |
| Task-completion objective + PrefixLM | 不预测 instruction,只预测 response | 把训练信号集中在“回答问题/完成任务”上,而不是浪费在复述 prompt |
架构图如下:
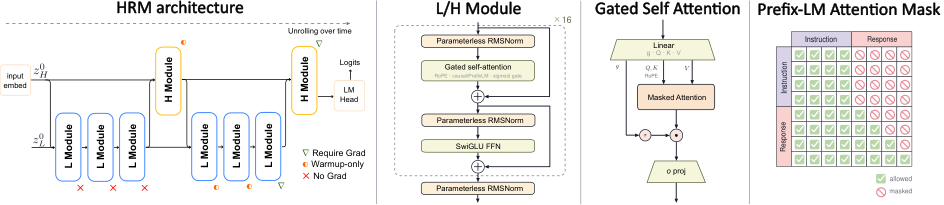
#3. HRM 架构:让模型“多想几步”,但不把参数翻倍
标准 Transformer 的直觉是:第 1 层、第 2 层、……第 N 层,每一层都有自己的参数。想要更深计算,通常要更多层、更多参数、更多训练成本。
HRM 的想法不一样:用递归把同一类模块反复调用,让计算深度增加,但参数量不等比例增加。
这篇论文中的 HRM-Text 有两个时间尺度:
- L module:低层、快速、局部执行模块,像是在做细粒度迭代 refinement;
- H module:高层、慢速、语义/策略模块,像是在维护更稳定的全局上下文。
论文里的 forward pass 大致是:初始化高层状态 和低层状态 ,然后做 2 个高层 H cycle;每个 H cycle 内部先做 3 次 L module 更新,再做 1 次 H module 更新。最后用 H module 的最终状态接 LM head 输出 logits。
人话说:
Transformer 更像“一条固定流水线”;HRM 更像“同一个脑区反复加工,中间有快思考和慢思考的节奏”。
这对 LLM Agent 很有启发:agent 长轨迹问题里,我们经常希望模型不是单次前向就给答案,而是能在内部进行更多计算、规划和状态更新。HRM-Text 至少在架构层面尝试把“多步计算”内化到模型里,而不是全交给外部 chain-of-thought 或 agent loop。
#4. 为什么递归语言模型难训?MagicNorm 和 warmup credit assignment
递归架构的风险也很明显:同一个变换反复作用,前向激活可能越滚越大,反向梯度也可能在长链路里爆掉或消失。
论文在这里用了两个稳定化设计。
#4.1 MagicNorm:同时想要 PreNorm 的梯度流和 PostNorm 的前向稳定
标准 Transformer 里常见两种 normalization 放法:
- PreNorm:先 norm 再进 sublayer,然后残差加回来。优点是梯度路径顺,深网络好训;缺点是 residual 不断累积,隐藏状态方差可能变大。
- PostNorm:残差加完后再 norm。优点是前向激活被约束;缺点是可能破坏 identity gradient path,深层优化不稳定。
MagicNorm 的设计是:模块内部仍然是 PreNorm block,但模块出口再加一个 final normalization。由于递归模块在前向会被调用很多次,出口 norm 能不断约束 recurrent state 的方差;而反向又使用 truncated BPTT,梯度只穿过有限步,因此优化上仍然更像 PreNorm。
人话说:
每次循环结束都“洗一遍状态”,避免状态越滚越野;但反向传播只看最近几步,保留相对好训的梯度路径。
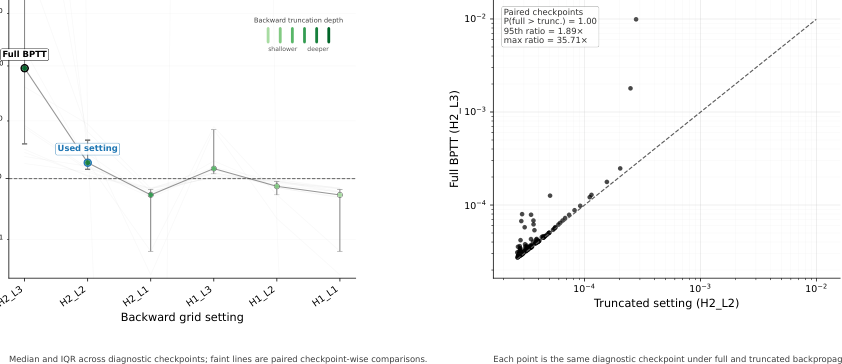
#4.2 Warmup deep credit assignment:先短链路训练,再逐步拉长
原始 HRM 使用固定 1-step gradient strategy,只通过最后两个 recurrent steps 反传。HRM-Text 做了 warmup:早期只通过最后 2 个 recurrent steps 反传,训练稳定后线性增加到最后 5 个 steps。
这有点像 curriculum learning:
一开始不要让模型背负太长的信用分配链条;先让它在短路径上学稳,再逐步让更早的 recurrent computation 也承担训练信号。
论文附录的梯度分析也支持这个动机:full BPTT 相比 truncated setting 更容易出现大梯度事件。
#5. 训练目标:不要预测 prompt,把信号集中到 answer
这篇论文最值得注意的不只是架构,还有训练目标。
传统 next-token pretraining 优化的是:
也就是所有 token 都要预测。对于 instruction-response 数据,这意味着模型既要预测 instruction,也要预测 response。
HRM-Text 改成:给定 instruction ,只预测 answer :
这被称为 task-completion objective。
这个改变的直觉很简单:
模型最终被用来“看懂问题并回答”,不是被用来“复述问题”。那么训练时就应该把 loss 集中在回答部分。
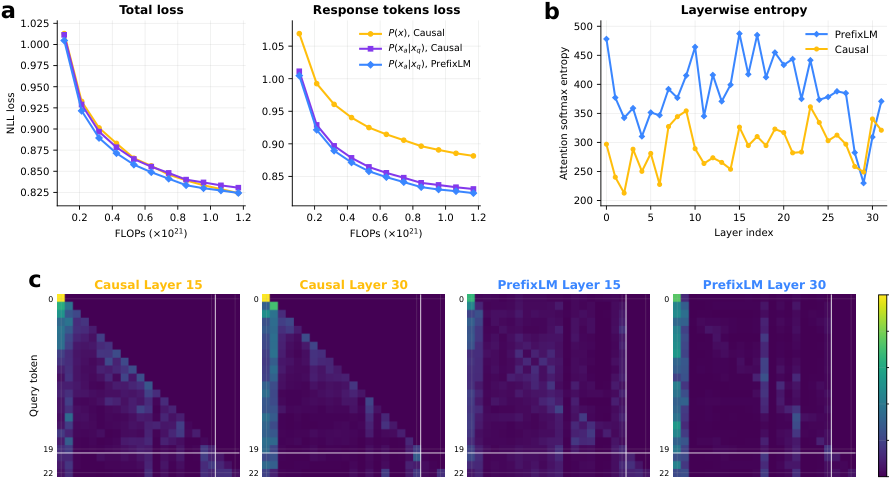
同时,由于 instruction 部分不再需要自回归预测,模型可以对 instruction token 使用 PrefixLM mask:instruction 内部双向可见,response 部分仍然保持 causal generation。
这相当于在 decoder-style 实现里做出一点 encoder-decoder 的味道:
- instruction 段像 encoder context:可以全局整合;
- response 段像 decoder output:仍按自回归生成。
论文的 Figure 3 展示了这个设计确实降低 response-token loss,并让 attention 更全局地利用 prompt。
这对 agent 训练也很重要:如果我们未来想训练 agent,不一定应该把整个轨迹都当作均匀 next-token prediction;更可能需要区分“上下文/任务描述/环境状态”和“需要模型负责生成的行动/答案/计划”。
#6. 实验结果:强在哪里?
#6.1 同等训练 FLOPs 下,HRM 比多个 baseline 更好
论文在 FLOPs-matched setting 下比较了 HRM、Looped Transformer、RINS 和不同大小 Transformer。HRM 1B 在 1.0×10²¹ FLOPs、0.06T tokens 下取得:
| Model | MMLU | ARC-C | DROP | GSM8K | MATH |
|---|---|---|---|---|---|
| HRM 1B | 60.73 | 81.91 | 82.21 | 84.53 | 56.16 |
| Looped Transformer 1B | 56.51 | 74.06 | 76.20 | 75.13 | 48.30 |
| RINS 1B | 56.09 | 76.71 | 79.92 | 77.71 | 48.90 |
| Transformer 1B | 53.15 | 74.32 | 75.30 | 75.06 | 48.36 |
| Transformer 3B Deep | 56.67 | 80.46 | 76.95 | 75.66 | 50.50 |
这里最有意思的是:HRM 1B 不只是比同规模 Transformer 好,甚至在很多 benchmark 上比 FLOPs-matched 的 3B Transformer 还强。
#6.2 objective 和 PrefixLM 各自都有贡献
Table 3 的 ablation 很关键:
| Architecture | Objective | Attention | MMLU | ARC-C | DROP | GSM8K | MATH |
|---|---|---|---|---|---|---|---|
| Transformer 1B | P(x) | Causal | 40.55 | 51.91 | 38.24 | 48.37 | 35.44 |
| Transformer 1B | P(xa⎮xq) | Causal | 47.72 | 62.88 | 54.24 | 69.75 | 47.04 |
| Transformer 1B | P(xa⎮xq) | PrefixLM | 53.15 | 74.32 | 75.30 | 75.06 | 48.36 |
| HRM 1B | P(x) | Causal | 43.68 | 60.24 | 42.74 | 66.19 | 44.32 |
| HRM 1B | P(xa⎮xq) | Causal | 50.60 | 69.80 | 62.39 | 79.91 | 54.18 |
| HRM 1B | P(xa⎮xq) | PrefixLM | 60.73 | 81.91 | 82.21 | 84.53 | 56.16 |
为了避免网站渲染把竖线误认为表格分隔符,上表中的 P(xa⎮xq) 写成了近似形式。核心结论是:response-only objective、PrefixLM、HRM 架构三者都是增益来源,而且叠加后提升最大。
#6.3 和当代开源模型比:不是全面赢,但性价比非常突出
论文把 HRM-Text 1B 和 Llama3.2 3B、Gemma3 4B、Qwen3.5 2B、OLMo3 7B、Ouro 1.4B 等模型比较。结果大致是:
| Model | FLOPs(10²¹) | Tokens(T) | MMLU | ARC-C | DROP | GSM8K | MATH |
|---|---|---|---|---|---|---|---|
| HRM-Text 1B | 1 | 0.06 | 60.7 | 81.9 | 82.2 | 84.5 | 56.2 |
| OLMo3 7B | 252 | 6 | 65.8 | 81.6 | 71.5 | 75.5 | 40.0 |
| Llama3.2 3B | 162 | 9 | 58.0 | 69.1 | 45.2 | 77.7 | 48.0 |
| Gemma3 4B | 96 | 4 | 59.6 | 56.2 | 60.1 | 38.4 | 24.2 |
| Qwen3.5 2B | 432 | 36 | 64.5 | 81.0 | 30.8 | 53.0 | 34.2 |
| Ouro 1.4B | 259 | 7 | 67.4 | 60.9 | 49.7 | 78.9 | 22.4 |
它并不是所有指标都赢,例如 MMLU 仍不如 OLMo3、Qwen3.5、Ouro,这很可能和知识覆盖、数据广度、模型规模有关。但在 MATH、DROP、GSM8K 等更偏推理/任务执行的 benchmark 上,它非常强。
论文自己的解释也比较克制:HRM-Text 可能更像一个 compact reasoning / task-execution core,而不是一个拥有最大知识覆盖的百科型模型。
#7. 有效深度:HRM 到底是不是真的“多算了”?
递归模型经常有一个问题:看起来调用了很多次模块,但会不会后面几次其实没什么新东西,只是在重复/平滑?
论文用了两个分析回答这个问题。
#7.1 隐状态变化和 cosine similarity
Figure 4 看相邻 recurrent blocks 的隐藏状态变化,以及不同层表示之间的 cosine similarity。HRM 的层间变化更大、块之间相似度更低,说明它的深层仍然在做有意义的更新;相比之下,Looped Transformer 和 RINS 更容易出现 representation over-smoothing。
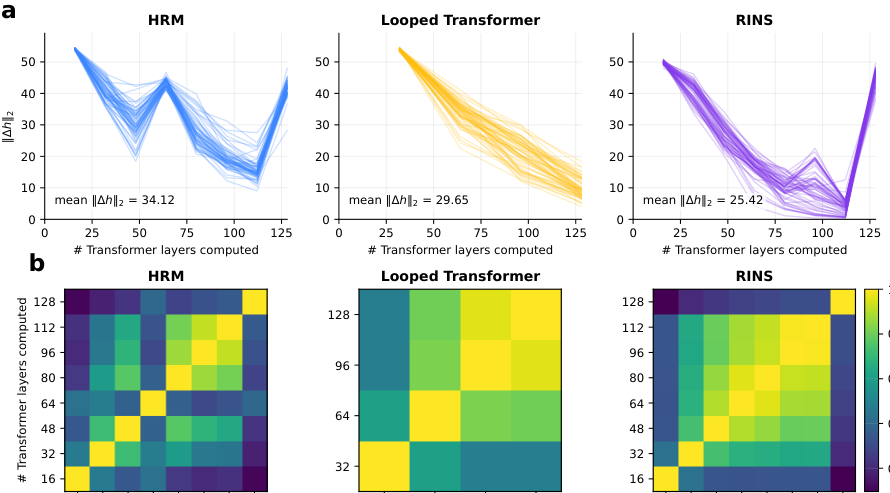
#7.2 Logit lens KL
Figure 5 用 logit lens 看中间层预测分布和最终输出分布的 KL divergence。标准 Transformer 和 looped Transformer 比较早就收敛到接近最终分布;HRM 在更深层仍保持较高 KL,说明后续层调用仍在实质改变模型预测。
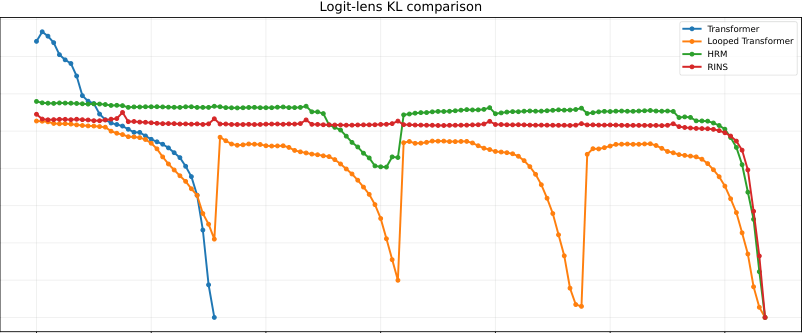
这部分对“潜空间推理 / latent-space reasoning”也有启发:如果一个模型在内部 recurrent state 上持续更新,而且这些更新能改变最终输出分布,那么它就更像是在 latent space 中做多步计算,而不只是一次性映射。
#8. 数据:它不是 raw web pretraining,而是任务格式化混合数据
HRM-Text 只使用开源数据,初始语料约 176.5B tokens、593.7M documents,类型包括:
- General instructions:FLAN、Tasksource、NoRobots;
- Rewritten Wikipedia knowledge:SYNTH;
- Math and reasoning:Platypus、Principia、OpenMathInstruct2、NuminaMath、OmniMATH;
- Symbolic:DMMath、AMPS、Sudoku-Extreme;
- Reasoning 数据:AceReason、OpenThoughts2,但移除了
<think>...</think>; - Textbook exercises;
- Extracted web instructions:NaturalReasoning、WebInstruct-verified、AMPS-khan。
最终采样 40B unique tokens,训练总 token 数约 60B。它还给不同数据加 condition tags,比如 direct、cot、synth、noisy,用来控制输出风格。
这里有一个重要判断:
这篇论文不是证明“任何 40B tokens 都够了”,而是证明“高度任务化、格式化、目标明确的数据 + 架构/目标协同”可以显著提高小预算预训练的产出。
这和 agent 预训练数据也很像:真正关键的可能不是轨迹越多越好,而是轨迹如何被格式化、哪些部分算 loss、模型要从环境交互里学到什么。
#9. 我怎么看这篇论文的价值和风险?
#9.1 价值:它把“预训练研究”从 scaling dogma 中撬开了一条缝
我觉得这篇论文最值得关注的地方不是某个单点指标,而是它提出了一个强命题:
预训练效率不只是 scaling law 的函数,也强烈依赖 architecture、objective、data format 的共同设计。
如果这个方向成立,那么小团队也可以重新参与“基础模型训练范式”的研究,而不是只能在大厂 release 的 checkpoint 上做二次开发。
#9.2 风险一:benchmark 可能更偏任务化,知识覆盖仍然有限
HRM-Text 的数据本身高度 instruction / reasoning / task formatted,因此在 MATH、GSM8K、DROP 上强是合理的;但 MMLU 这类更依赖广泛知识覆盖的指标没有压倒性优势。
所以不能把它解读成“40B tokens 就能训练通用强模型”。更准确的说法是:
40B carefully formatted task tokens + recurrent architecture,可以训练出一个强 task-execution / reasoning-oriented 小模型。
#9.3 风险二:对更大规模是否成立还未知
论文的 HRM-Text 主要到 1B,Transformer 对比到 3B。它没有证明这个方法在 7B、30B、100B 规模仍然同样高效。递归架构的训练稳定性、硬件效率、并行性、推理延迟,也都可能在更大规模遇到新问题。
#9.4 风险三:和标准 Transformer 的工程生态有距离
Transformer 的优势不只是效果,还有极强的工程生态:kernel、并行策略、KV cache、推理服务、量化工具都成熟。HRM 这种 recurrent computation 是否能在真实服务中取得端到端优势,还需要更多系统层面的验证。
#10. 对 LLM Agent / 长轨迹 RL 的启发
这篇论文对你的几个方向有直接启发。
#10.1 Agent 模型可能需要“内部计算深度”,而不是只靠外部轨迹展开
长轨迹 Agent RL 的一个问题是:如果所有信用分配都发生在外部 token/action 轨迹上,训练会非常长、噪声很大、成本很高。HRM-Text 给出的另一种可能是:
把一部分“多步思考”压进模型的 recurrent latent computation 里,让模型在一次生成前内部多算几步。
这和 latent-space reasoning 是同一条线。
#10.2 训练目标要更像“任务完成”,而不是盲目模仿所有 token
Agent 轨迹里有观察、思考、动作、工具返回、错误恢复、最终答案。也许不是所有 token 都应该等权 loss。HRM-Text 的 response-only objective 提醒我们:训练时应明确“哪些 token 是上下文,哪些 token 是模型真正要负责优化的行为”。
#10.3 小预算基础模型训练仍值得做
如果 HRM-Text 的结论能复现,那么“从零训练一个有特定 inductive bias 的小模型”可能再次变成可行研究路径。对 model-based RL / Dreamer for LLM Agent 来说,这很关键:我们不一定只能拿现成 Transformer 做 RL,也可以探索更适合世界模型、规划、递归计算的架构。
#11. 最后总结
HRM-Text 的核心不是“我又训练了一个 1B 模型”,而是:
- 架构上:用 H/L 分层递归增加有效计算深度;
- 稳定性上:用 MagicNorm 和 warmup deep credit assignment 让递归语言模型可训;
- 目标上:用 task-completion objective 和 PrefixLM 把训练信号集中到 response;
- 数据上:用任务格式化数据,而不是传统 raw web text;
- 结果上:在 40B unique tokens / 约 1500 美元预算下,让 1B 模型进入 2B-7B 开源模型的性能区间。
我对它的判断是:这是一篇值得跟踪、也值得复现的“训练范式论文”。 它不一定已经证明 scaling 不重要,但它确实说明:在小预算预训练场景下,architecture + objective + data format 的协同设计,可能比单纯堆 tokens 更重要。
如果后续要继续挖,可以重点看三个问题:
- HRM-Text 的结果能否被独立复现?
- 这个 recurrent architecture 能否扩展到更大模型,并保持训练/推理效率?
- task-completion objective + PrefixLM 能否迁移到 agent trajectory pretraining,尤其是长轨迹、多工具、多轮环境交互数据?