#ECHO:Terminal Agents 如何“免费”学到世界模型
论文:ECHO: Terminal Agents Learn World Models for Free
作者:Vaishnavi Shrivastava, Piero Kauffmann, Ahmed Awadallah, Dimitris Papailiopoulos
机构:Microsoft Research
arXiv:2605.24517
时间:2026-05-23
#0. 一句话总结
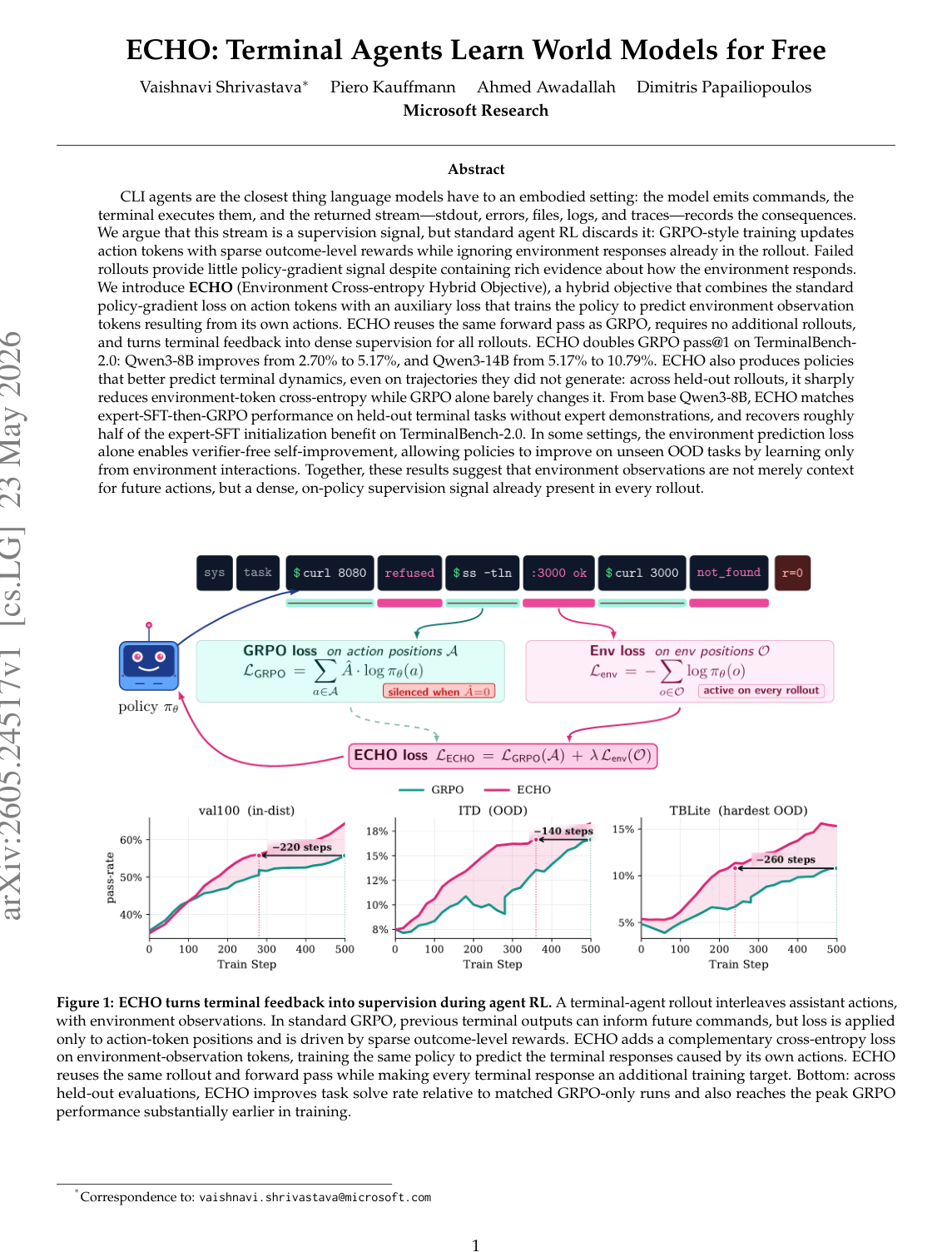
这篇论文的核心观点很直接:terminal agent 的 rollout 里,本来就包含一个被浪费掉的 dense supervision signal——终端环境返回的 stdout、stderr、文件内容、报错日志、测试输出等 observation tokens。
传统 GRPO / agent RL 通常只在模型自己的 action tokens 上做 policy-gradient 更新,并用最终任务成功/失败作为稀疏奖励;而 ECHO 额外要求模型去预测“自己执行某条命令后,终端会返回什么”。这样,失败轨迹也不再只是负样本或零信号,而变成了学习 terminal dynamics 的材料。
更人话一点:
以前训练 terminal agent,只问它“最后任务做成了吗?”;
ECHO 还问它:“你刚才运行这条命令,终端为什么会这样回应?下次看到类似状态,你能不能预判会发生什么?”
这就是标题里所谓 Learn World Models for Free 的含义:不是额外训练一个 world model,不是额外采样环境,不是加一个 teacher 或 judge,而是把 rollout 里已经存在的环境返回文本直接拿来做 next-token prediction。
#1. 这篇论文想解决什么问题?
#1.1 Agent RL 的根本痛点:奖励太稀疏
Terminal agent 的交互形式很像具身智能:
- 模型观察当前任务和历史 transcript;
- 输出 bash command / edit / run tests;
- 终端执行命令;
- 返回 stdout、stderr、exit code、文件内容、日志、traceback;
- 模型根据返回结果继续下一步。
但是在训练时,很多 RL 方法只看最终 verifier:
- 任务通过:reward = 1;
- 任务失败:reward = 0。
论文提到,在他们的 Qwen3-8B setting 里,on-policy rollouts 常常只有不到 15% 能成功。这意味着大多数 rollout 在 GRPO 下提供的 policy-gradient 信号非常有限。
问题是:失败轨迹真的没有信息吗?显然不是。
一个失败轨迹里可能包含:
ModuleNotFoundError告诉模型依赖没装;AssertionError告诉模型输出格式不对;ls的结果告诉模型文件结构;cat config.yaml暴露了配置;pytest的失败日志暴露了具体测试期望;grep的结果告诉模型函数定义在哪。
这些信息不是“噪声”,而是环境对动作的真实反馈。
#1.2 传统 GRPO 丢掉了什么?
标准 GRPO 的训练序列大概是:
[system] [task]
[action_1] [obs_1]
[action_2] [obs_2]
...
[action_K] [obs_K]
模型当然会把 obs_i 当作上下文,因为后续 action 要基于之前的 terminal output。但在 loss 上,GRPO 通常只优化 action token:
loss applied to: action_1, action_2, ..., action_K
not applied to: obs_1, obs_2, ..., obs_K
也就是说,环境返回进入了 forward computation,但没有进入训练目标。
ECHO 的判断是:这浪费了 terminal agent 最丰富的监督源。
#2. ECHO 的核心方法:把 observation token 也作为训练目标
ECHO 全称是:Environment Cross-entropy Hybrid Objective。
它做的事情可以用一个公式概括:
L_ECHO = L_GRPO(action tokens) + λ L_Env(observation tokens)
其中:
L_GRPO:标准 GRPO,在模型 action tokens 上做 policy-gradient;L_Env:在环境 observation tokens 上做 next-token cross entropy;λ:控制 observation prediction loss 的权重,论文主实验使用λ = 0.05。
#2.1 什么是 observation prediction?
假设模型执行:
pytest tests/test_data.py
终端返回:
FAILED tests/test_data.py::test_parse_date - AssertionError: expected yyyy-mm-dd
传统 agent RL:
- 把这段输出放进 context;
- 下一步 action 可以利用它;
- 但训练 loss 不要求模型预测它。
ECHO:
- 仍然把它放进 context;
- 但同时把这段 terminal output 的 tokens 作为监督目标;
- 要求模型在给定历史和命令的情况下,预测环境会返回这些 tokens。
这逼迫模型学一个隐式模型:
当前容器状态 + 我执行的命令 → 终端可能返回什么
这就是 “world model”。当然,它不是完整世界模型,只是 terminal environment 的 textual projection:stdout、stderr、文件内容、日志、exit code 等。但对于 terminal agent 来说,这已经是非常关键的世界状态投影。
#2.2 为什么说是 “for free”?
因为 ECHO 不需要:
- 额外 rollout;
- 额外 teacher;
- 额外 verifier;
- 额外 world model 网络;
- 额外 forward pass;
- 离线 demonstration corpus。
它复用同一个 rollout、同一个 actor forward pass、同一批 logits,只是换了一个 mask:
- action mask:用于 GRPO;
- observation mask:用于 environment cross entropy。
论文里的 Algorithm 1 本质就是:
1. 对完整 rollout 做一次 forward;
2. 在 action token 上算 GRPO loss;
3. 在 observation token 上算 CE loss;
4. 两者加权求和。
所以它不是引入一个复杂系统,而是把原本被 mask 掉的 token 重新纳入训练。
#3. 为什么预测 terminal output 会提升 agent?
这篇论文最值得琢磨的地方,不是 “加一个辅助 loss” 这个形式,而是它背后的机制假设。
作者借用了语言模型里的一个经典直觉:
good prediction implies good understanding.
如果模型能准确预测下一个 token,它就必须学到生成这个 token 背后的某些结构。对应到 terminal agent:
如果模型能预测一条命令会产生什么终端输出,它就必须跟踪这条命令对环境状态的影响。
例如:
- 如果它预测
ls的输出,就要知道当前目录里有什么; - 如果它预测
pytest的错误,就要知道代码实现和测试期望之间的差异; - 如果它预测
cat file的内容,就要记住之前是否创建/修改过这个文件; - 如果它预测
python script.py的 traceback,就要理解程序执行路径和异常原因。
这不是单纯背诵文本,而是在训练模型形成一种“状态追踪能力”:
我做了什么 → 环境状态如何变化 → 下一次观察会暴露什么
这种能力对 agent 的下一步决策很有帮助。因为 terminal agent 的强弱,很大程度上取决于它能否回答:
- 我现在应该 inspect 哪个文件?
- 跑测试会暴露什么信息?
- 这个错误说明我该改哪里?
- 继续探索还是直接修?
- 当前状态是不是已经接近完成?
ECHO 不是直接教模型“该做什么动作”,而是让模型更懂“动作会造成什么后果”。这和 model-based RL / world model 的思想非常接近。
#4. 实验设置:它到底怎么训?
#4.1 训练任务
论文从 2700 个 curated terminal tasks 开始:
- 1977 来自 Endless Terminals;
- 723 来自 OpenThoughts-Agent-v1-RL。
之后又用修改版 Endless Terminals pipeline 生成 6170 个额外任务。最终保留 GPT-5 在 16 次尝试中至少能解出一次的任务,得到 8870 个任务,覆盖:
- data processing;
- system operations;
- development/tooling。
其中:
- 8770 个用于训练;
- 100 个作为 in-distribution validation,即 val100。
#4.2 交互环境
每一轮:
- policy 根据历史输出 thinking block 和 Qwen XML-format bash command;
- harness 解析第一条命令或 task-done signal;
- 在 Docker 中执行;
- 返回 format warning、stdout、stderr、exit code;
- 最多 16 turns。
训练时:
- context window:16k;
- 每轮最多生成 2048 tokens;
- 训练任务 verifier timeout:10 分钟 agent + 2 分钟 verifier。
#4.3 模型和对照
论文训练三个 starting policies:
- Qwen3-8B base;
- OpenThinker-Agent-v1-SFT / OT-SFT:Qwen3-8B 经约 15k expert demonstrations SFT;
- Qwen3-14B base。
对照方式很清晰:
Base → GRPO
Base → ECHO = GRPO + env CE
这样可以隔离唯一变化:是否额外对 terminal output tokens 做 cross entropy。
#4.4 评测集
论文用多个评测:
- val100:训练分布 held-out 100 tasks;
- ITD:internal-dev,71 tasks,偏 data processing / systems / tooling;
- TBLite:100 个 terminal-bench-style tasks;
- TerminalBench-2.0 / TB2:89 tasks,用 Terminus 2 harness,32k context。
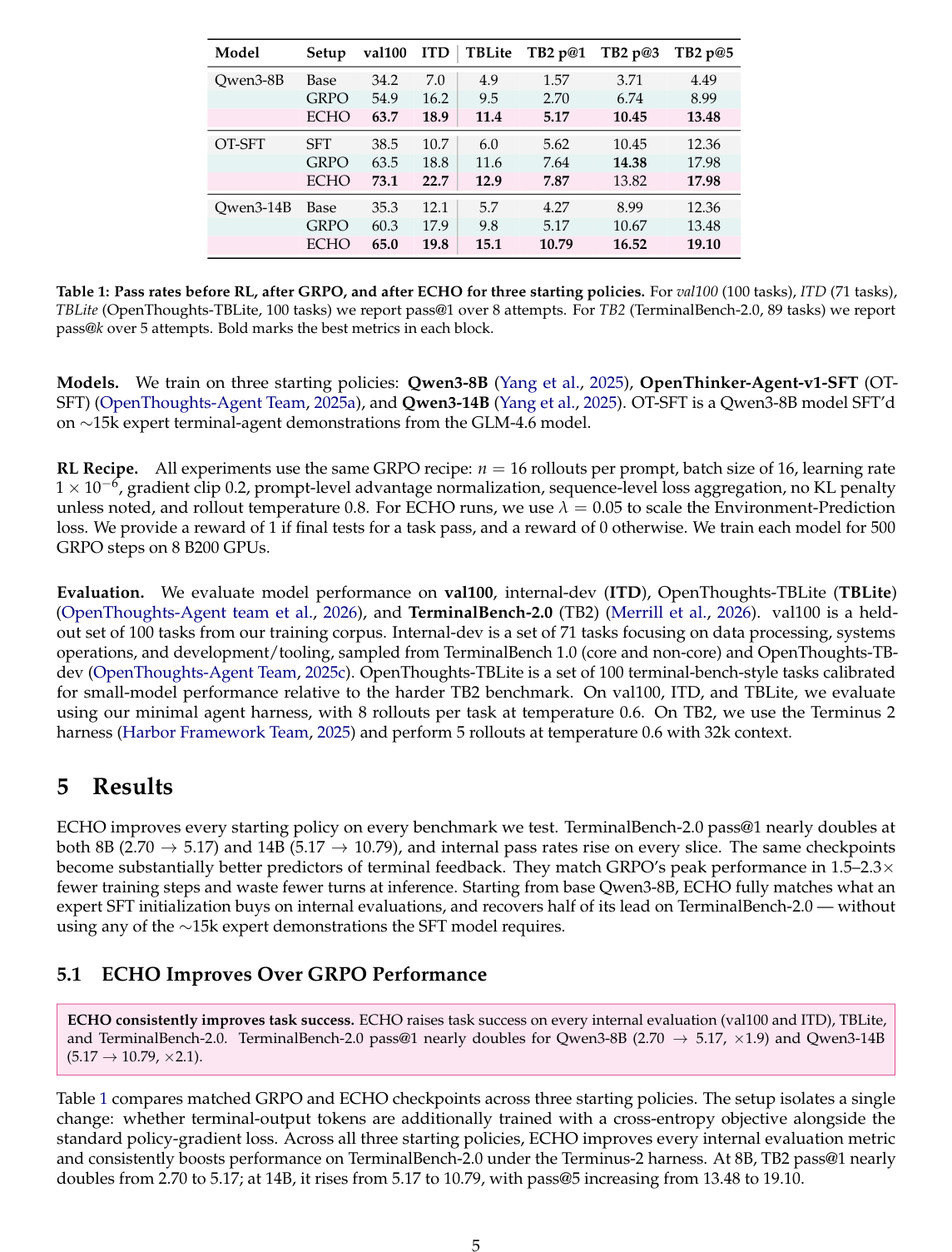
#5. 主结果:ECHO 显著优于 GRPO
论文最重要的 Table 1 给出 pass rate:
| 模型 | 设置 | val100 | ITD | TBLite | TB2 pass@1 | TB2 pass@3 | TB2 pass@5 |
|---|---|---|---|---|---|---|---|
| Qwen3-8B | Base | 34.2 | 7.0 | 4.9 | 1.57 | 3.71 | 4.49 |
| Qwen3-8B | GRPO | 54.9 | 16.2 | 9.5 | 2.70 | 6.74 | 8.99 |
| Qwen3-8B | ECHO | 63.7 | 18.9 | 11.4 | 5.17 | 10.45 | 13.48 |
| OT-SFT | SFT | 38.5 | 10.7 | 6.0 | 5.62 | 10.45 | 12.36 |
| OT-SFT | GRPO | 63.5 | 18.8 | 11.6 | 7.64 | 14.38 | 17.98 |
| OT-SFT | ECHO | 73.1 | 22.7 | 12.9 | 7.87 | 13.82 | 17.98 |
| Qwen3-14B | Base | 35.3 | 12.1 | 5.7 | 4.27 | 8.99 | 12.36 |
| Qwen3-14B | GRPO | 60.3 | 17.9 | 9.8 | 5.17 | 10.67 | 13.48 |
| Qwen3-14B | ECHO | 65.0 | 19.8 | 15.1 | 10.79 | 16.52 | 19.10 |
最关键的数字:
- Qwen3-8B 在 TerminalBench-2.0 上:2.70 → 5.17,约 1.9x;
- Qwen3-14B 在 TerminalBench-2.0 上:5.17 → 10.79,约 2.1x;
- val100、ITD、TBLite 上也全部提升。
这说明 ECHO 不只是提升 in-distribution 任务,也对 OOD terminal tasks 有帮助。
#6. ECHO 真的学到了 terminal dynamics 吗?
这是论文最关键的机制验证。
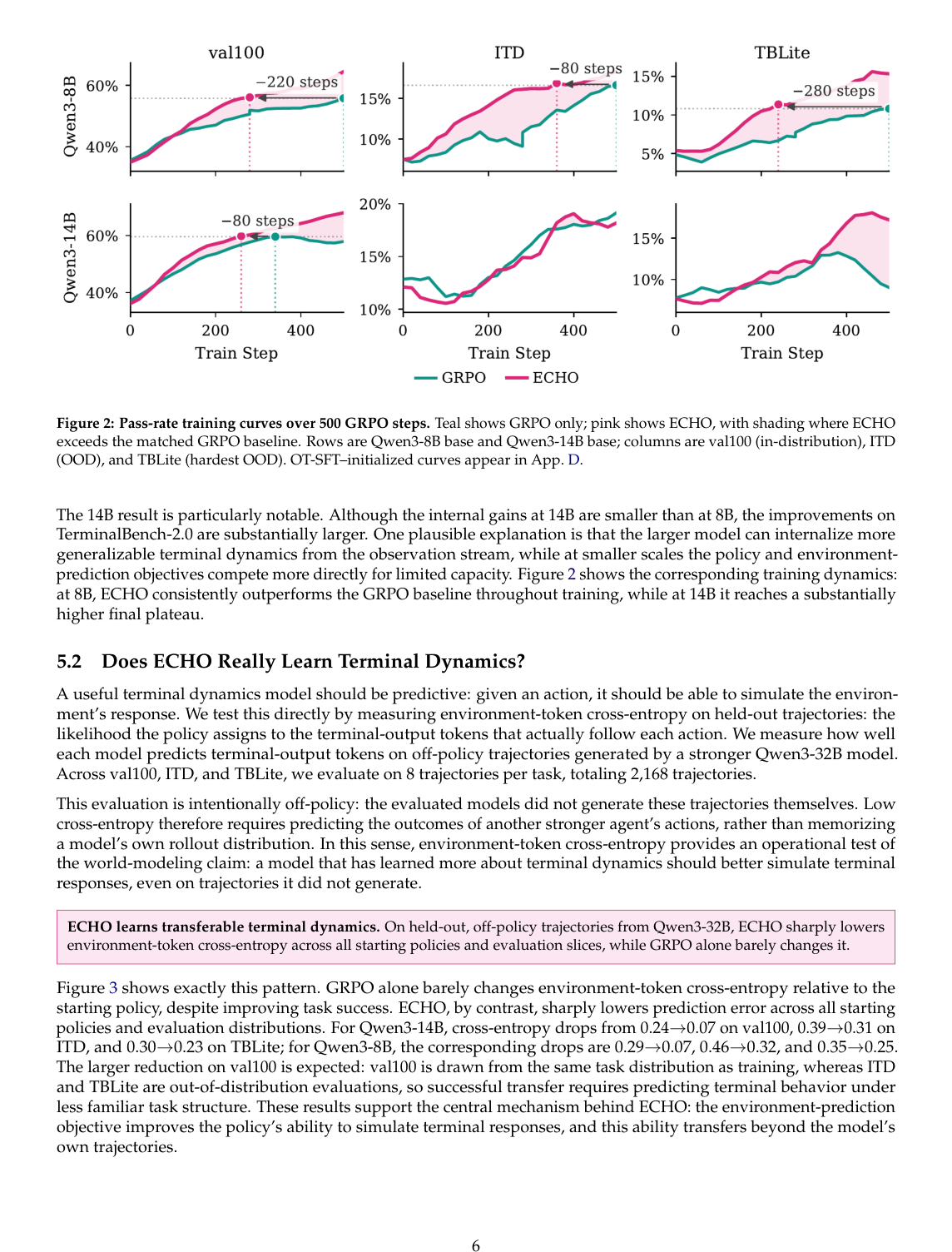
如果 ECHO 只是一个 regularizer,那么它提升 pass rate 可能只是偶然。但作者进一步测试:模型是否真的更会预测 terminal output?
他们用一个更强的 Qwen3-32B 生成 held-out trajectories,然后让不同模型去预测这些轨迹里的 terminal-output tokens,计算 per-token cross entropy。
注意这个评测是 off-policy 的:
- 被评测模型没有生成这些轨迹;
- 轨迹来自更强的 Qwen3-32B;
- 所以模型不能只记住“自己通常会走到什么状态”;
- 它必须预测另一个 agent 的动作造成的 terminal response。
结果:
- GRPO 虽然提高任务成功率,但几乎不降低 environment-token CE;
- ECHO 显著降低 environment-token CE。
论文给出的例子:
- Qwen3-14B:val100 CE 从 0.24 → 0.07;ITD 从 0.39 → 0.31;TBLite 从 0.30 → 0.23;
- Qwen3-8B:val100 从 0.29 → 0.07;ITD 从 0.46 → 0.32;TBLite 从 0.35 → 0.25。
这支持了论文标题里的 world model claim:ECHO 确实让模型更能预测环境动态。
#7. ECHO 和 expert SFT 的关系:它替代了什么,又没替代什么?
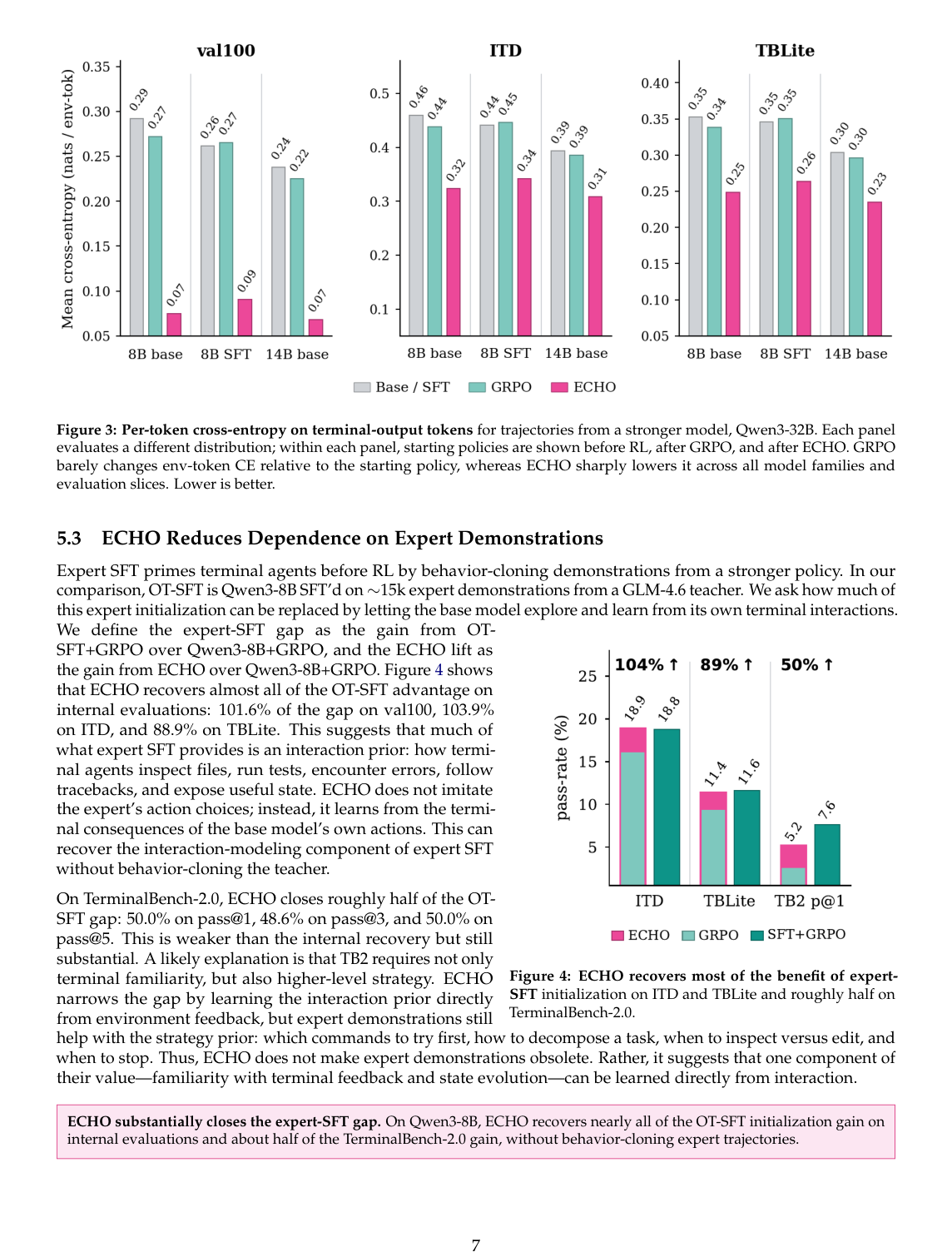
这篇论文另一个很有意思的问题是:expert SFT 到底给 terminal agent 带来了什么?
OT-SFT 是 Qwen3-8B 经过约 15k 条 expert demonstrations SFT 得到的 agent。传统理解里,expert SFT 教模型:
- 如何分解任务;
- 如何 inspect 文件;
- 如何运行测试;
- 如何根据错误修复;
- 如何停止。
ECHO 问的是:其中有多少能力,其实可以不靠 expert demos,而靠模型自己探索环境、预测环境反馈学到?
论文定义:
expert-SFT gap = OT-SFT + GRPO 相对 Qwen3-8B + GRPO 的提升
ECHO lift = Qwen3-8B + ECHO 相对 Qwen3-8B + GRPO 的提升
结果:
- val100:ECHO 恢复了 101.6% 的 expert-SFT gap;
- ITD:恢复 103.9%;
- TBLite:恢复 88.9%;
- TerminalBench-2.0:pass@1 / pass@3 / pass@5 上大约恢复一半。
这说明 expert SFT 的一部分价值是 interaction prior:熟悉终端反馈、状态演化、错误暴露方式。ECHO 可以从自交互中学到这部分。
但论文也很诚实地指出:TB2 上 ECHO 只恢复约一半,说明 expert demos 仍然提供更高层的 strategy prior:
- 一开始该试什么命令;
- 如何分解任务;
- 什么时候 inspect;
- 什么时候 edit;
- 什么时候 run tests;
- 什么时候 stop。
所以 ECHO 不是让 expert demonstrations 过时,而是把 expert SFT 中一部分“环境熟悉度”的价值转移到了自监督环境预测上。
#8. 训练和推理效率:不只是分数更高,也更少浪费交互
ECHO 的直觉是:同一条 rollout 里利用了更多监督,因此 sample efficiency 应该更好。
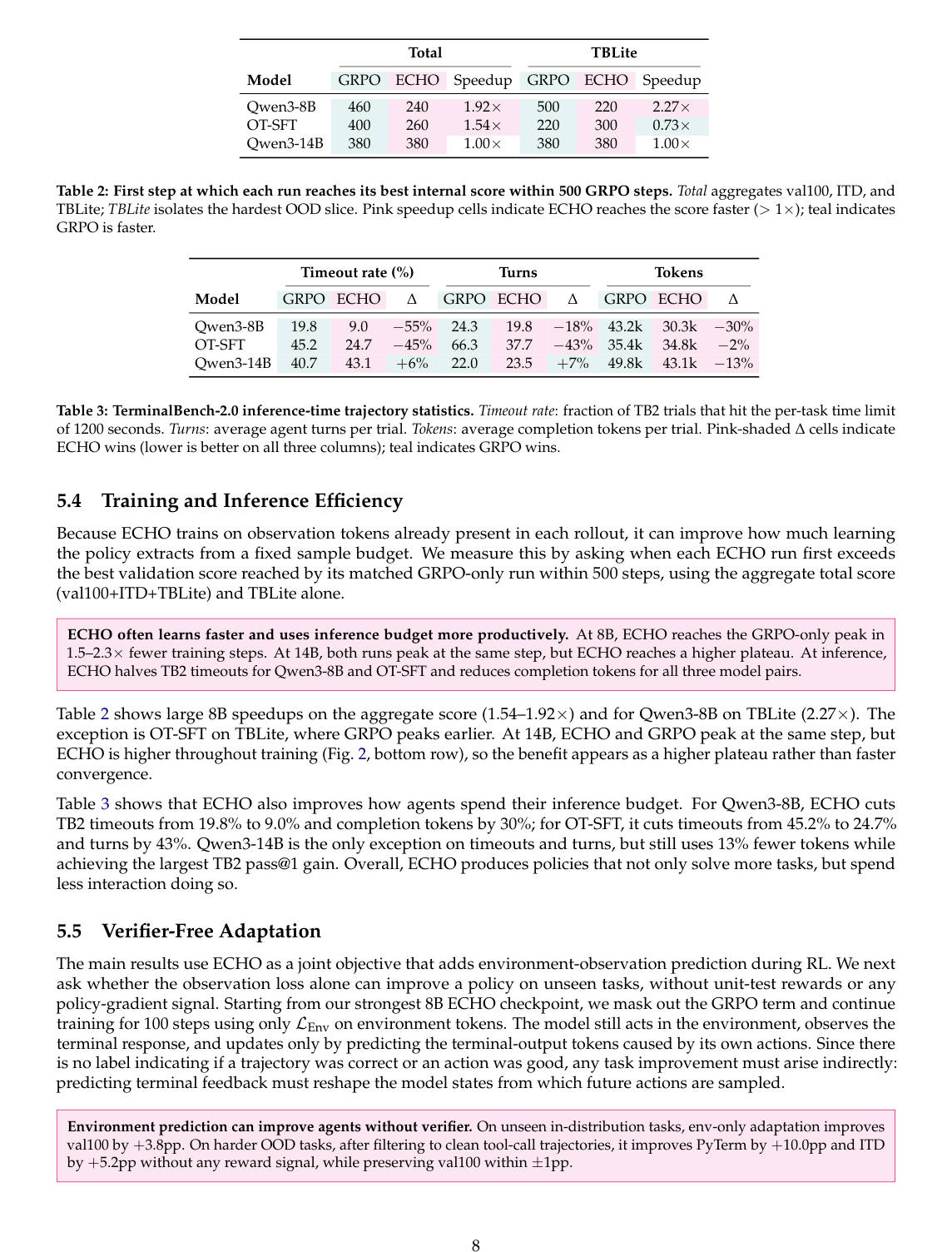
论文 Table 2 看“在 500 个 GRPO steps 内,ECHO 多快达到 matched GRPO 的最佳内部分数”:
| 模型 | Total GRPO | Total ECHO | speedup | TBLite GRPO | TBLite ECHO | speedup |
|---|---|---|---|---|---|---|
| Qwen3-8B | 460 | 240 | 1.92x | 500 | 220 | 2.27x |
| OT-SFT | 400 | 260 | 1.54x | 220 | 300 | 0.73x |
| Qwen3-14B | 380 | 380 | 1.00x | 380 | 380 | 1.00x |
大体结论:8B 上 ECHO 明显更快;14B 上不是更快达到 peak,而是全程 plateau 更高。
更有意思的是 inference-time behavior。Table 3 统计 TB2 上 timeout、turns、tokens:
| 模型 | timeout GRPO | timeout ECHO | 变化 | turns GRPO | turns ECHO | 变化 | tokens GRPO | tokens ECHO | 变化 |
|---|---|---|---|---|---|---|---|---|---|
| Qwen3-8B | 19.8 | 9.0 | -55% | 24.3 | 19.8 | -18% | 43.2k | 30.3k | -30% |
| OT-SFT | 45.2 | 24.7 | -45% | 66.3 | 37.7 | -43% | 35.4k | 34.8k | -2% |
| Qwen3-14B | 40.7 | 43.1 | +6% | 22.0 | 23.5 | +7% | 49.8k | 43.1k | -13% |
这说明 ECHO 不只是多解了任务,还常常减少无效交互:少 timeout、少 turns、少 tokens。
直观解释是:如果模型更能预测环境反馈,它就更少做“没意义的试探”。
#9. 最有启发的实验:没有 verifier,只靠预测环境反馈也能变强
论文第 5.5 节很有意思:作者关掉 verifier,不使用任务 reward,不做 action-token policy-gradient,只继续训练 environment prediction loss。
也就是:
L_total = L_Env
不用 L_GRPO
不用 reward
不用 verifier
模型仍然和环境交互,但训练目标只是:预测终端返回。
如果性能还能提升,就说明“预测环境反馈”本身确实能 reshape model state,从而间接改善 action generation。
结果:
| Target distribution | rollout filter | step | target 提升 | val100 变化 |
|---|---|---|---|---|
| val100 | none | 70 | +3.8 pp | +3.8 pp |
| PyTerm OOD | clean tool calls | 100 | +10.0 pp | -0.9 pp |
| ITD OOD | clean tool calls | 100 | +5.2 pp | +0.4 pp |
| TBLite OOD | clean tool calls | 100 | -3.9 pp | -0.4 pp |
这个结果非常重要,但也要谨慎解读。
它说明:在一些环境中,只靠 prediction loss 也能 self-improve,尤其当反馈是 dense、action-linked 的时候,比如 PyTerm 中 Python 程序会产生 traceback、print、文件内容,这些都直接指向下一步应该改什么。
但它不是万能的。TBLite 上下降,作者推测原因是 TBLite 需要更复杂的 shell orchestration,观察 token 和正确 action 的联系不那么直接。此时 environment loss 容易变成“学习失败模式”:模型很会预测 parse error / malformed tool call 的输出,但这不代表它更会解决任务。
#10. ECHO 和 model-based RL / world model 的关系
这篇论文对你关心的 LLM model-based RL / Dreamer for LLM Agent 很有启发。
经典 world model 通常是:
learn dynamics model: state + action → next state
use it for planning / imagination / policy learning
ECHO 不显式训练一个 separate dynamics model,也不在 inference-time 做 imagination rollout。它更像是:
把 policy 本身训练成“更懂环境后果”的模型
也就是说,它不是 model-based RL 的完整版本,但它在做一件基础的事:
把环境 transition signal 从稀疏 reward 旁边捡起来,变成 token-level predictive supervision。
在 terminal agent 中,状态并不是视觉图像,而是文本 transcript;动作不是电机控制,而是 shell command;next state 的可观察投影就是 terminal output。因此 next-observation prediction 很自然就能写成语言模型的 cross entropy。
这可能是 LLM Agent 里的一个重要方向:
不一定先造一个外部 world model,先让 policy 学会预测自己动作的可观察后果。
它和 Dreamer-style model-based RL 的差别:
| 维度 | Dreamer-style world model | ECHO |
|---|---|---|
| 模型结构 | 通常有显式 dynamics / latent state model | 无额外模型,复用 policy LM |
| 训练目标 | 预测 latent / reward / continuation / observation | 预测 terminal observation tokens |
| 是否用于 imagination planning | 是,核心机制 | 否,主要是 representation shaping |
| 是否额外 rollout | 通常可在 latent 中 imagination | 不额外 rollout |
| 适用场景 | 连续控制、视觉、通用 RL | 文本化 terminal agent |
所以 ECHO 更像是一个轻量级、工程上立即可用的 “world-model regularization”。它没有解决长轨迹 planning,但证明了:agent 轨迹里的 observation token 本身是很强的自监督信号。
#11. 和其他相关方向的关系
论文 Related Work 中提到几个邻近方向:
#11.1 CWM
CWM 训练大模型学习 observation-action trajectories,用于 code generation with world models。ECHO 和它的区别在于:
- CWM 更像单独的数据/模型训练阶段;
- ECHO 直接嵌入 on-policy GRPO;
- ECHO 不需要 separate corpus、world-modeling stage、inference-time simulation。
#11.2 RLTF / OpenClaw-RL
这些工作也关注“环境反馈中有被丢掉的监督”。区别是:
- RLTF 预测 judge-generated critiques;
- OpenClaw-RL 通过 judge 抽取 hints 或 process rewards;
- ECHO 直接预测 raw environment observation tokens,不需要 judge、critique、distillation。
这点非常关键:ECHO 的监督来自环境 literal response,而不是人或模型解释过的反馈。
#11.3 多轮 Agent RL 稳定化方法
例如 SkyRL、SimpleTIR、DAPO、ArCHer 等,很多工作关注如何稳定 policy-gradient 更新、过滤坏轨迹、处理 overlong、clip 等问题。
ECHO 与这些方法正交:它不是替代 RL 稳定技术,而是在 RL loss 旁边多加一个 observation CE loss。
#12. 局限和需要警惕的地方
#12.1 分数绝对值仍然不高
虽然 ECHO 让 TB2 pass@1 翻倍,但 Qwen3-14B ECHO 也只有 10.79。这说明 terminal agent 仍处于很早期阶段。ECHO 提高 sample efficiency,但没有解决高层任务规划、复杂 debug、长程搜索等问题。
#12.2 预测环境不等于知道最优动作
ECHO 学的是:
如果我执行这个动作,环境可能怎么回应
但它不直接告诉模型:
哪个动作最优
因此它更像补足 interaction/world-model prior,而不是完整策略学习。
#12.3 可能学习失败模式
env-only adaptation 的 TBLite 失败说明:如果 rollout 质量差、工具调用 malformed、反馈和任务成功联系弱,那么 environment prediction 可能强化失败轨迹的模式。
所以 ECHO 可能需要搭配:
- clean trajectory filtering;
- void trajectory filtering;
- tool-call validity filtering;
- curriculum;
- λ schedule;
- observation subset selection。
#12.4 Observation token 很长,loss 权重需要小心
论文发现 λ 合适范围大概是 0.01–0.05,主实验用 0.05。太小没有 representation shaping,太大则 observation objective 会和 policy objective 竞争,甚至可能坍缩到“产生容易预测但无用的 terminal outputs”。
这提醒我们:不是 observation loss 越大越好。
#13. 对 LLM Agent 研究的启发
我觉得这篇论文对 Agent RL 有几条很重要的启发。
#13.1 失败轨迹不应该只被当作失败
在长轨迹 agent 任务里,失败是常态。如果只用最终 reward,失败轨迹基本浪费掉。但失败轨迹包含大量环境结构:错误、日志、状态、反例、测试反馈。
ECHO 给出了一种非常直接的利用方式:把它们作为 next-observation prediction targets。
这和你一直关注的长轨迹 RL 可持续性很相关:长轨迹越长,稀疏 reward 越难;但长轨迹也意味着 observation tokens 越多,自监督信号越丰富。
#13.2 Agent 预训练数据不只是 demonstrations,也可以是 interaction consequences
传统 agent SFT 依赖 expert demos:看专家如何操作。但 ECHO 表明,模型自己探索产生的 trajectories 即便失败,也可以通过预测环境后果获得价值。
这可能指向一种新的 agent pretraining / continual pretraining 形式:
大量自交互轨迹 + observation prediction + 少量 RL reward
比单纯 imitation 更接近“通过行动理解环境”。
#13.3 World model 可以从 textual environment feedback 中自然长出来
在 terminal / browser / code agent 中,环境反馈天然是文本化的:网页 DOM、terminal stdout、compiler error、unit test logs、API response。
这意味着 LLM 不一定需要复杂的视觉 world model,就能先学一种 textual world model。
可能的扩展包括:
- browser agent 预测 DOM diff / page response;
- code agent 预测 test failure / compile error;
- tool agent 预测 API response schema;
- research agent 预测 search result snippets;
- multi-agent system 预测其他 agent 的 reply / critique。
#13.4 这可能是 model-based RL for LLM agents 的低成本入口
真正的 Dreamer-style LLM Agent 可能需要 latent dynamics、planning、imagined rollouts。但 ECHO 提醒我们,第一步可以很朴素:
在真实 rollout 中学习 action → observation 的预测。
如果这一步学好了,下一步才可能做:
- imagined terminal rollouts;
- action proposal reranking by predicted outcome;
- uncertainty-aware exploration;
- latent-state compression;
- learned simulators for code environments。
#14. 我的判断
这篇论文的贡献不在于提出了一个复杂算法,而在于抓住了一个非常基础但长期被忽略的事实:
agent rollout 中的 observation 不是训练时的“上下文废料”,而是环境对动作的可观察后果,是天然的 dense supervision。
从工程角度,它很有吸引力:
- 实现简单;
- 不增加 rollout;
- 不增加 forward pass;
- 不需要 teacher;
- 能和 GRPO 以及其他稳定化技巧组合;
- 对失败轨迹友好。
从研究角度,它指向一个更大的问题:
LLM Agent 的能力形成,可能不只来自“哪些 action 得到奖励”,还来自“模型是否理解 action 如何改变世界”。
这正好连接到 model-based RL、latent-space reasoning、agent continual pretraining、self-evolving code agent 这些方向。
如果后续继续推进,我觉得最值得研究的是:
- observation loss 应该预测哪些 token? stdout 全部预测,还是只预测 error / diff / test output / file content?
- 如何避免学习失败模式? clean filtering、uncertainty、reward-conditioned prediction 是否有用?
- 能不能把 prediction 用到 inference-time planning? 不只是训练时 shaping,而是让模型在行动前模拟 terminal response。
- 能不能学习 latent world model,而不是 raw token prediction? raw CE 很直接,但可能浪费在格式和低级 token 上。
- 能否跨环境迁移? terminal dynamics 学到的东西能否迁移到 browser、IDE、repo-level software engineering?
总结起来:
ECHO 是一个小改动,但抓住了 Agent RL 的一个大缺口:环境反馈本身就是监督。对于 terminal/code agent,这可能是从 model-free sparse reward 走向 world-model-aware agent training 的一个非常自然的起点。