#ExpRL:把参考答案从 SFT 样本变成 RL 探索脚手架
论文:ExpRL: Exploratory RL for LLM Mid-Training
作者:Violet Xiang, Amrith Setlur, Chase Blagden, Nick Haber, Aviral Kumar
机构:Stanford University, Carnegie Mellon University, OpenAI
arXiv:<https://arxiv.org/abs/2606.17024>
代码:<https://github.com/violetxi/ExpRL>
#0. 一句话 thesis
这篇论文想解决的问题很直接:当一个基础模型在难题上几乎采不到正确轨迹时,直接做 sparse reward RL/GRPO 往往没有足够学习信号;但如果我们手里有很多人类参考解答,不一定要拿它们做 SFT 模仿,而可以把它们变成“奖励脚手架”,用 LLM judge 给模型自己的 on-policy 推理轨迹打 dense reward,从而提前扩大模型能探索到的有效解法覆盖。
用更人话说:
- 传统 SFT:把参考答案当作“标准作文”,让模型照着写。
- sparse RL:只看最后答案对不对,对了给 1,错了给 0。
- ExpRL:参考答案不给模型看,也不让模型照抄;只给裁判看,让裁判判断模型自己的尝试“走到了哪一步”“有没有朝正确方向推进”。
所以 ExpRL 的关键不是“参考解答更强”,而是:参考解答被重新定位成 RL 探索阶段的 reward scaffold,而不是 imitation target。

#1. 为什么这篇论文重要?
最近 LLM reasoning 的主流后训练路径大致是:
- 先有一个 base / instruct model。
- 用 SFT、long-CoT 数据、探索数据或 mid-training 提升推理行为。
- 再用可验证奖励做 RL,比如数学题 final answer 对不对,代码题 unit test 过不过。
这条路线的问题是:RL 不是从零创造能力,它非常依赖初始策略分布里已经有多少“可被奖励捕获”的轨迹。
如果模型在某类难题上 64 次采样都答不对,那么 final-answer reward 基本就是一串 0。此时 GRPO/PPO 再优雅,也很难知道:
- 哪个中间分解是有用的?
- 哪个 case split 虽然最后失败但方向正确?
- 哪次自我纠错其实把模型拉回了正轨?
- 哪条轨迹离最终解法只差最后一步?
ExpRL 站在一个很关键的位置:它把问题从“如何设计更好的最终奖励”转成“如何在 sparse RL 之前,把模型的探索覆盖先推到一个可学习区域”。
这和近期很多现象是连在一起的:
RLVR成功依赖 base model 已经能采到少量正确样本。GRPO类方法减少 critic 负担,但仍逃不开稀疏奖励下的 exploration bottleneck。SFT能注入轨迹,但 off-policy imitation 可能让模型学到不自然分布,甚至削弱原有推理能力。- 长轨迹 Agent RL 更严重:最终成败可能来自很早的规划、检索、工具调用或分支选择,纯终局奖励更稀疏。
因此这篇论文的价值在于提出了一个可复用范式:用 reference-conditioned judge 为 on-policy trajectories 提供 dense feedback。
#2. 核心问题:coverage,而不是单点正确率
论文反复强调一个词:coverage over productive reasoning paths。
这里的 coverage 不是数据覆盖率,而是策略分布覆盖率。它指的是:模型当前采样分布里,是否给“可能通向正确解法的轨迹”分配了足够概率质量。
可以这样理解:
| 概念 | 人话解释 | 对 RL 的意义 |
|---|---|---|
pass@1 | 随机采一次就答对的概率 | 衡量单次可靠性 |
pass@k | 采 k 次里至少一次答对的概率 | 衡量策略分布里有没有正确轨迹 |
| coverage | 模型是否覆盖了足够多有效解法路径 | 决定后续 sparse RL 有没有东西可强化 |
| mid-training | sparse RL 前的中间训练阶段 | 先把模型推到“能探索”的区域 |
为什么 pass@k 很重要?
因为如果 pass@1 不高但 pass@k 提升,说明模型不是每次都稳,但它的采样空间里已经出现了更多可行路径。对于后续 RL 来说,这非常关键:只要模型偶尔能采到有价值轨迹,final-answer reward 才开始有信号。
这也是 ExpRL 和普通 SFT 的区别:SFT 更像把模型推向某些标准答案轨迹;ExpRL 更像改变模型的探索分布,让它自己更容易采到有希望的路径。
#3. 方法:参考答案只给裁判,不给选手
ExpRL 的设定是:有一个 mid-training 数据集
D_mid = {(x_i, y_i*)}
其中:
x_i是问题。y_i*是人类写的 step-by-step 参考解答。- policy
πθ只看到原始问题x_i。 - LLM judge 同时看到问题、policy 生成的解答
y、参考解答y_i*。
关键点:policy 不看参考解答。
这使 ExpRL 避免了两种常见问题:
- SFT 的 off-policy mismatch:人类参考解法可能和模型自然推理分布差很远,硬模仿会扰动模型。
- oracle prefix / hint 泄露:如果训练时给模型看参考前缀,模型可能学的是依赖提示,而不是自己探索。
ExpRL 的流程是:
- policy 从原始问题
x采样多个 rollout。 - LLM judge 对每个 rollout 和参考解答做比较。
- judge 给出 1–5 分,再归一化到
[0,1]。 - 用这个 dense reward 做 on-policy RL。
- 得到一个更适合后续 sparse RL 的初始化。
论文里有两个主要变体。
#3.1 ExpRL-Outcome:给完整轨迹一个 dense outcome 分
普通 sparse reward 是:
- 答案对:1
- 答案错:0
ExpRL-Outcome 则是:即使最终答案错了,也让 judge 判断这条完整推理轨迹和参考解法有多少有效重合。
比如:
- 找到了正确变量替换,但后面算错了:可能给 0.5。
- 做了正确 case split,但漏了一个 case:可能给 0.6。
- 完全乱猜:接近 0。
- 走完正确证明:接近 1。
它解决的是“错解之间没有区别”的问题。
#3.2 ExpRL-Process:给中间 prefix 也打分
Outcome 级 dense reward 仍然有一个问题:它只给完整输出一个分数,不能告诉模型是哪一步贡献了进展。
所以 ExpRL-Process 会把 rollout 切成多个 prefix。论文里主要用模型自然生成的 ### delimiter 来切分 reasoning step,然后对每个 prefix 打分:
score_t = s(x, y_≤t, y*)
接着把 prefix 分数变成 segment-level advantage。核心直觉是:
- 如果某一步让 prefix 更接近参考解法,它应该拿正 advantage。
- 如果某一步让推理偏离正确路径,它应该拿负 advantage。
- 不奖励“看起来长但没有推进”的内容。
这比 outcome reward 更接近长轨迹 credit assignment。
不过论文也承认,这里有工程细节:prefix 切分、长度裁剪、reward normalization 都会影响稳定性。附录里专门分析了 process reward normalization 和 delimiter collapse。
#4. ExpRL 和 SFT / GRPO / self-distillation 的区别
可以用一张表概括:
| 方法 | 参考解答怎么用 | policy 生成是否 on-policy | 学习信号密度 | 主要风险 |
|---|---|---|---|---|
| SFT | 当作目标轨迹模仿 | 否 | token-level dense | off-policy,可能破坏模型自然推理分布 |
| sparse GRPO | 不用参考解答,只看最终答案 | 是 | 极稀疏 | 难题上大多 reward=0,探索不足 |
| self-distillation | 用参考条件下的 teacher 产生监督 | 部分缓解 | token-level | teacher 分布可能离 student 太远 |
| ExpRL-Outcome | 给 judge 作评分参照 | 是 | rollout-level dense | judge 偏差、参考质量依赖 |
| ExpRL-Process | 给 judge 作 prefix 评分参照 | 是 | prefix/segment-level dense | 切分、长度、校准更复杂 |
这篇论文最有意思的判断是:reference solution 不一定适合被模仿,但很适合被用来验证。
原因是现代 LLM 经常存在 verification-generation gap:让它从零解一道难题很难,但让它对照参考解答判断某个尝试有没有部分进展,相对容易。
这和人类学习也很像:老师不一定要把完整答案塞给学生背,而是可以拿标准解法作为 rubric,评价学生自己的草稿哪里对、哪里偏、哪里值得继续。
#5. 实验设置:先做 RL priming,再做 sparse RL
论文的实验是两阶段:
#Stage-I:RL priming / mid-training
- policy:
Qwen3-4B-Instruct-2507。 - judge:主实验用同一个
Qwen3-4B-Instruct的拷贝。 - 数据:来自 InT 和 POPE 的 hard question + reference answer pairs。
- 选择难题:base model 在 64 次独立采样、每次 32k token budget 下都解不出来的问题。
- 训练:ExpRL stage 训练 230 optimization steps。
- 采样:每个 prompt 采
G=10个 rollout,temperature 0.8,最大生成长度 16,384 tokens。
#Stage-II:downstream sparse-reward RL
- 从不同 Stage-I 初始化出发。
- 全部使用相同的 sparse final-answer reward。
- 训练 500 optimization steps。
- 评测:HMMT Nov 2025、IMO-AnswerBench、AIME 2025、AIME 2026。
- 每题采样 128 个 response 计算指标。
这个实验设计的关键是:Stage-II 的 RL 设置不变,只改变 Stage-I 初始化。这样可以回答:ExpRL 是不是给后续 sparse RL 提供了更好的 starting point?
#6. 主结果:ExpRL 让后续 sparse RL 更强
主结果在 Table 1:经过 Stage-II sparse-reward RL 后,ExpRL 初始化整体优于 SFT、sparse GRPO 和 self-distillation。
关键数字:
| Stage-I 初始化 | AIME25 | AIME26 | HMMT | IMO Answer |
|---|---|---|---|---|
| Qwen3-4B-Instruct | 46.46 | 51.40 | 40.60 | 31.37 |
| SFT | 26.62 | 30.26 | 20.09 | 21.80 |
| GRPO | 55.99 | 58.75 | 42.91 | 35.28 |
| Self-Distillation | 55.59 | 58.41 | 46.08 | 35.18 |
| ExpRL-Outcome | 59.07 | 61.74 | 49.11 | 37.85 |
| ExpRL-Process | 58.08 | 63.41 | 48.13 | 35.73 |
几个观察:
- SFT 非常差。 这支持论文关于 off-policy imitation 的担忧:人类参考解法不一定适合直接模仿。
- GRPO 有提升,但不如 ExpRL。 sparse RL 可以强化已有正确轨迹,但在 hard problems 上探索还是受限。
- ExpRL-Outcome 和 ExpRL-Process 都有效。 Outcome 在多个指标上最强,Process 在 AIME26 上最好。
- 提升不是只发生在 Stage-I reward 上。 因为这些分数是 Stage-II sparse RL 后的 held-out benchmark 表现。

#7. ExpRL 在 Stage-I 后已经改善探索分布
论文还看了 Stage-I 结束、还没跑 downstream RL 时的 pass@1 和 pass@16。结果显示 ExpRL 本身已经让模型变强,尤其在 AIME26 和 HMMT 上明显。
Stage-I 后的 Table 2 里:
- AIME26 pass@1:base 51.45,ExpRL-Outcome 57.45,ExpRL-Process 57.51。
- HMMT pass@1:base 40.60,ExpRL-Outcome 44.19,ExpRL-Process 45.24。
- HMMT pass@16:base 68.43,ExpRL-Process 71.48。
这支持一个很重要的解释:ExpRL 不是只让模型“更会讨好 judge”,而是确实改变了采样分布,让模型更容易采到可行解。
Figure 3 进一步展示训练动态:
- sparse GRPO 的 token-level entropy 下降更快,更像 mode-seeking。
- ExpRL 和 self-distillation 保持更高 entropy。
- ExpRL-Process 更快减少 unsolvable prompts。
- ExpRL-Process 的 response length 会增长,说明过程奖励可能鼓励更长推理,但也需要长度控制。
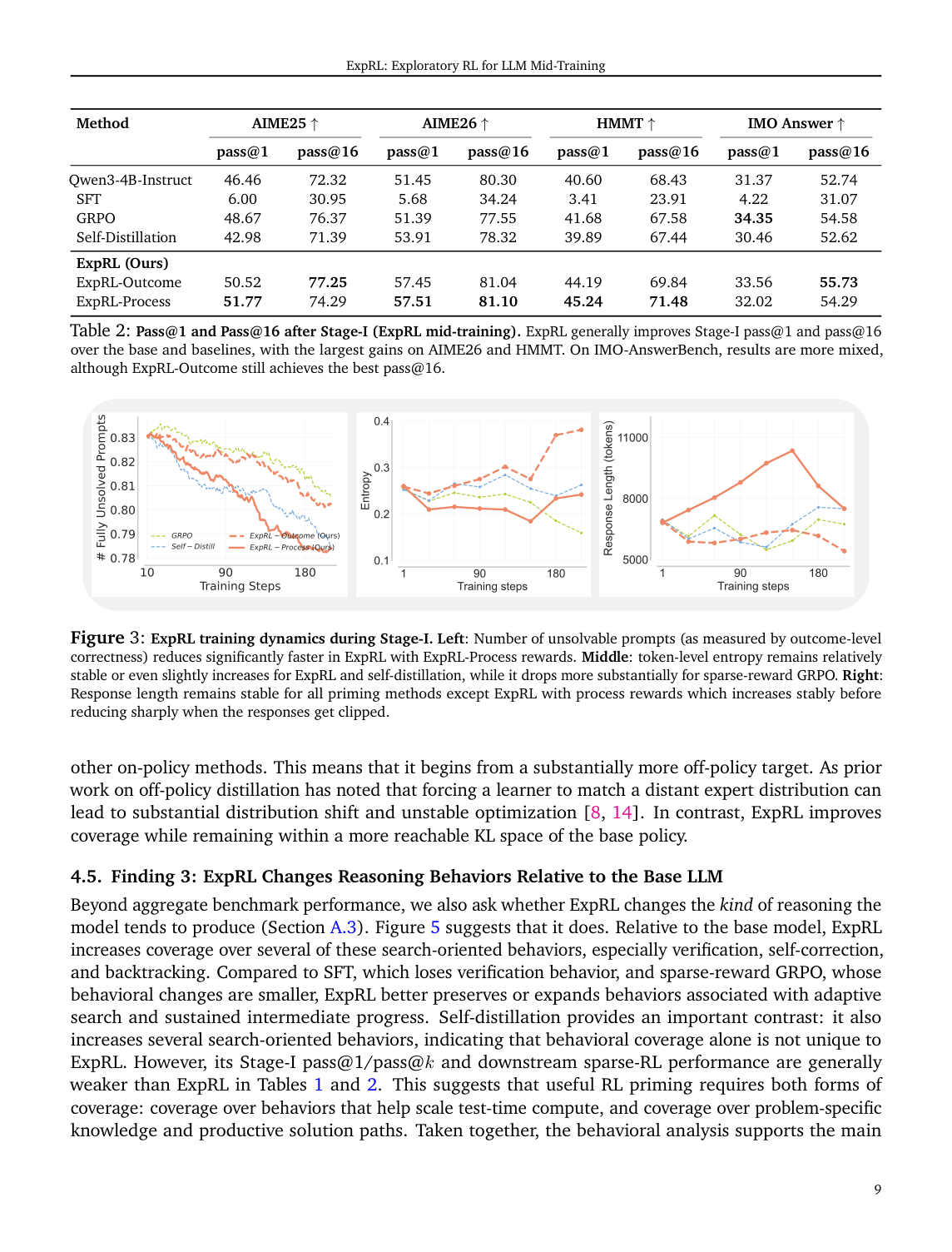
#8. 模型到底学到了什么?更多搜索型 reasoning behavior
论文不只看分数,还用一个 annotation rubric 分析模型推理行为变化。
他们关注的行为包括:
- verification:推导完后回代验证。
- self-correction:明确修正前面的错误。
- backtracking:回到某个分叉点尝试另一条路。
- exploration:提出不同策略。
- restart:放弃已有路线重新开始。
- structured steps:显式分步骤。
Figure 5 显示,ExpRL 相对 base 增加了多种 search-oriented behaviors,尤其是 verification、self-correction、backtracking 等。
这很重要,因为它说明 ExpRL 不只是提升 final correctness,而是让模型更倾向于产生“可搜索、可修正、可继续推进”的推理轨迹。
不过这里也要谨慎:self-distillation 也能增加部分搜索行为,但它的最终效果不如 ExpRL。因此论文的解释是:有搜索行为还不够,还要有 problem-specific productive path coverage。
换句话说,会自我纠错是一种 primitive skill;但在具体难题上知道往哪里纠错、怎么组合技巧,才是 coverage。
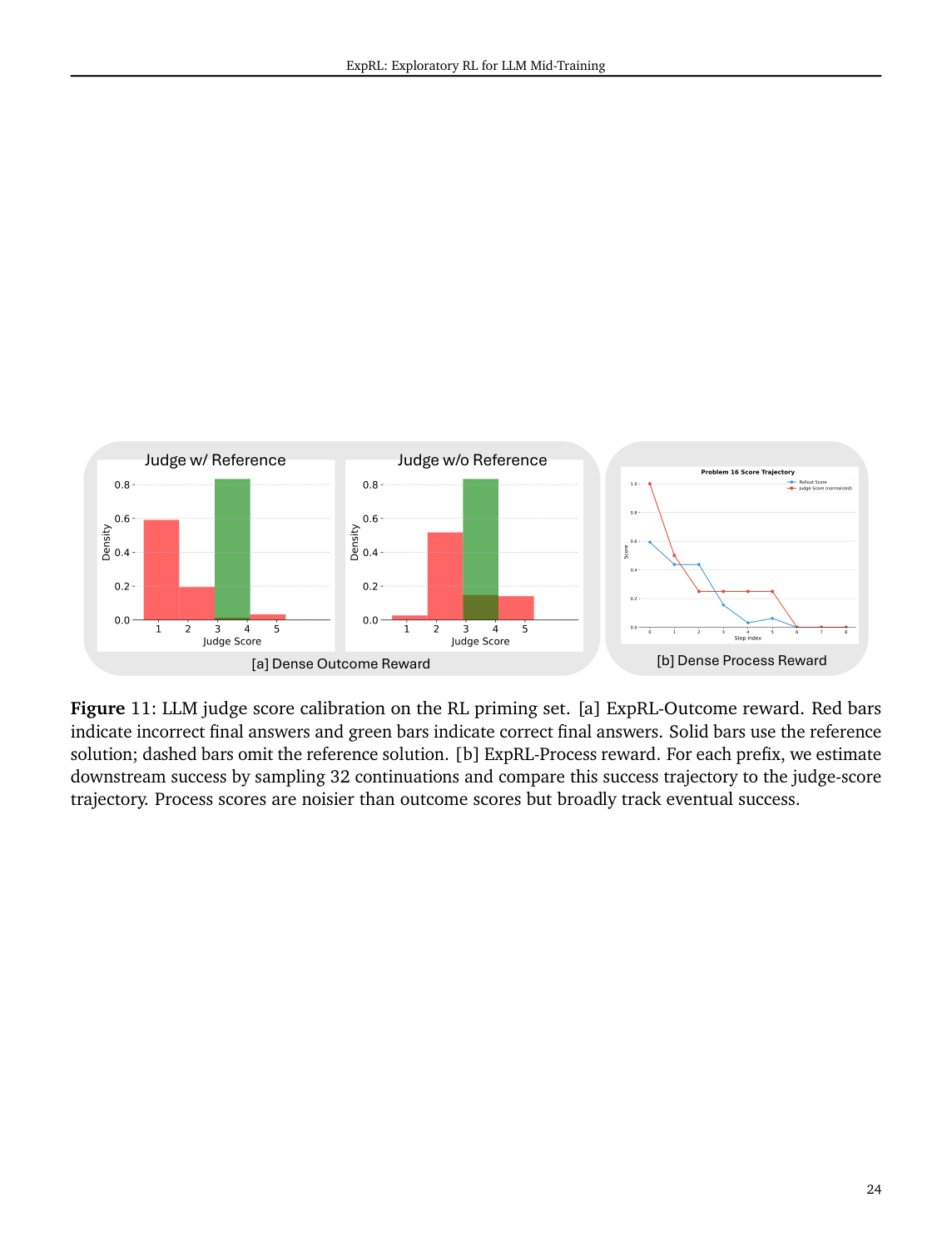
#9. LLM judge 可靠吗?reference 很关键,但 judge 也有门槛
ExpRL 的一大潜在质疑是:LLM judge 会不会只是在凭感觉打分?reference solution 真的有用吗?
论文做了 calibration stress test:固定 sampled rollouts,改变 judge 条件:
- 给正确 problem-matched reference。
- 不给 reference。
- 给错误 reference。
并衡量 misplacement rate:
- false positive:错解被打高分。
- false negative:对解被打低分。
- 两者平均越低越好。
结果:
- 在 Math、SciKnow-MCQ、SciKnow-OE 上,4B/8B/14B judge 都是 correct reference 最好。
- wrong reference 会明显破坏判断。
- 0.6B judge 不稳定,说明 judge 不能太弱。
- 在 coding 上,reference 的作用不明显,因为 execution / functional correctness 本身已经很强。
这给 ExpRL 的适用边界画得比较清楚:
- 对数学、科学问答这类“中间推理路径可比较”的任务,reference-conditioned judge 有价值。
- 对代码这类能直接执行验证的任务,reference scaffold 不一定比环境 reward 更强。
- judge 不必和 policy 一样大,但必须达到基本验证能力。
Figure 11 也说明:
- Outcome reward 加 reference 后,正确/错误答案的 score 分布区分更明显。
- Process reward 更噪,但总体能跟随 downstream success trajectory。
#10. 混合领域实验:数学之外也能用,但代码不一定最适合
论文还做了一个更广的 mixed-domain Stage-I 实验:
- policy:Qwen3-8B。
- judge:Qwen3-4B-Instruct。
- 数据:4001 个 reference-solution examples。
- 领域:math、science QA、coding。
数据构成:
| 数据集 | 领域 | 数量 | 占比 |
|---|---|---|---|
| InT | Math | 440 | 11.00% |
| POPE | Math | 1,076 | 26.89% |
| SciKnow-Physics | Science | 474 | 11.85% |
| SciKnow-All | Science | 1,000 | 24.99% |
| LCB v6 | Coding | 1,011 | 25.27% |
| Total | - | 4,001 | 100.00% |
结果显示:ExpRL-Outcome 改善了 8B base policy 在每个 pass@1 evaluation 上的表现,并在 Math-Aggregate 和 STEM-Aggregate 上最好。
但 coding 是例外:ExpRL 对 LiveCodeBench 有提升,但 sparse GRPO 更强。论文解释也合理:代码任务有 execution reward,很多正确实现和参考代码差异很大,reference scaffold 反而不是最自然的信号。
这对 Agent RL 很有启发:如果环境能给强反馈,就直接用环境;如果环境反馈稀疏、不可微、难以局部归因,reference scaffold 或 judge scaffold 才更有价值。
#11. 和最近 RL 方法的关系
可以把 ExpRL 放在一个更大的谱系里看。
#11.1 和 GRPO / PPO 的关系
ExpRL 不是要替代 GRPO 或 PPO,而是改变它们开始训练前的初始化。
- Stage-I:用 reference-guided dense reward 做 RL priming。
- Stage-II:仍然可以用 sparse reward GRPO/PPO。
这说明 ExpRL 更像一个 RL 前置探索扩展器,不是完整后训练 pipeline 的终点。
在实现上:
- ExpRL-Outcome 使用 GRPO-style normalized reward update。
- ExpRL-Process 使用 REINFORCE-style token/segment advantages,不做 group normalization。
因此它和前面讨论的 PPO/GRPO 系列并不是竞争关系,而是补充关系:先用 ExpRL 把 coverage 做起来,再用可验证 sparse RL 放大最终正确性。
#11.2 和 SFT 的关系
ExpRL 对 SFT 的批评很明确:参考答案分布可能离模型自己的推理分布太远。
如果模型本来不会某种高阶解法,直接 SFT 会让它在 token 层模仿一个 off-policy trajectory,但不一定学会如何从自己的状态自然走到那里。更糟糕的是,SFT 在主实验里明显拉低了表现。
这不是说 SFT 没用,而是说:对于 hard reasoning mid-training,reference solution 更适合做 verifier/rubric,而不一定适合做 imitation target。
#11.3 和 POPE / oracle prefix 的关系
POPE 这类方法会在 downstream RL 中暴露 privileged prefix,引导模型探索 hard problems。
ExpRL 的区别是:
- 不在 rollout 时给 oracle prefix。
- reference 只在 mid-training reward construction 阶段使用。
- policy 始终从原始 prompt 自己采样。
论文也说两者原则上可以结合:ExpRL 做 priming,POPE 类方法做后续 prefix-guided exploration。
#11.4 和长轨迹 Agent RL 的关系
虽然论文主要做数学推理,但它对 Agent RL 的启发很直接。
长轨迹 Agent 的 reward 问题更严重:
- 任务可能几十步后才成功或失败。
- 工具调用、搜索、规划、回滚都可能影响最终结果。
- 只有最终 reward 时,credit assignment 极难。
- 直接模仿专家轨迹又容易 off-policy,因为 Agent 运行环境动态变化,专家路径未必是当前 policy 能自然到达的路径。
ExpRL 给出一种中间路线:
- 收集专家/人类/强模型完成任务的 reference trajectory 或 solution sketch。
- 不让当前 policy 直接模仿它。
- 让 judge 根据 reference 判断当前 policy 的 on-policy trajectory 是否实现了关键子目标、是否做了有效检索、是否完成了必要验证。
- 用 dense reward 或 process reward 更新当前 policy。
这非常接近长轨迹 Agent 所需要的“分阶段 credit assignment”。
#12. 我怎么看这篇论文
我觉得这篇论文最值得记住的不是某个具体数字,而是一个范式转变:
Reference data 不只有“拿来模仿”这一种用法。它还可以被用来构造奖励、rubric、judge scaffold,从而服务 on-policy exploration。
这件事对 LLM 后训练很关键,因为越来越多任务处在一个尴尬区间:
- 有人类解答或专家轨迹。
- 但直接 imitation 会带来 off-policy mismatch。
- 最终奖励又太稀疏。
- 模型需要先学会探索到有希望的区域。
ExpRL 正好切进这个区间。
它背后的判断和用户最近关注的几条线也很一致:
- 长轨迹 RL 不只是优化算法问题,而是状态覆盖和探索分布问题。
- mid-training / continual pretraining / RL priming 可能比直接在超长轨迹上做终局 RL 更现实。
- model-based 或 latent-state 方法若要用于 Agent,也需要类似的“中间状态可评价”机制。
- 参考轨迹的价值不一定是 token-level imitation,而是把隐含的任务结构变成可学习 reward。
如果往 Agent 方向延伸,我会关注几个问题:
- reference trajectory 怎么抽象成 rubric? 不能只比较文本相似度,而要比较子目标达成、信息获取、状态转换。
- process reward 如何避免奖励 hacking? Agent 可能学会写看似合理的中间步骤,而没有真实推进环境状态。
- judge 是否需要访问环境状态? 对工具使用任务,仅看文本轨迹可能不够,需要结合 observation、tool result、文件 diff、测试结果。
- ExpRL 能否和 world model / latent reasoning 结合? reference 可以帮助 judge 识别 latent subgoal,而不是只识别表面步骤。
- 如何构造大规模 reference 数据? 人类专家轨迹贵,强模型自生成轨迹可能有偏,环境 replay 或失败轨迹标注可能更关键。
#13. 局限与风险
论文自己也提到了一些局限,我觉得主要有五点。
#13.1 依赖 reference solution
ExpRL 需要问题匹配的参考解答。没有 reference,就很难构造这种 scaffold。
这限制了它在开放式任务中的使用。比如科研探索、长程项目管理、开放世界 Agent,很难说存在唯一参考路径。
#13.2 judge 质量决定 reward 质量
实验显示 0.6B judge 不稳定,wrong reference 会让 reward 失真。
这说明 ExpRL 不是“随便找个 LLM 打分就行”。它需要:
- reference 正确且匹配问题。
- judge 足够会验证。
- rubric 明确约束 judge 不要脑补缺失步骤。
#13.3 process reward 更接近 credit assignment,但更难工程化
Process reward 听起来很美,但 prefix 切分、长度增长、delimiter collapse、normalization 都是问题。
尤其长轨迹任务里,什么叫一个“step”并不天然清楚。数学里可以用 ###,Agent 里可能要按 tool call、state transition、subgoal boundary 来切。
#13.4 对代码任务,reference scaffold 未必胜过环境反馈
LiveCodeBench 的结果提醒我们:如果环境已经能提供强验证信号,比如执行测试,reference-conditioned judge 未必是最优。
所以 ExpRL 更适合“最终反馈稀疏、但中间过程可由参考解答辅助判断”的任务。
#13.5 可能学到“像参考解法”的局部模式,而不是真正探索
虽然 ExpRL 不直接给 policy 看参考答案,但 reward 仍然来自和参考解法的 alignment。若 reference 解法单一,模型可能被奖励牵引到某些路径风格,而不是发现全新解法。
这需要未来通过多参考、多样化 rubric、环境验证和反事实 judge 来缓解。
#14. 最后总结
ExpRL 可以被概括为一句话:
用参考解答帮助裁判打 dense reward,而不是让模型模仿参考解答。
它解决的是 sparse RL 前的 exploration coverage bottleneck:当 base model 在难题上采不到正确轨迹时,单纯 final-answer reward 太稀疏;SFT 又可能 off-policy。ExpRL 通过 reference-guided judge 给 on-policy rollout 的部分进展打分,让模型在 mid-training 阶段先学会探索到更有希望的解法区域。
对我来说,这篇论文最值得继续追的是它对长轨迹 Agent RL 的启发:未来 Agent 后训练可能不应该只问“最终任务成了吗”,也不应该只做专家轨迹模仿,而应该把专家轨迹、参考解、环境 replay 转化成 state-aware / process-aware / reference-conditioned reward scaffold,让 on-policy Agent 在自己的轨迹分布里学会更有效地探索。
如果把这件事做成一条研究线,ExpRL 可以看作一个很清楚的起点:从 sparse outcome RL 走向 reference-guided exploratory RL。